視覚的分離拡散オートエンコーダ:基盤モデルのためのスケーラブルな反事実生成
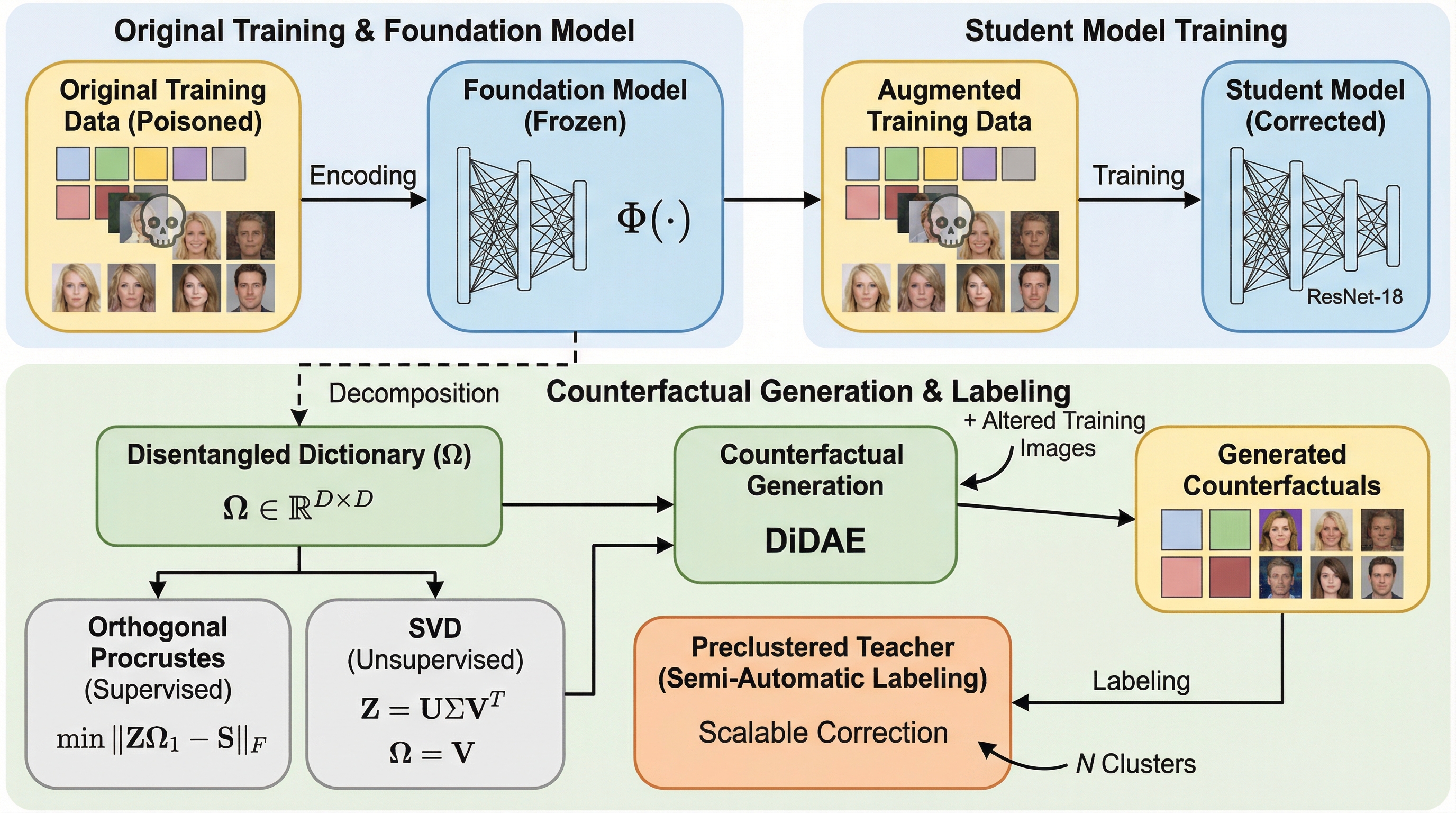
基盤モデルが「賢いハンス」現象や偽の相関に依存する問題を解決するため、視覚的分離拡散オートエンコーダ(DiDAE)が提案されました。この手法は、凍結された基盤モデルの潜在空間を分離辞書学習によって解釈可能な方向に分解し、勾配計算を必要としない高速かつ精密な反事実的画像の生成を可能にします。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
基盤モデルが「賢いハンス」現象や偽の相関に依存する問題を解決するため、視覚的分離拡散オートエンコーダ(DiDAE)が提案されました。この手法は、凍結された基盤モデルの潜在空間を分離辞書学習によって解釈可能な方向に分解し、勾配計算を必要としない高速かつ精密な反事実的画像の生成を可能にします。
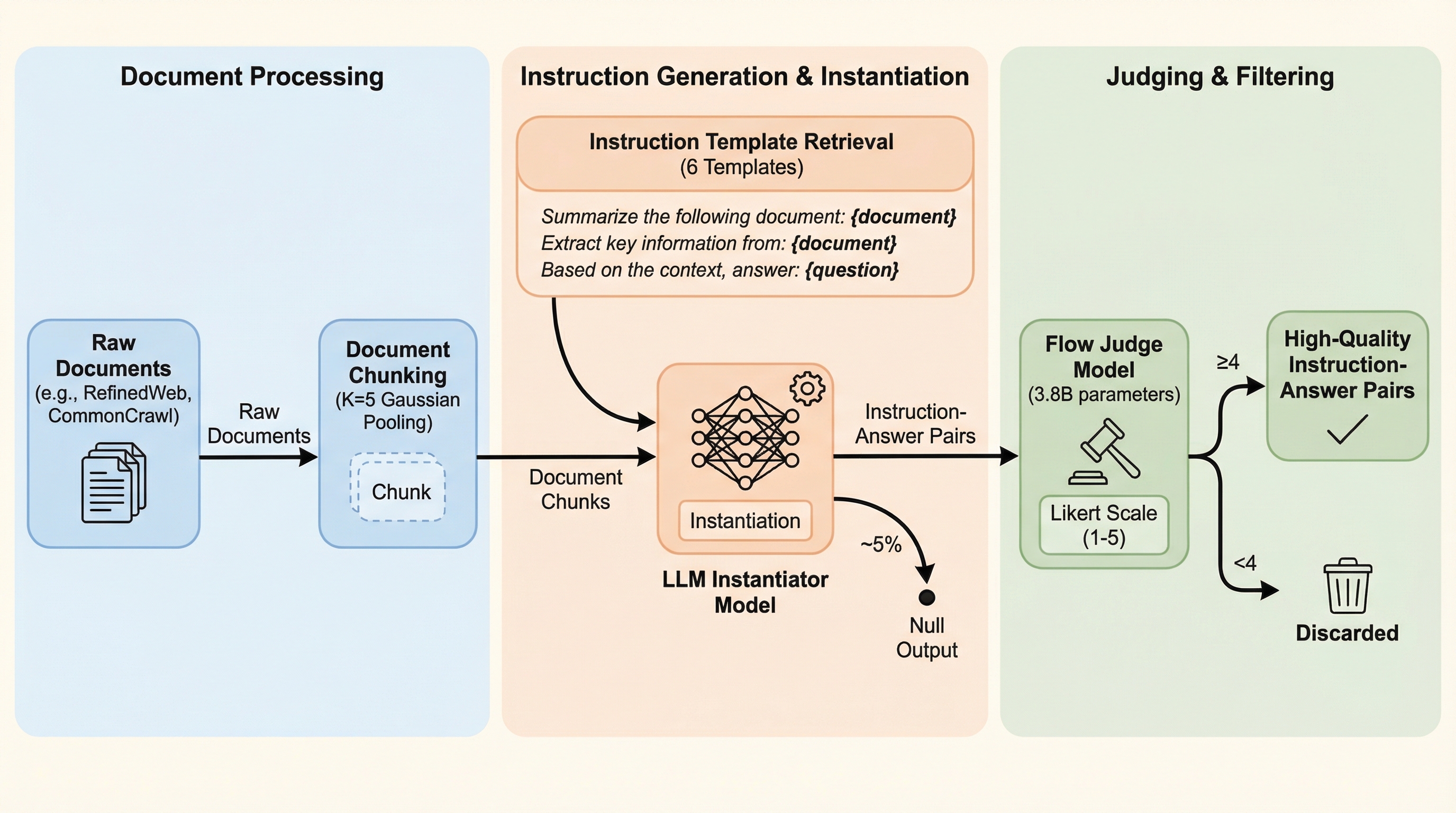
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。
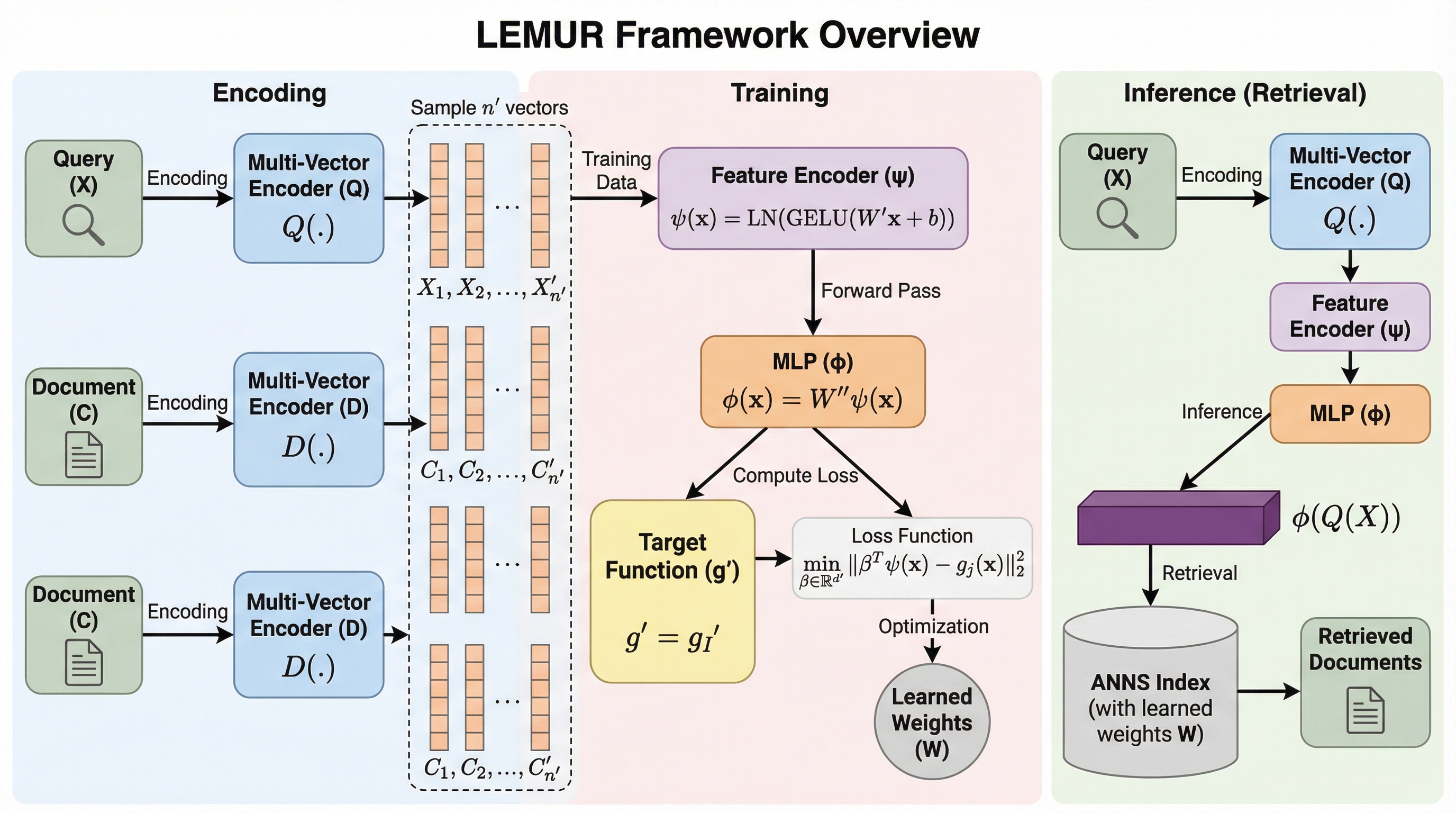
情報検索において高い精度を誇るColBERTなどのマルチベクトルモデルは、MaxSim計算の複雑さゆえに検索遅延が非常に大きいという課題を抱えていました。本研究で提案されたLEMURは、このマルチベクトル検索を教師あり学習による回帰問題として再定義し、最終的に潜在空間上の単一ベクトルによる近似近傍探索へと変換することで、既存の高速な検索ライブラリの活用を可能にしました。 検証の結果、LEMURは従来のマルチベクトル検索手法と比較して1桁(約10倍)以上の高速化を達成しており、最新のテキスト検索モデルや視覚的な文書検索モデルにおいても、高い再現率を維持しながら劇的なパフォーマンス向上を実現することが確認されました。 このフレームワークは、軽量なニューラルネットワークを用いてトークン単位の埋め込みを潜在空間上の単一ベクトルへと集約し、ドキュメントの重み行列との内積計算によって類似度を推定する仕組みを採用しており、大規模なコーパスに対しても効率的なインデックス作成と高速な検索を両立させています。
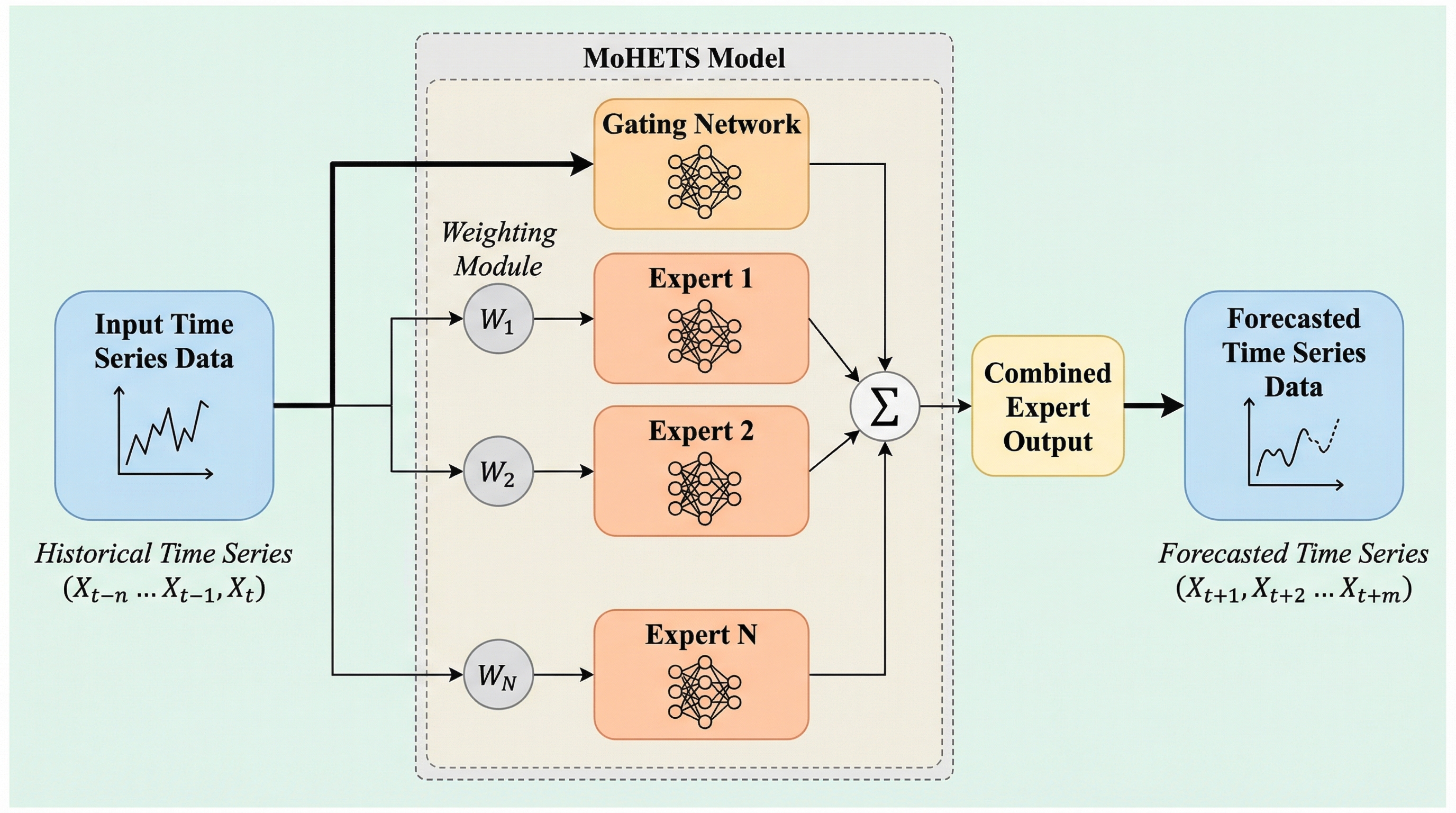
MoHETSは、多変量時系列データの複雑な多スケール構造を捉えるために、構造の異なる専門家ネットワークを組み合わせた「異種混合エキスパート(MoHE)」を導入したエンコーダーのみのTransformerモデルである。
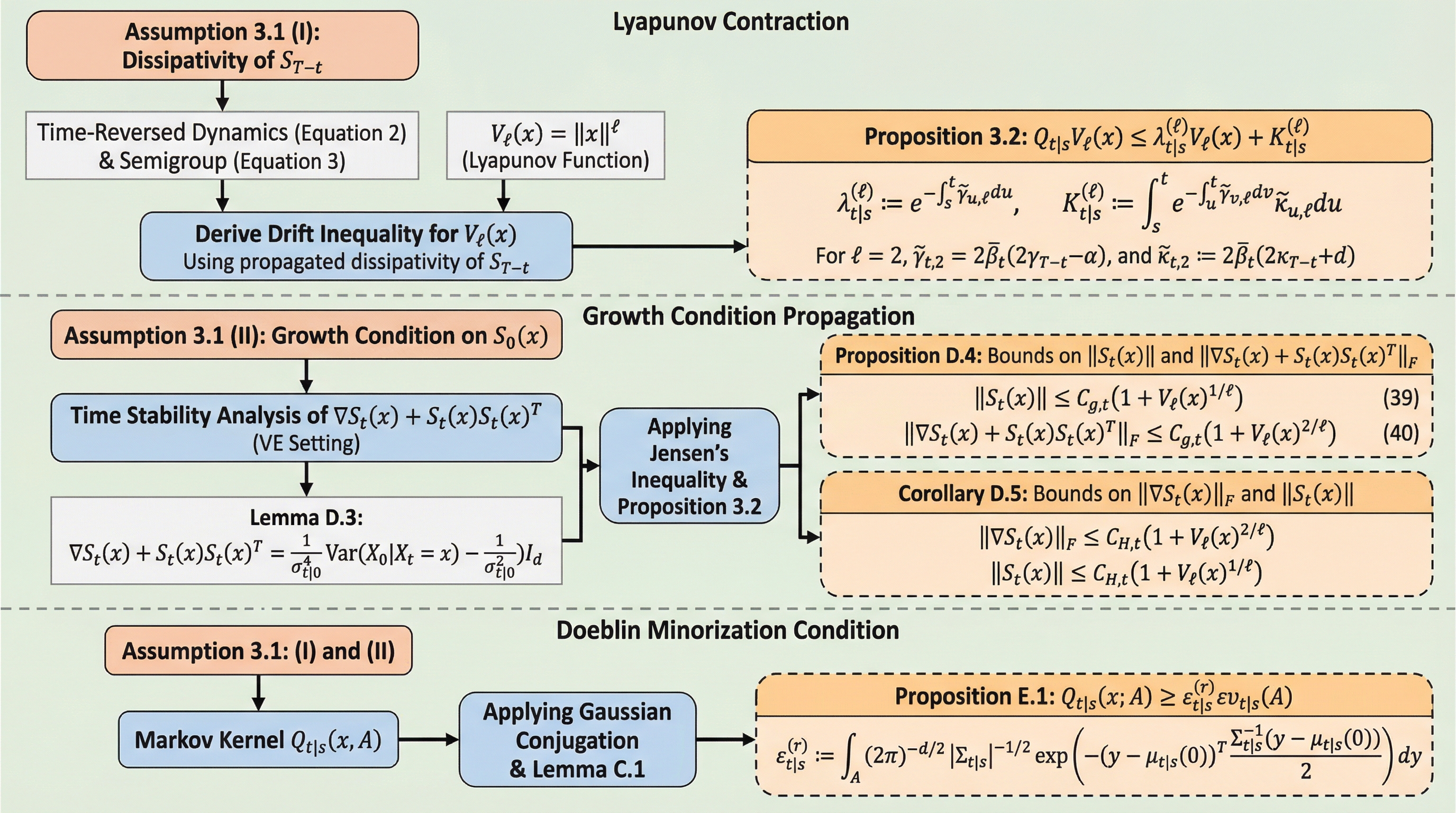
スコアベース生成モデル(SGM)のサンプリング過程における安定性と長期的な挙動を、逆時間ダイナミクスに関連するマルコフ連鎖の「忘却性」という観点から理論的に解明しました。具体的には、ハリスの安定性理論に基づき、リアプノフ・ドリフト条件とデブリン型のマイノリゼーション条件という2つの構造的特性を用いることで、初期化誤差や離散化誤差がサンプリングの軌道に沿ってどのように伝播するかを定量的に制限する枠組みを提案しています。この研究の結果、逆拡散ダイナミクスがサンプリング軌道に沿って収縮メカニズムを誘発することが示され、強凸性などの厳しい仮定を置かずに、非凸でマルチモーダルなデータ分布に対してもサンプリング手順の定量的な安定性を保証することが可能になりました。
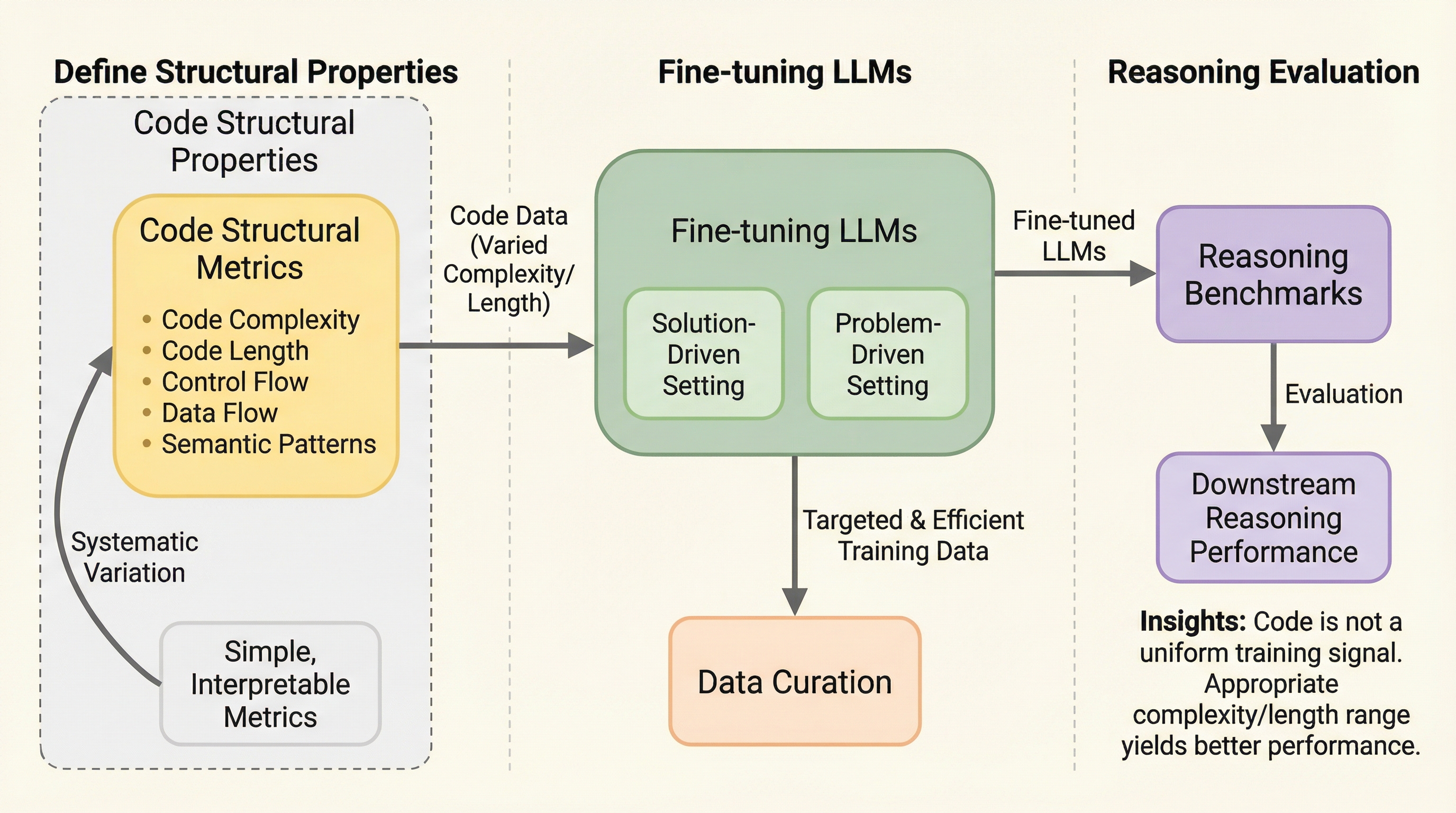
大規模言語モデル(LLM)の推論能力を向上させるためには、学習に用いるコードの「構造的複雑さ」を適切に制御することが極めて重要であり、単にデータの量や多様性を増やすだけでは不十分であることが明らかになりました。
オンライン強化学習において、関連するソースタスクの経験をターゲットタスクに転移させることは、学習を加速させるための自然なアプローチである。しかし、従来のタスク類似性の定義は報酬や遷移のレベルに留まっており、オンライン学習アルゴリズムが実際に操作するベルマン回帰ターゲットとの間に乖離があるため、単純なデータ統合では系統的なバイアスが生じ、探索の理論的保証が損なわれるという構造的な課題があった。本研究では、この問題を解決するために、演算子レベルでベルマンアライメントを行う「再重み付けターゲット(RWT)」を提案し、タスク間の不一致を継続価値に依存しない固定の一段階補正へと変換する手法を確立した。このアライメントに基づく二段階のQ学習フレームワークは、RKHS関数近似の設定において、リグレット界がターゲットタスク全体の複雑さではなくタスク間のシフトの複雑さに依存することを理論的に証明し、シミュレーションおよびニューラルネットワークを用いた実験の両方で、単一タスク学習やナイーブなデータ統合を上回る一貫した性能向上を実証している。
学習データ属性特定(TDA)は、モデルの予測に影響を与えた訓練データを特定する重要な技術ですが、大規模モデルでは膨大な勾配データの保存に伴うI/O負荷と、ヘッセ行列近似に必要なメモリ消費が実用化の大きな障壁となっていました。
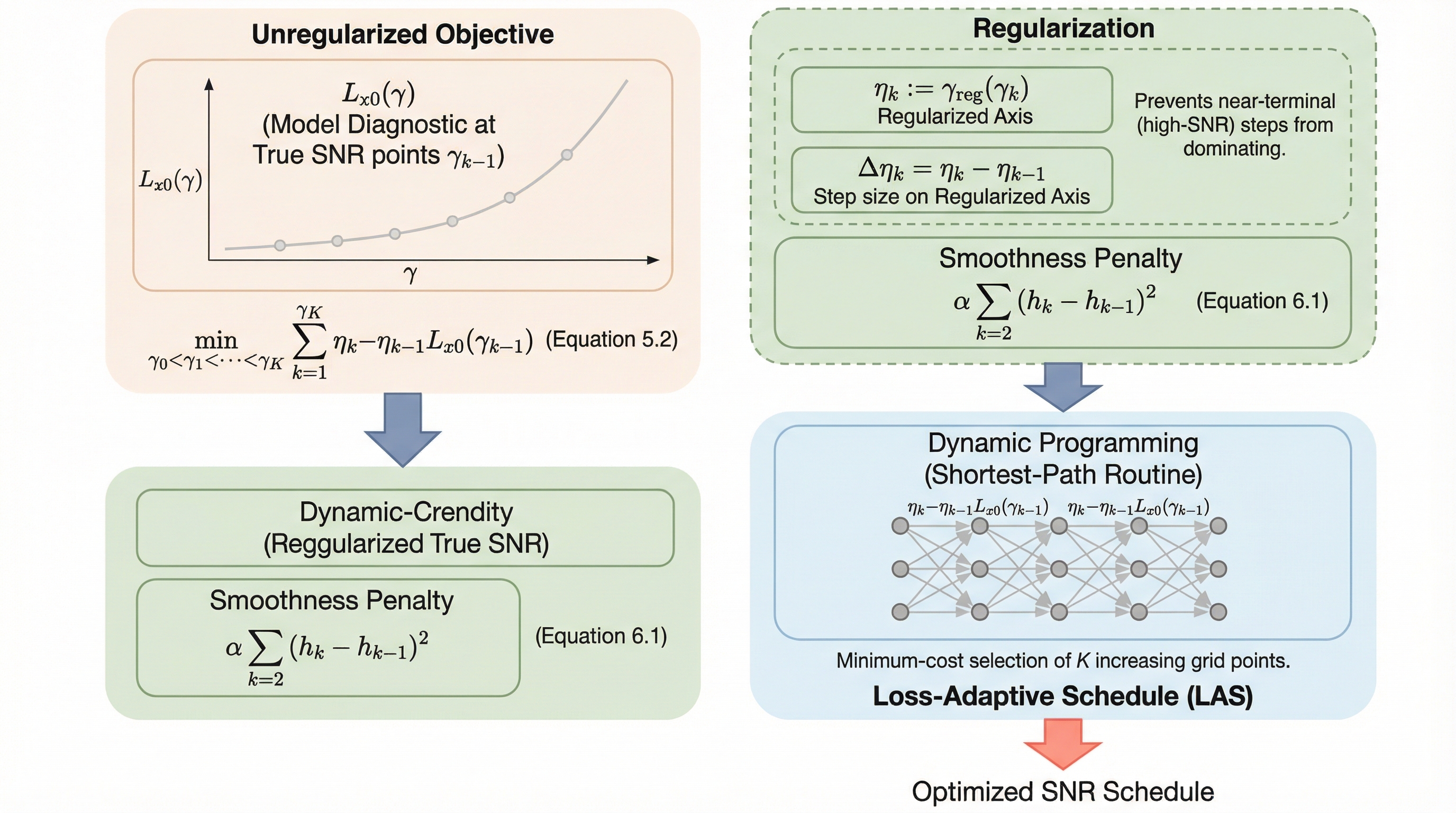
拡散モデルのサンプリング誤差がデータの次元数に比例して増大するという従来の理論的制約を打破し、情報の複雑さを示す「シャノン・エントロピー」を用いることで、次元に依存しない新しい収束境界を導出しました。
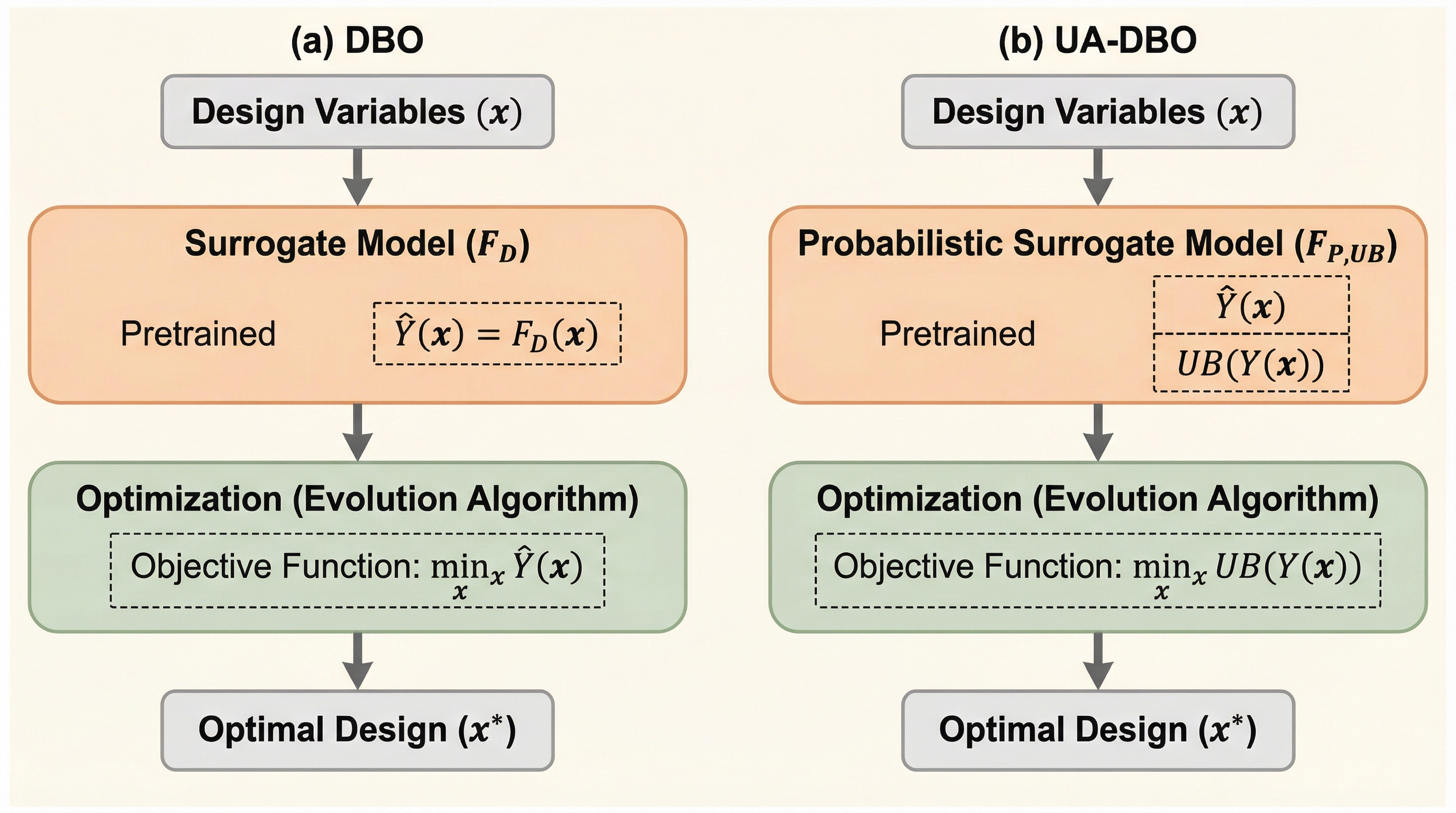
航空機設計におけるデータ駆動型最適化(DBO)は、学習済みモデルを用いて高速な評価を可能にするが、学習データの範囲外の形状に対してモデルが「過信」による楽観的な予測誤差を犯し、信頼性の低い設計結果を導くという重大な課題があった。