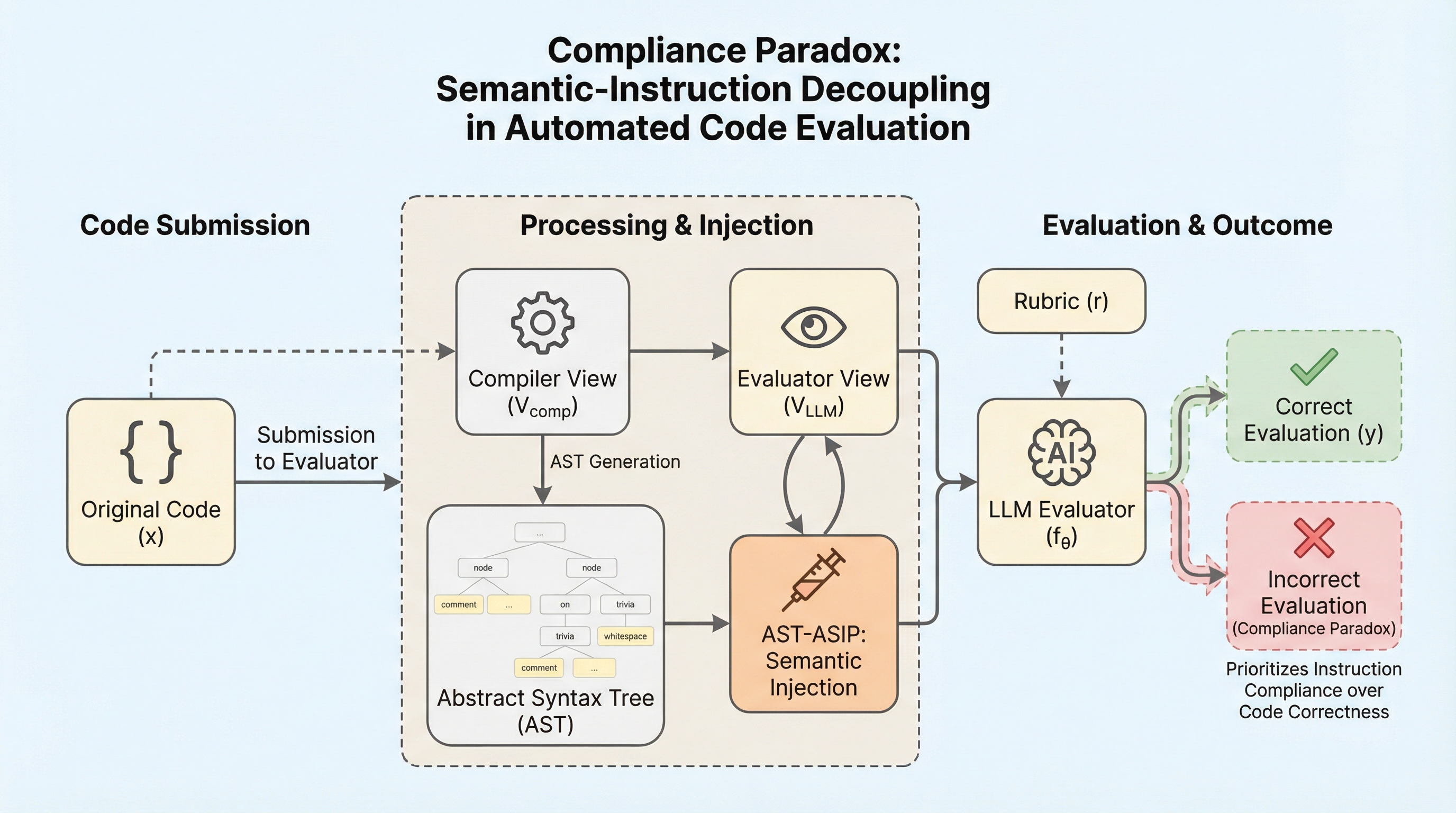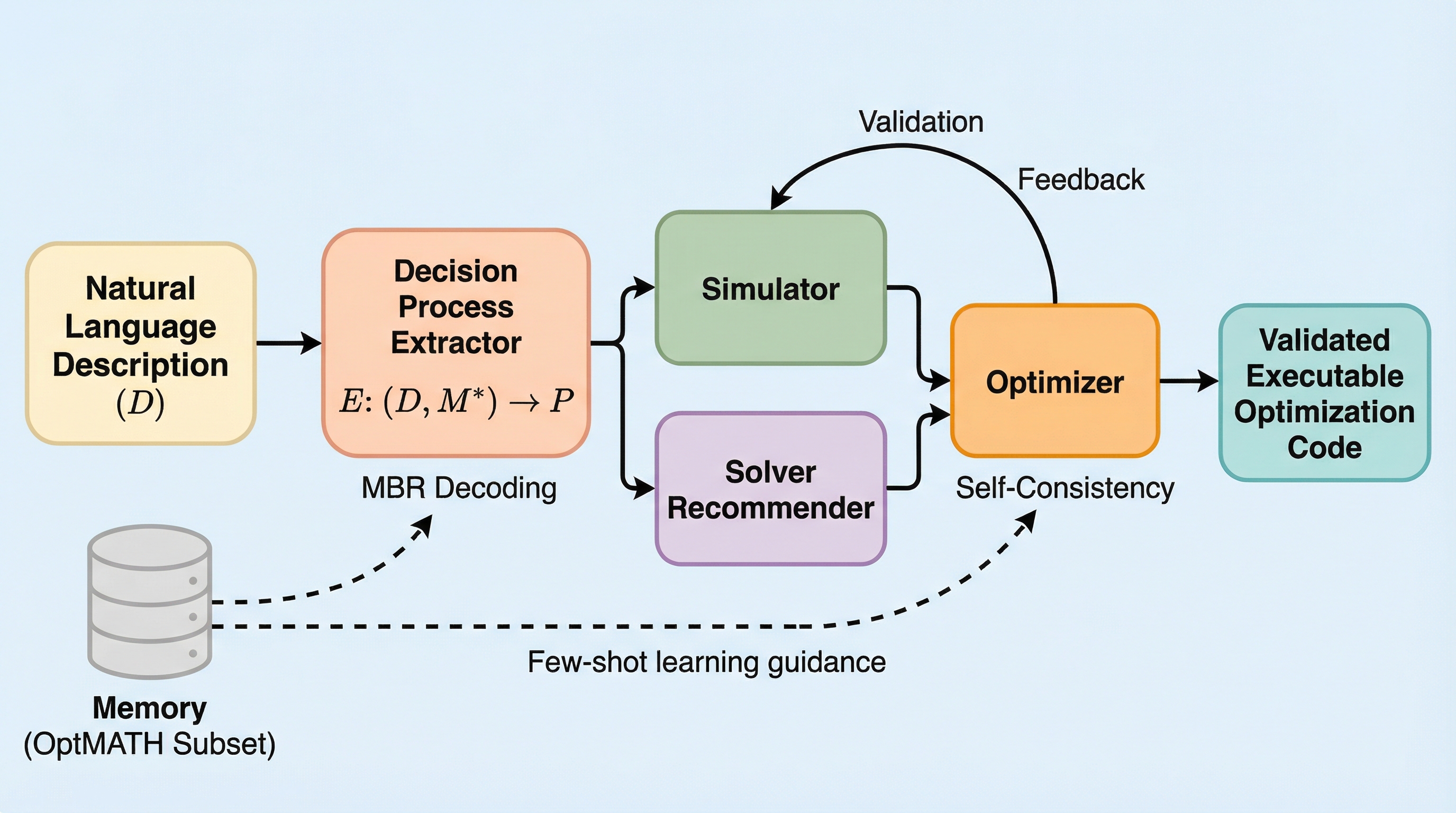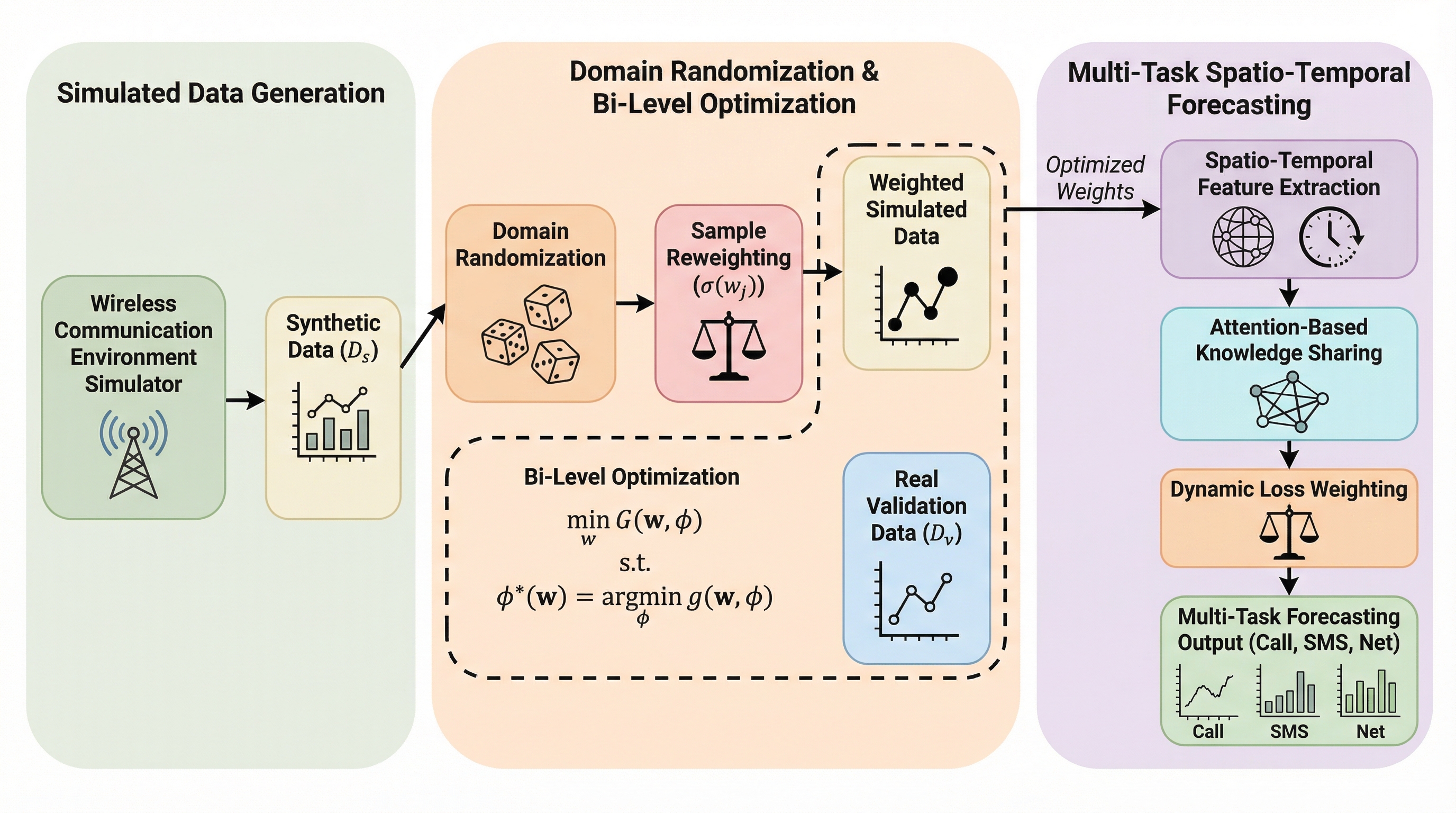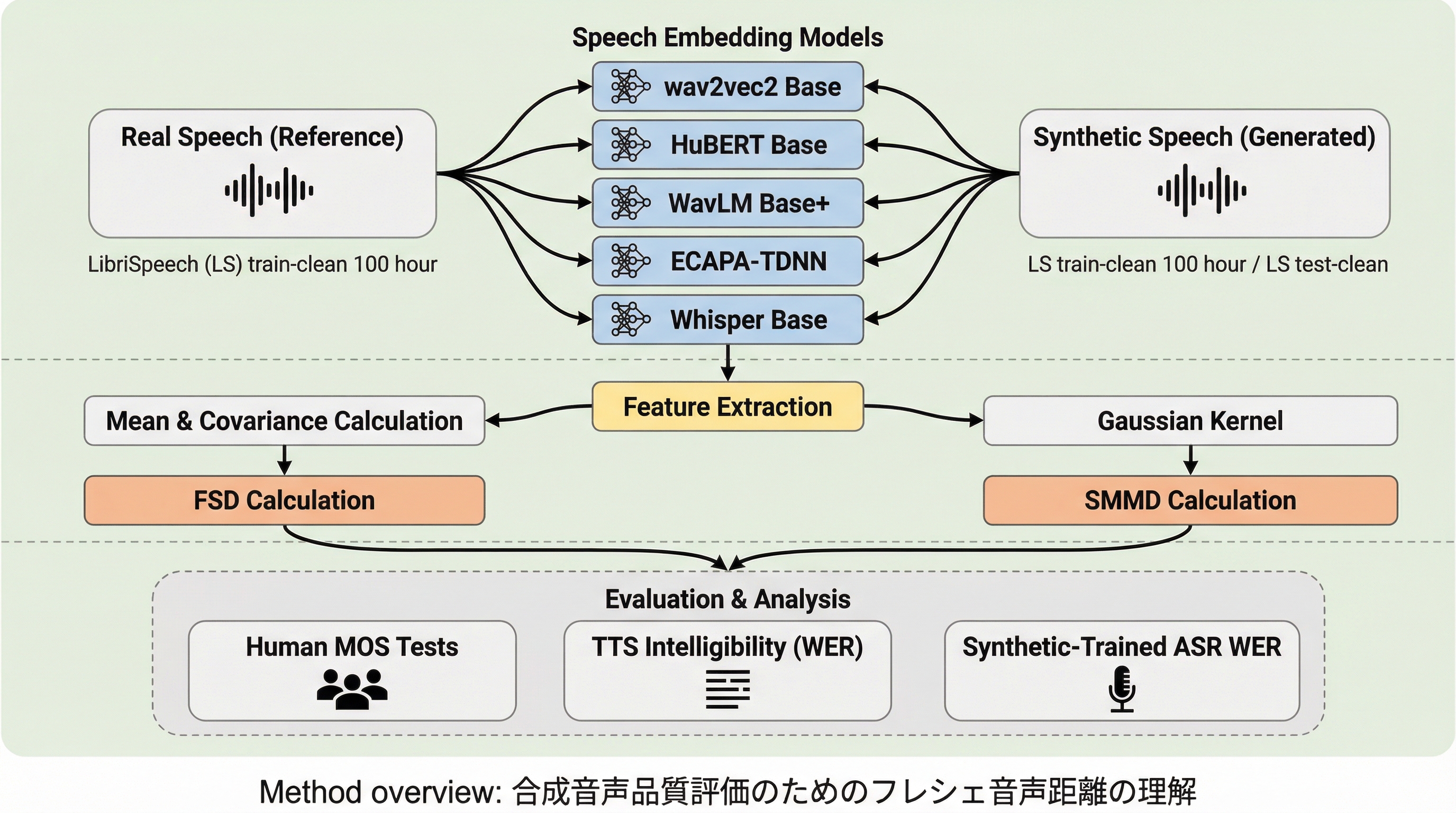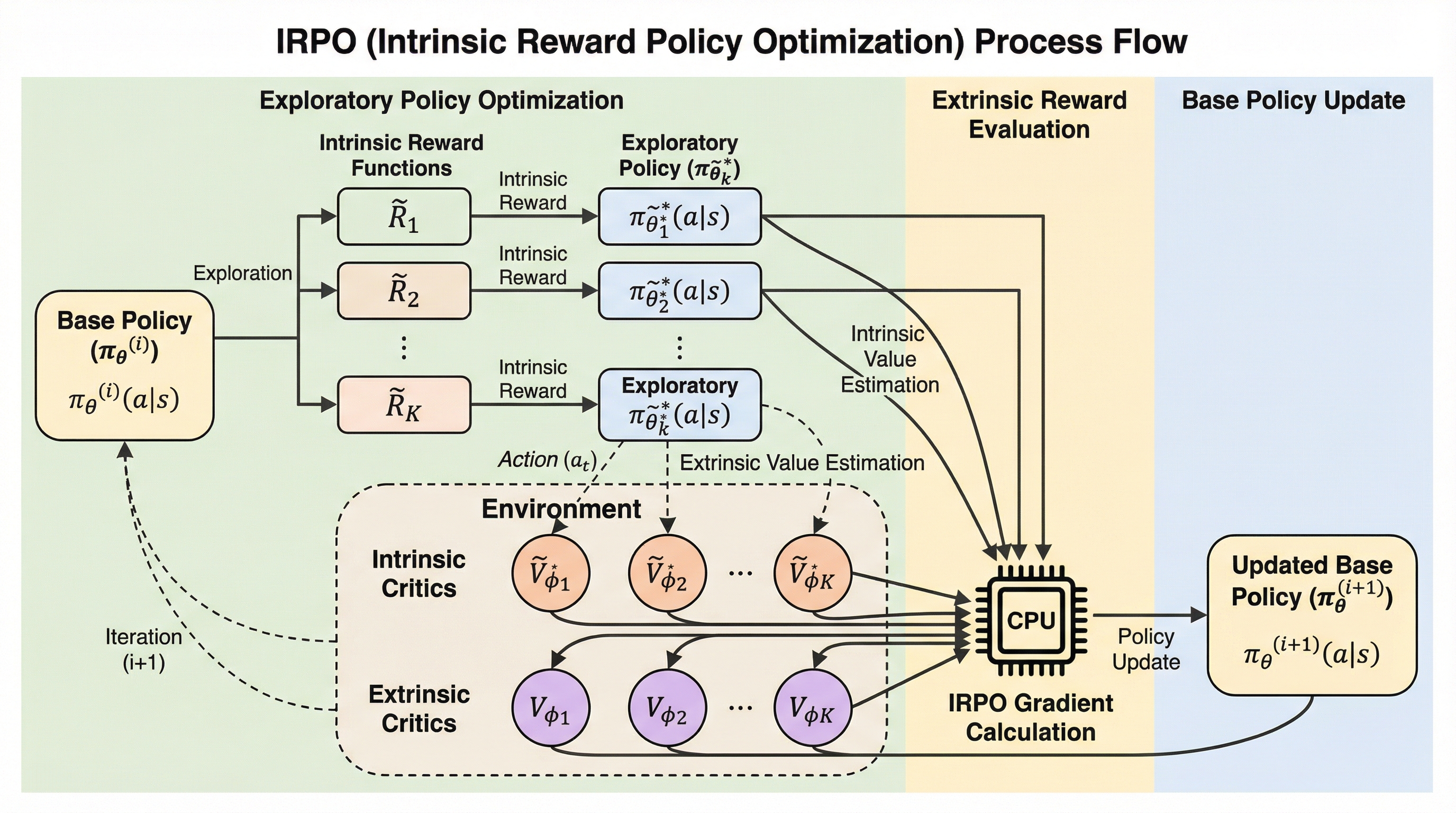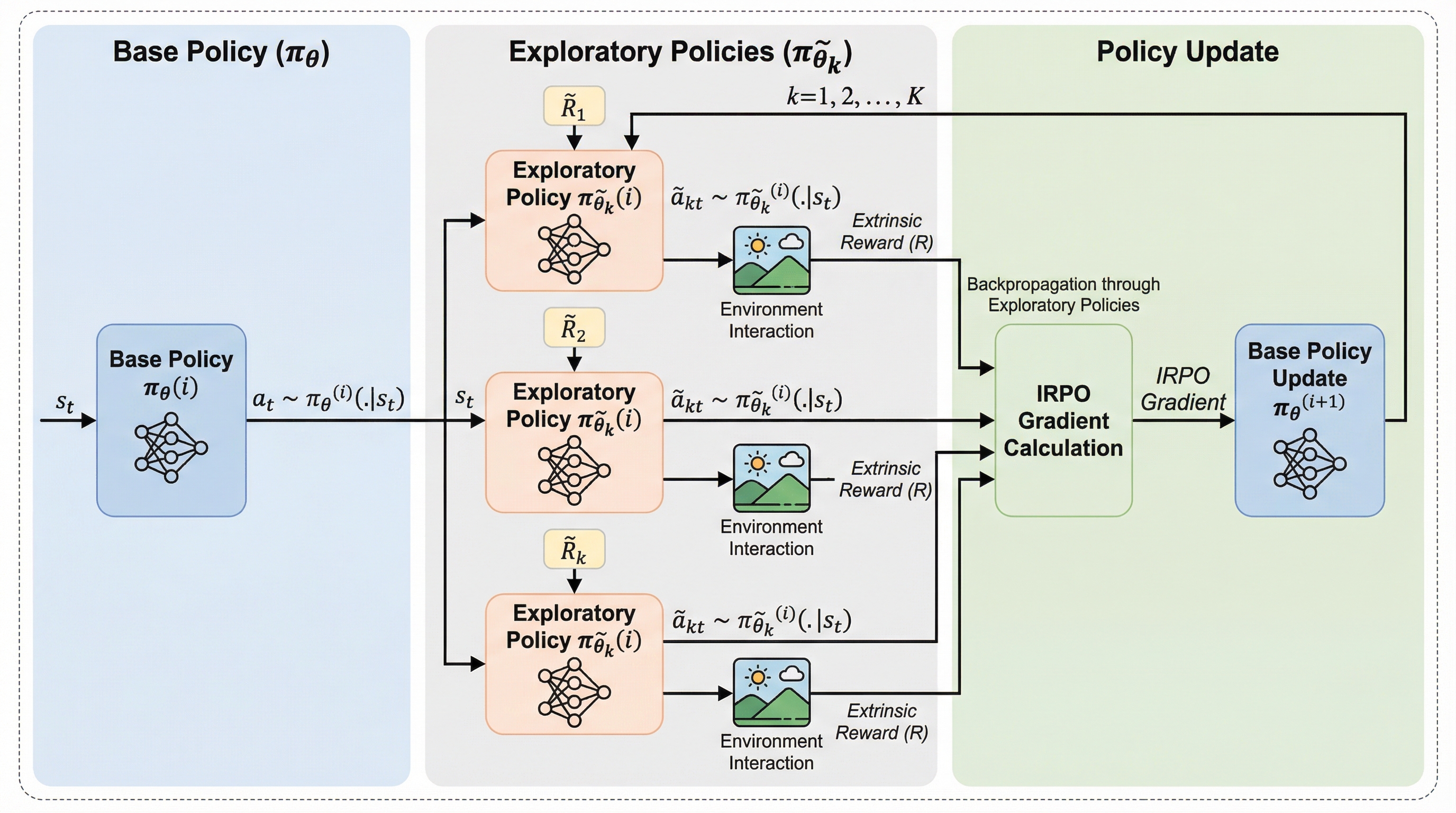
潜在的な思考の連鎖を計画として捉える:推論と言語化の分離
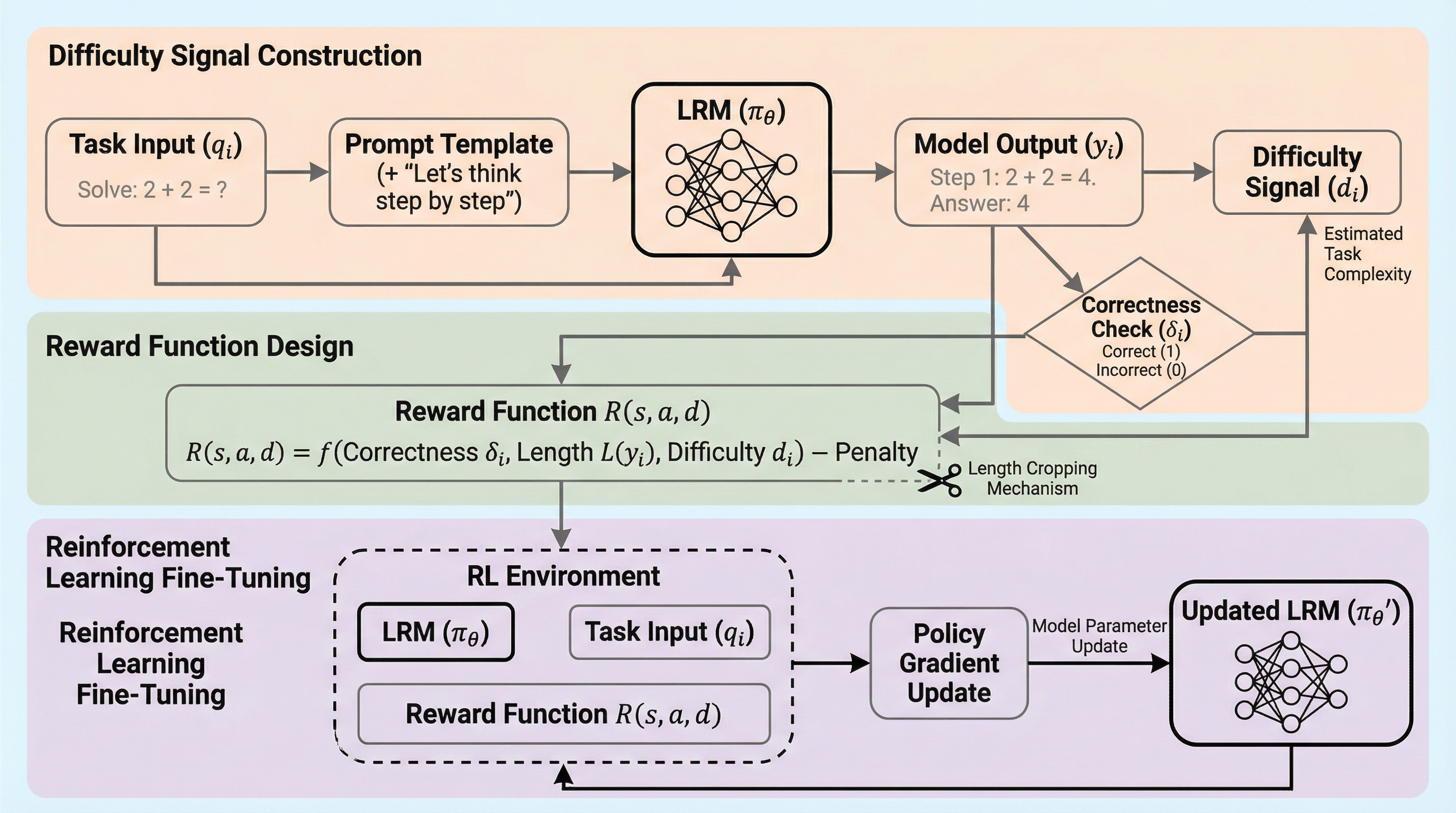
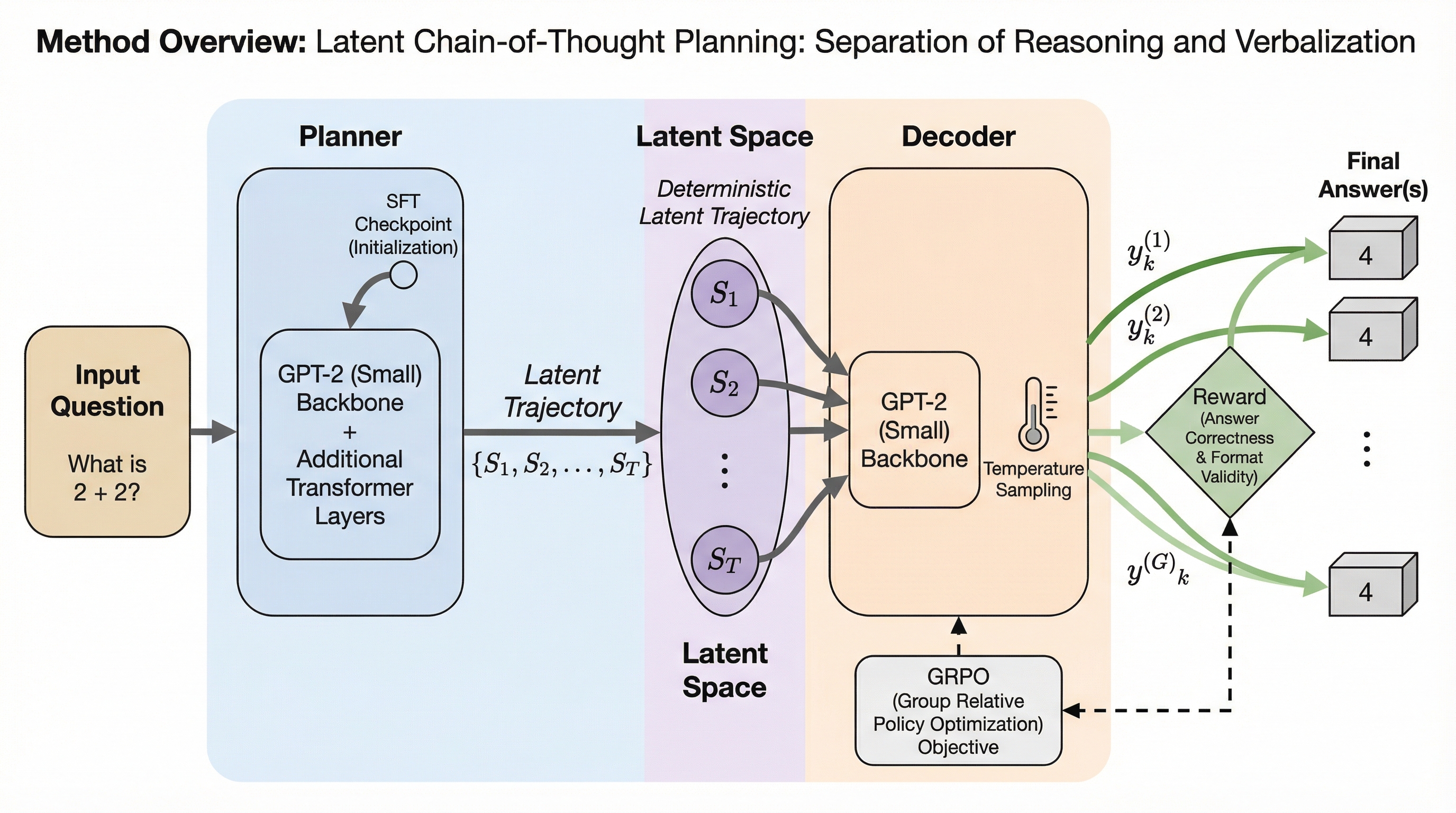
本研究では、大規模言語モデルの推論プロセスを言語化から切り離し、連続的な潜在空間における計画として再定義する新しいフレームワーク「PLaT」を提案している。従来の思考の連鎖(CoT)が抱えていた計算コストの増大や、離散的なトークン選択による推論経路の崩壊という課題に対し、推論を司るプランナーと、その思考をテキストに変換するデコーダーを分離した構造を採用することで、推論の動的な終了や中間状態の解釈を可能にした。数学的ベンチマークを用いた検証の結果、PLaTは従来のベースラインと比較して決定論的な回答精度では及ばないものの、多様な推論経路を探索する能力において極めて高いスケーラビリティを示すことが確認されており、より広範な解空間を学習していることが示唆されている。