難易度を考慮した強化学習による大規模推論モデルの過剰思考の軽減
大規模推論モデル(LRM)が、非常に単純な問いに対しても不必要に長い思考プロセスを展開してしまう「過剰思考(オーバーシンキング)」という課題を解決するため、タスクの難易度を自律的に認識して推論の深さを調整する新しい学習枠組み「DiPO」が提案されました。
TL;DR(結論)
大規模推論モデル(LRM)が、非常に単純な問いに対しても不必要に長い思考プロセスを展開してしまう「過剰思考(オーバーシンキング)」という課題を解決するため、タスクの難易度を自律的に認識して推論の深さを調整する新しい学習枠組み「DiPO」が提案されました。この手法は、モデル自身の出力トークン数と正解率という内部的な情報を活用してタスクの複雑さを自動的に定量化し、その難易度信号を強化学習の報酬関数に組み込むことで、正解率を維持したまま不要な推論ステップを大幅に削減することに成功しています。数学的推論や多領域のデータセットを用いた広範な検証の結果、DiPOは既存のプロンプト設計や単純な強化学習手法よりも高い圧縮率と汎用性を示し、計算リソースの効率化と制御可能な推論プロセスを両立できることが証明されました。これにより、推論コストの削減と応答速度の向上が期待されます。
なぜこの問題か
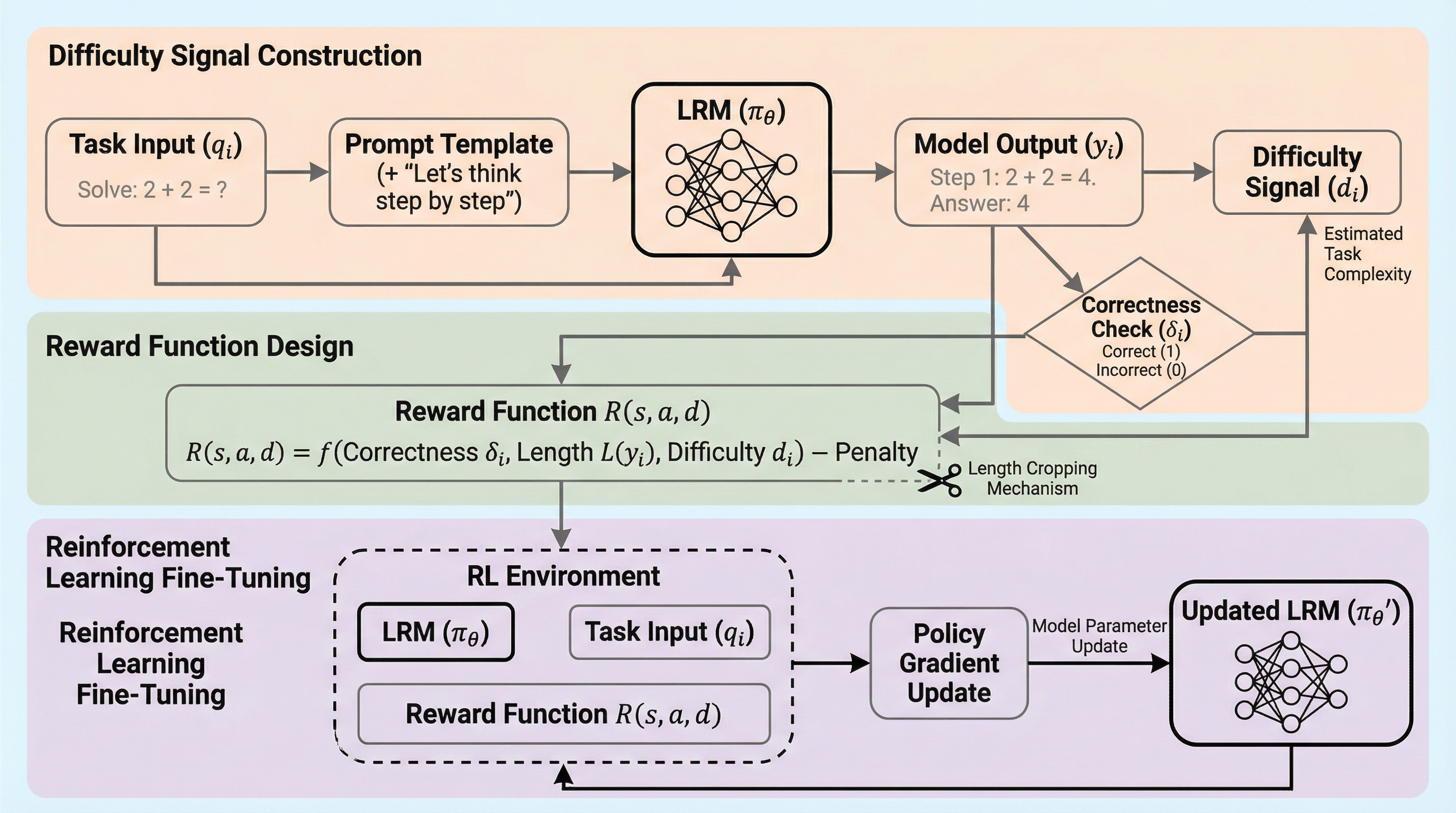
大規模推論モデル(LRM)は、人間が深く考える際の思考プロセスを模倣し、段階的な思考の連鎖(Chain-of-Thought)を明示的に展開することで、複雑な数学問題や論理的推論において優れた性能を発揮してきました。しかし、この「深く考える」という特性が、皮肉にも新たな非効率性を生んでいます。それが「オーバーシンキング(過剰思考)」と呼ばれる現象です。モデルは、本来であれば瞬時に回答できるような極めて単純な質問に対しても、数百から数千トークンに及ぶ冗長な思考を生成してしまい、結果として計算リソースの膨大な浪費や、ユーザーへの応答遅延を招いています。例えば、「3.8と3.11のどちらが大きいか」という単純な数値比較に対し、既存の高性能モデルが膨大な自己検証や不必要な計算ステップを繰り返すケースが報告されています。具体例では、一般的な言語モデルがわずか十数トークンで回答する一方で、特定の推論モデルは800トークン以上を費やして同じ結論に達するといった、極端な非効率性が観察されています。 この問題の根本的な原因は、モデルの事後学習(Post-training)における報酬設計の不備にあります。…
核心:何を提案したのか
本論文では、大規模推論モデルの過剰思考を系統的に解消するための新しい強化学習フレームワーク「Difficulty-aware Policy Optimization(DiPO)」を提案しています。DiPOの最大の特徴は、モデルが推論プロセスの中でタスクの難易度を自律的に知覚し、その認識に基づいて推論の深さを動的に調整できるようにした点にあります。これを実現するために、研究チームは「自己推論に基づく難易度モデリング手法」を開発しました。これは、モデルが特定の問いに対して生成した出力の長さや正誤といった内部的な特徴を利用して、タスクの複雑さを定量化する仕組みです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related