報酬が疎な環境のための内発的報酬方策最適化
強化学習において報酬が稀薄な環境は、エージェントが最適な方策を見つけるための探索が困難であるという課題を抱えています。本研究で提案されたIRPO(Intrinsic Reward Policy Optimization)は、複数の内発的報酬を利用して探索用の方策を更新し、その結果得られた信号をベース方策へ逆伝播させることで、稀薄な報酬環境でも効果的な学習を実現する新しい最適化フレームワークです。実験の結果、離散および連続の多様なタスクにおいて、従来の手法である階層型強化学習や報酬加算型の手法を上回る高い最終性能と優れたサンプル効率を達成することが確認されました。
TL;DR(結論)
強化学習において報酬が稀薄な環境は、エージェントが最適な方策を見つけるための探索が困難であるという課題を抱えています。本研究で提案されたIRPO(Intrinsic Reward Policy Optimization)は、複数の内発的報酬を利用して探索用の方策を更新し、その結果得られた信号をベース方策へ逆伝播させることで、稀薄な報酬環境でも効果的な学習を実現する新しい最適化フレームワークです。実験の結果、離散および連続の多様なタスクにおいて、従来の手法である階層型強化学習や報酬加算型の手法を上回る高い最終性能と優れたサンプル効率を達成することが確認されました。
なぜこの問題か
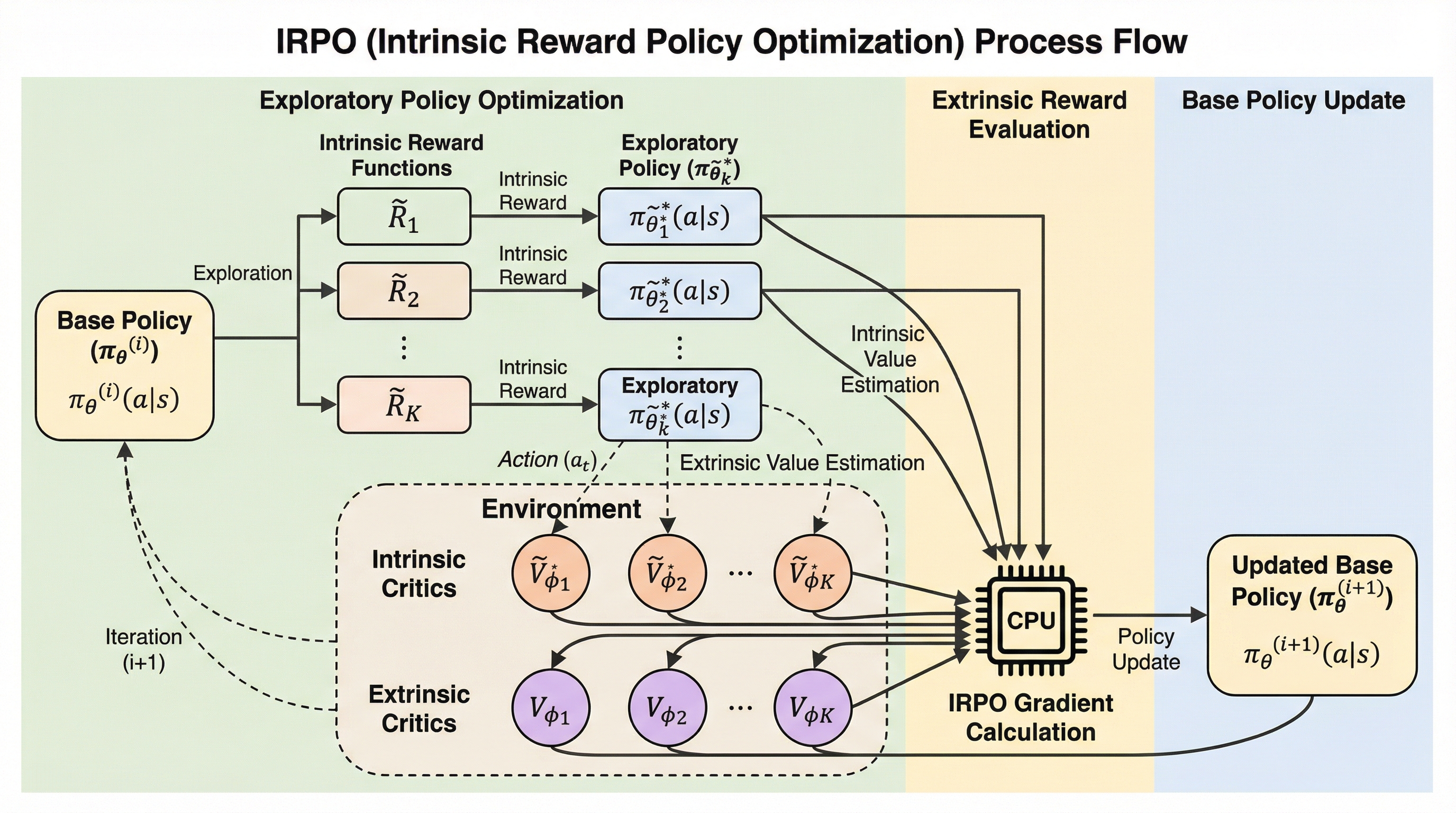
強化学習(RL)の目的は、試行錯誤を通じて最適な方策を学習することにありますが、そのためにはエージェントが環境を徹底的に探索することが不可欠です。しかし、多くの現実的なタスクでは、エージェントが特定の目標に到達したときにのみ報酬が得られる「稀薄な報酬(Sparse Reward)」の設定となっており、これが学習を極めて困難にしています。従来のアクション空間やパラメータ空間へのノイズ注入といった単純な探索戦略では、収集される経験に十分な多様性をもたらすことができず、複雑な環境では性能が制限されてしまいます。 この問題に対処するため、内発的報酬(Intrinsic Reward)を用いて探索を導く手法が提案されてきました。一般的な戦略としては、状態の訪問回数やモデルの不確実性に基づいてエージェントに未知の領域を探索させる方法や、内発的報酬で事前学習したサブポリシーを時間的に拡張されたアクションとして利用する階層型強化学習(HRL)があります。…
核心:何を提案したのか
本研究は、内発的報酬を活用して「代理方策勾配(Surrogate Policy Gradient)」を構築し、それを用いてベースとなる方策を直接最適化するアルゴリズム「IRPO(Intrinsic Reward Policy Optimization)」を提案しました。IRPOの最大の特徴は、サブポリシーの事前学習を必要とせず、複数の内発的報酬から得られる探索的な情報を、外発的報酬を最大化するための学習信号へと変換する点にあります。これにより、従来の報酬加算型の手法で見られたクレジット割り当ての不安定さと、階層型強化学習で見られたサンプル効率の悪さの両方を解決することを目指しています。 IRPOは、現在のベース方策から出発して、内発的報酬によって最適化された複数の「探索用方策(Exploratory Policies)」を内部的に生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related