報酬が疎な環境のための内発的報酬方策最適化
本研究は、目標達成時のみ報酬が得られる「報酬が疎な環境」において、効率的な探索と精密な制御を両立させる新しい強化学習アルゴリズム「内発的報酬方策最適化(IRPO)」を提案しました。 従来の内発的報酬を加算する手法や階層型強化学習が抱えていた、報酬割り当ての不安定さやサンプル効率の悪さ、および解の劣適性といった課題を、複数の探索用方策からの勾配をバックプロパゲーションで統合する「代理方策勾配」の仕組みによって解決しています。 複雑な迷路やロボット制御タスクを用いた実験において、既存の主要なベースラインを大幅に上回る学習速度と最終性能を達成し、特に精密な動作が要求される連続空間のタスクで顕著な優位性と安定性を示しました。
TL;DR(結論)
本研究は、目標達成時のみ報酬が得られる「報酬が疎な環境」において、効率的な探索と精密な制御を両立させる新しい強化学習アルゴリズム「内発的報酬方策最適化(IRPO)」を提案しました。 従来の内発的報酬を加算する手法や階層型強化学習が抱えていた、報酬割り当ての不安定さやサンプル効率の悪さ、および解の劣適性といった課題を、複数の探索用方策からの勾配をバックプロパゲーションで統合する「代理方策勾配」の仕組みによって解決しています。 複雑な迷路やロボット制御タスクを用いた実験において、既存の主要なベースラインを大幅に上回る学習速度と最終性能を達成し、特に精密な動作が要求される連続空間のタスクで顕著な優位性と安定性を示しました。
なぜこの問題か
強化学習の基本的な枠組みは試行錯誤を通じた学習にありますが、エージェントが最適な行動を獲得するためには、環境を広範囲に探索し、どのような行動の連鎖が最終的な報酬に結びつくかを理解する必要があります。しかし、現実世界の複雑なタスクの多くは、特定の目標を達成した瞬間にのみ報酬が与えられる「疎な報酬環境」であり、そこではランダムなノイズを注入する程度の単純な探索戦略では、意味のある経験を積む前に学習が停滞してしまいます。この探索の停滞を打破するために、未知の状態への訪問を促す「内発的報酬」を導入する試みが長年行われてきました。 既存の手法には大きく分けて二つの主要なアプローチが存在しますが、それぞれに深刻な欠点があります。一つは、外発的報酬(本来の目的)に内発的報酬を直接加算して最適化する手法です。これは実装が容易である反面、内発的報酬のスケールが適切でないと、エージェントが本来の目的を忘れて探索そのものに固執してしまう「報酬割り当て(クレジット割り当て)」の不安定さを引き起こします。また、状態の訪問回数を数えるカウントベースの手法は、高次元の連続空間では計算が困難になるという拡張性の問題を抱えています。…
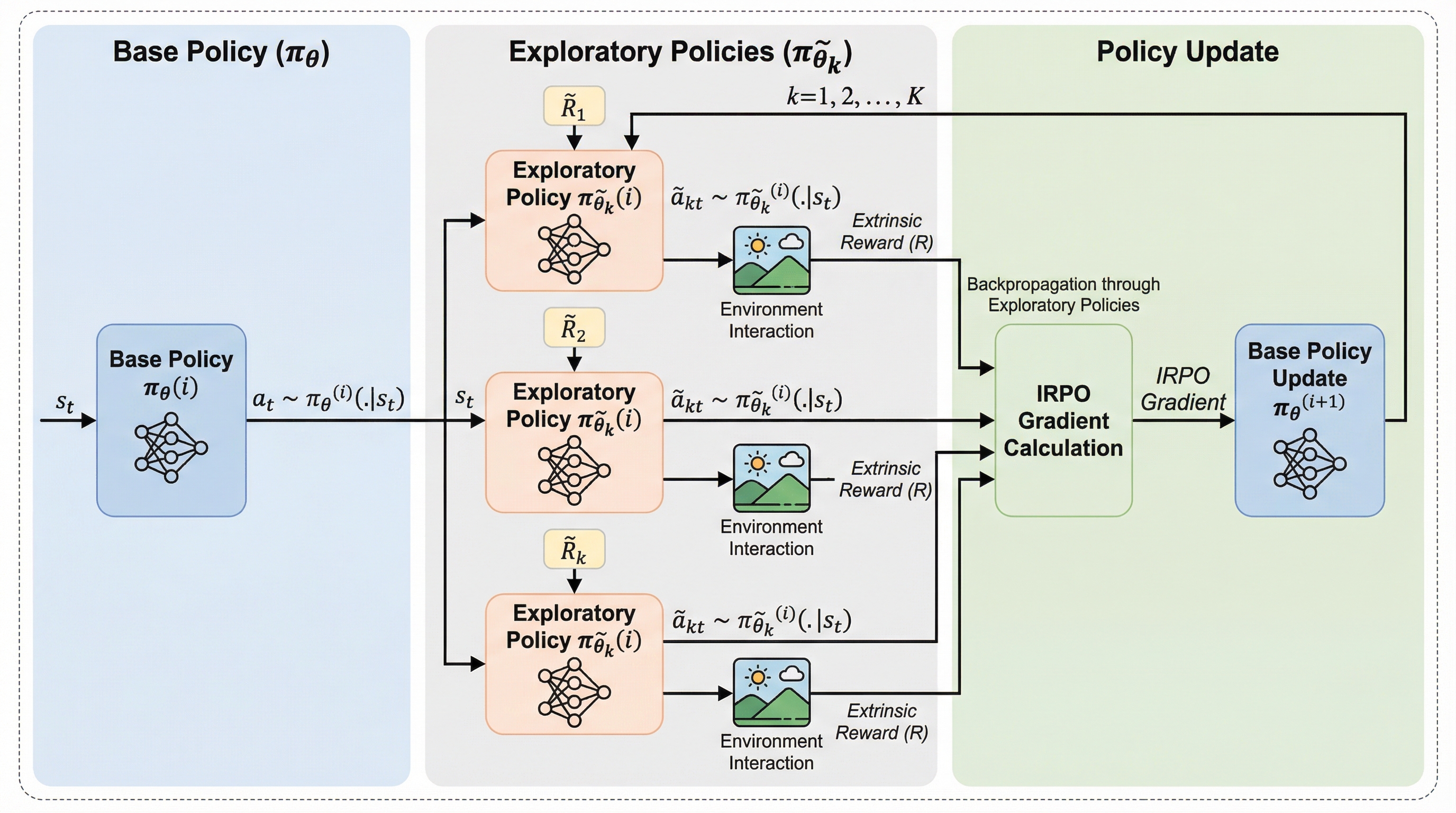
核心:何を提案したのか
本研究が提案する「内発的報酬方策最適化(IRPO)」は、複数の内発的報酬を「探索のガイド」として活用しながら、最終的には外発的報酬を最大化するように「基本方策」を直接最適化する、全く新しいフレームワークです。この手法の核心は、情報の少ない本来の勾配(真の勾配)をそのまま使うのではなく、より学習に役立つ情報を含んだ「代理方策勾配(IRPO勾配)」を構築して利用する点にあります。これにより、報酬が全く得られない初期段階からでも、基本方策を正しい方向へと導くことが可能になります。 IRPOは、現在の基本方策から派生させた複数の「探索用方策」を並行して走らせます。それぞれの探索用方策は、異なる内発的報酬(例えば、エージェントの拡散を最大化するALLOなど)に基づいて個別に更新されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related