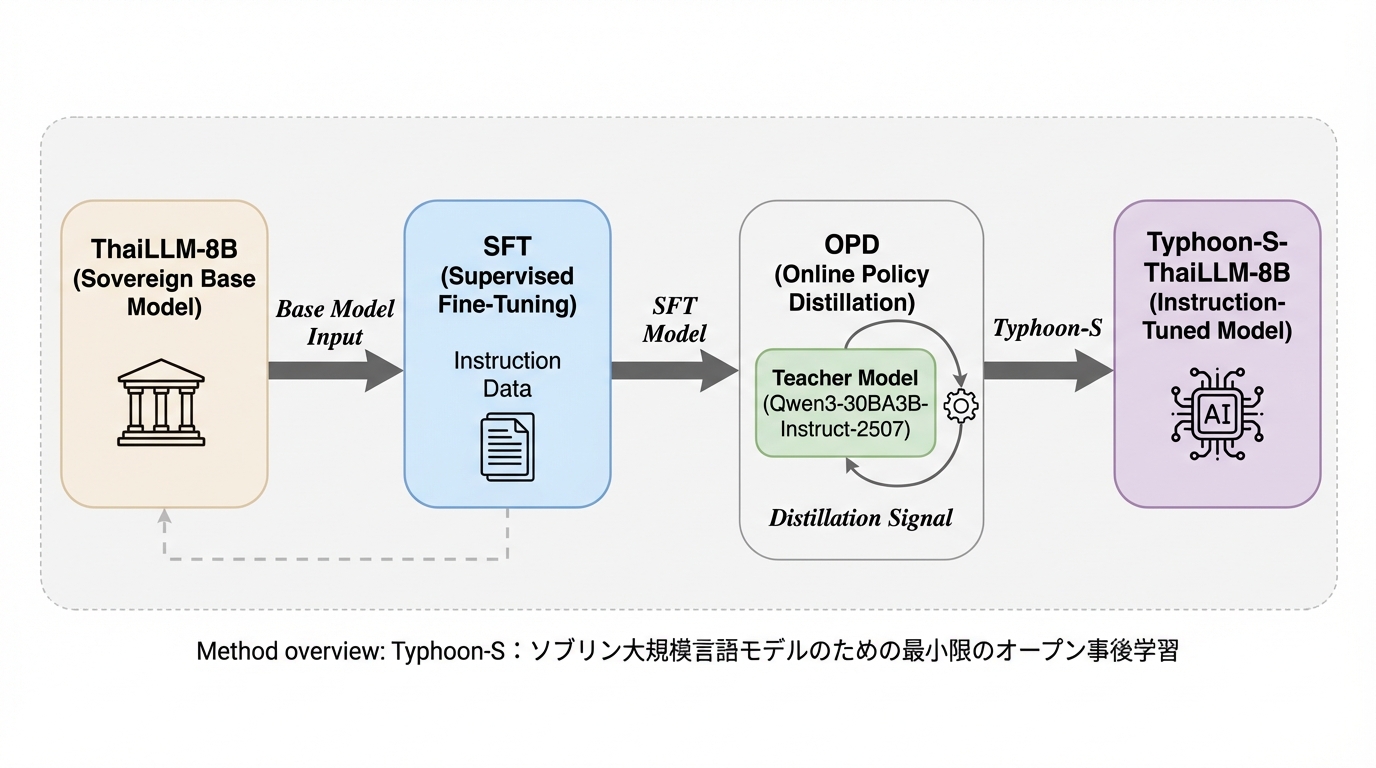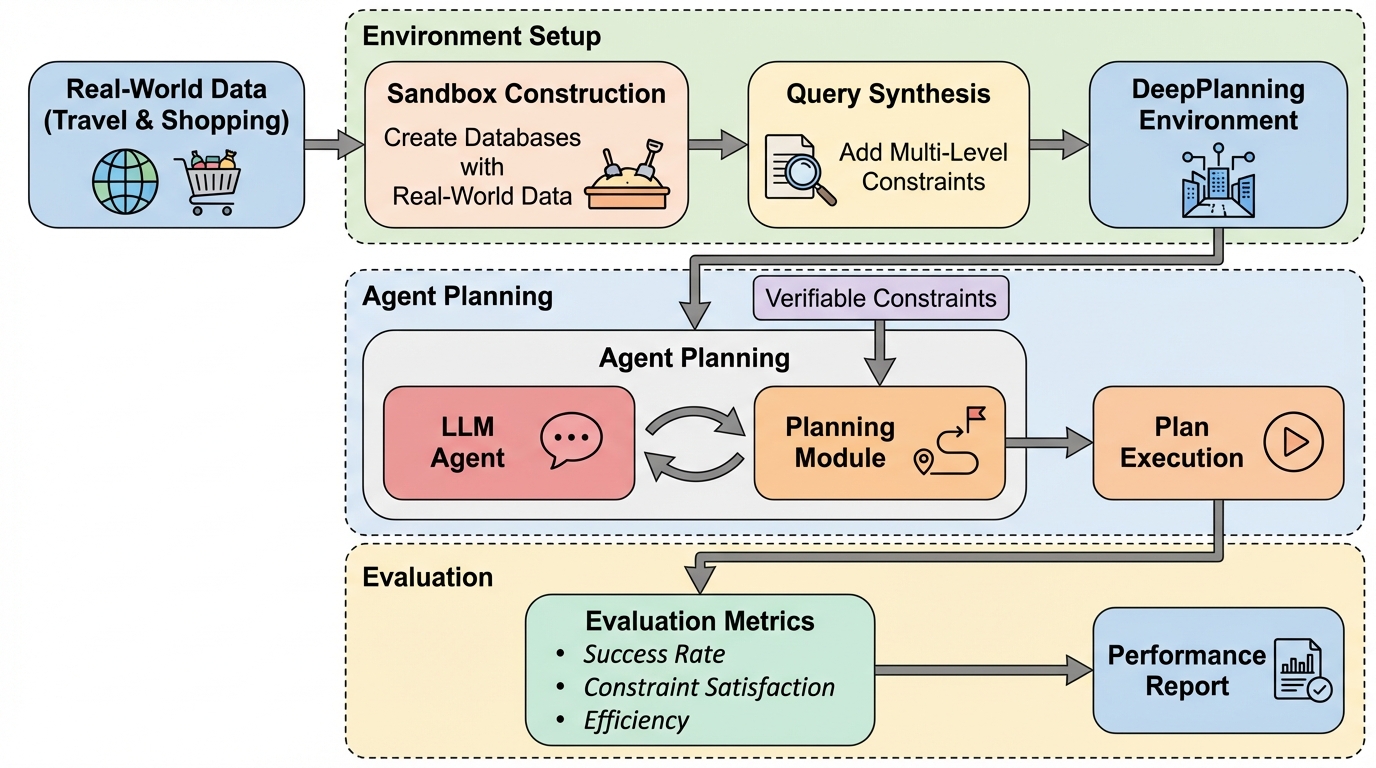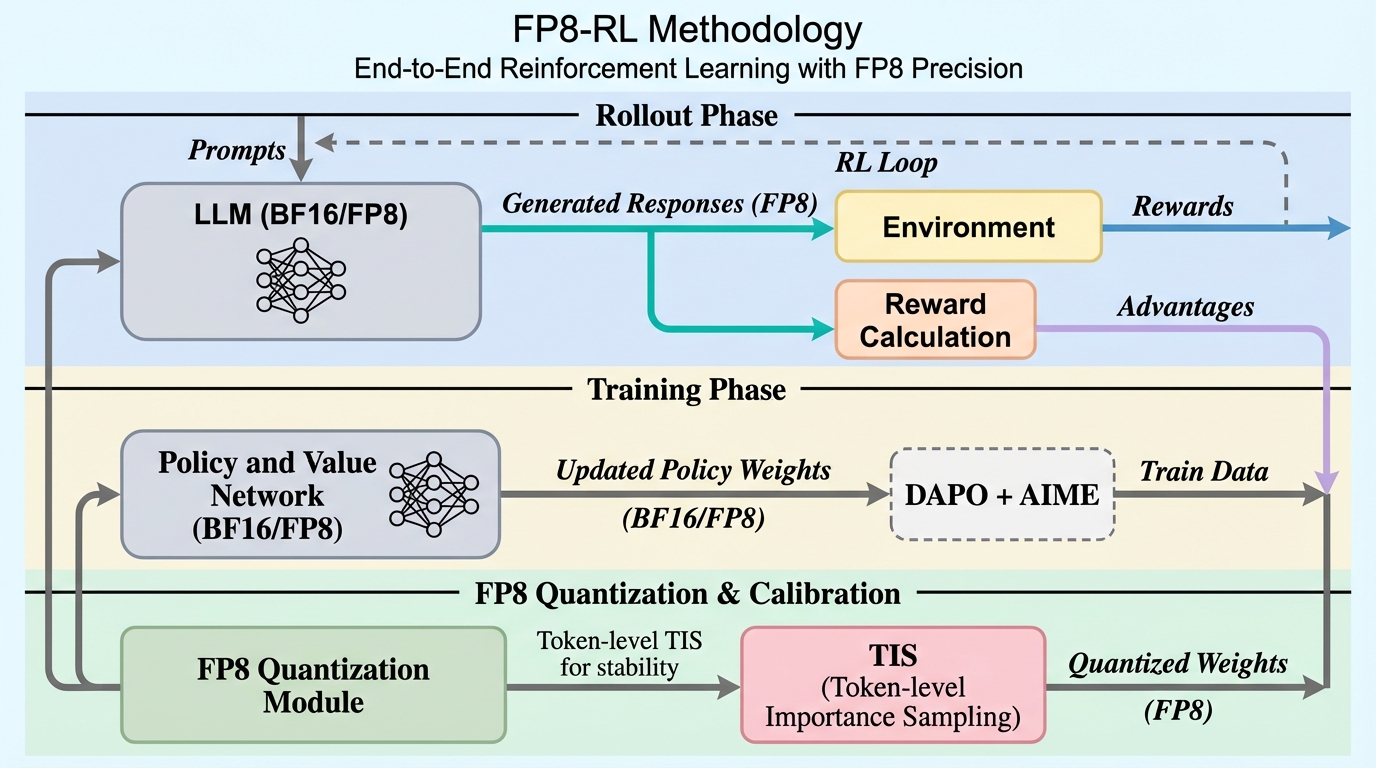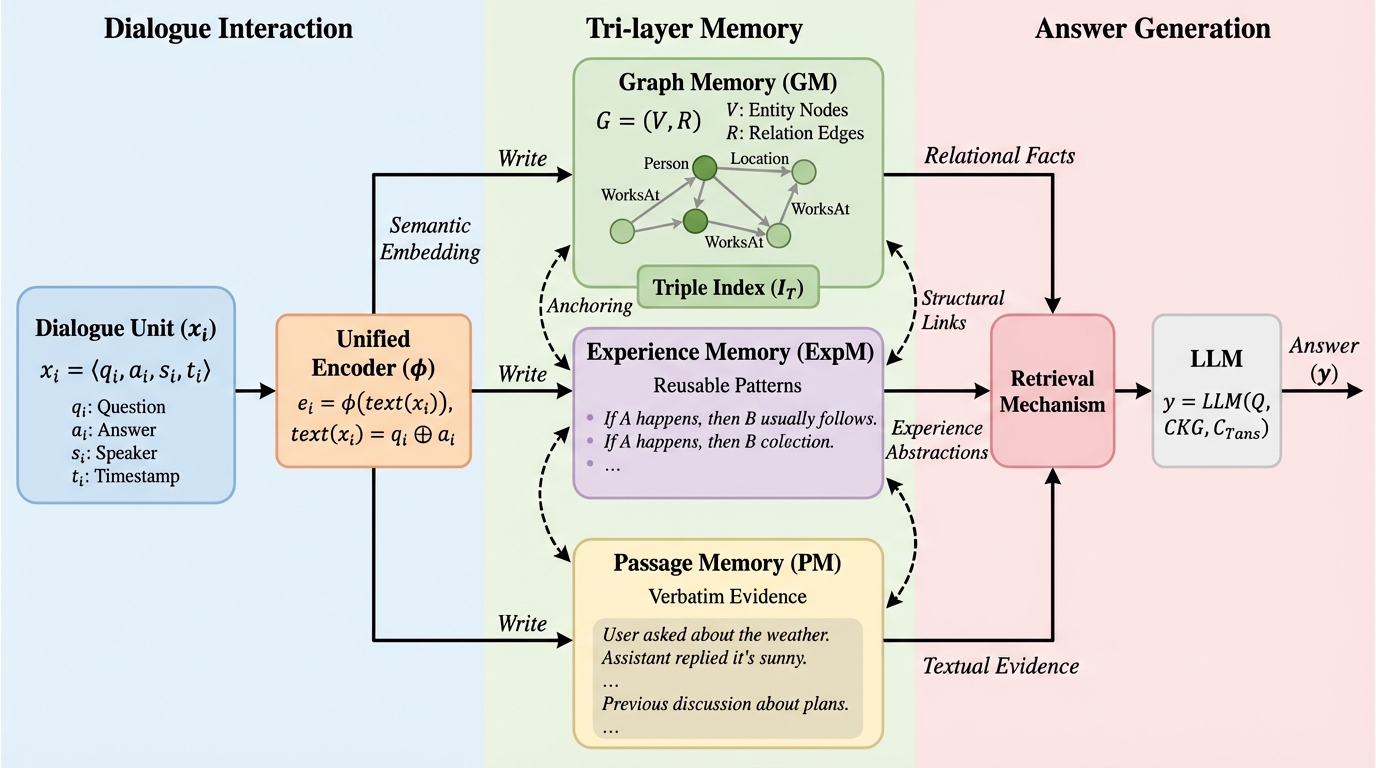
FABLE:多文書推論のための森構造に基づく適応型双方向LLM強化検索
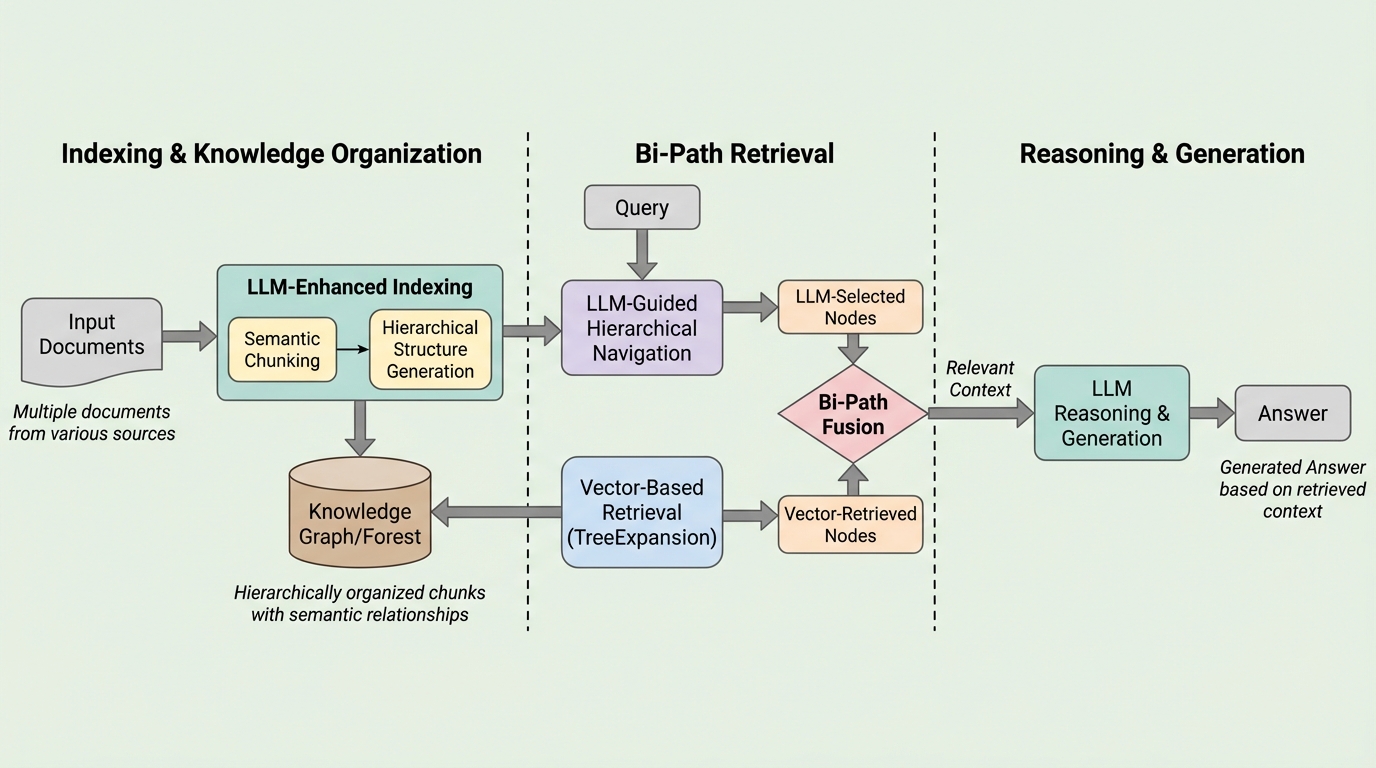
FABLEは、大規模言語モデル(LLM)を知識の組織化と検索プロセスの両方に深く統合した、森構造(Forest-based)に基づく適応型双方向検索フレームワークである。従来の検索拡張生成(RAG)が抱える平坦なチャンク検索によるセマンティックノイズや、長文コンテキストLLMが直面する「情報の埋没(lost-in-the-middle)」、膨大な計算コスト、多文書推論におけるスケーラビリティの欠如といった課題を解決することを目指している。具体的には、LLMを用いて構築した多粒度な階層的セマンティック・フォレスト上での動的なナビゲーションと、構造を考慮した伝播検索を組み合わせることで、完全なコンテキストを用いた推論に匹敵する精度を維持しながら、トークン消費量を最大94%削減することに成功した。