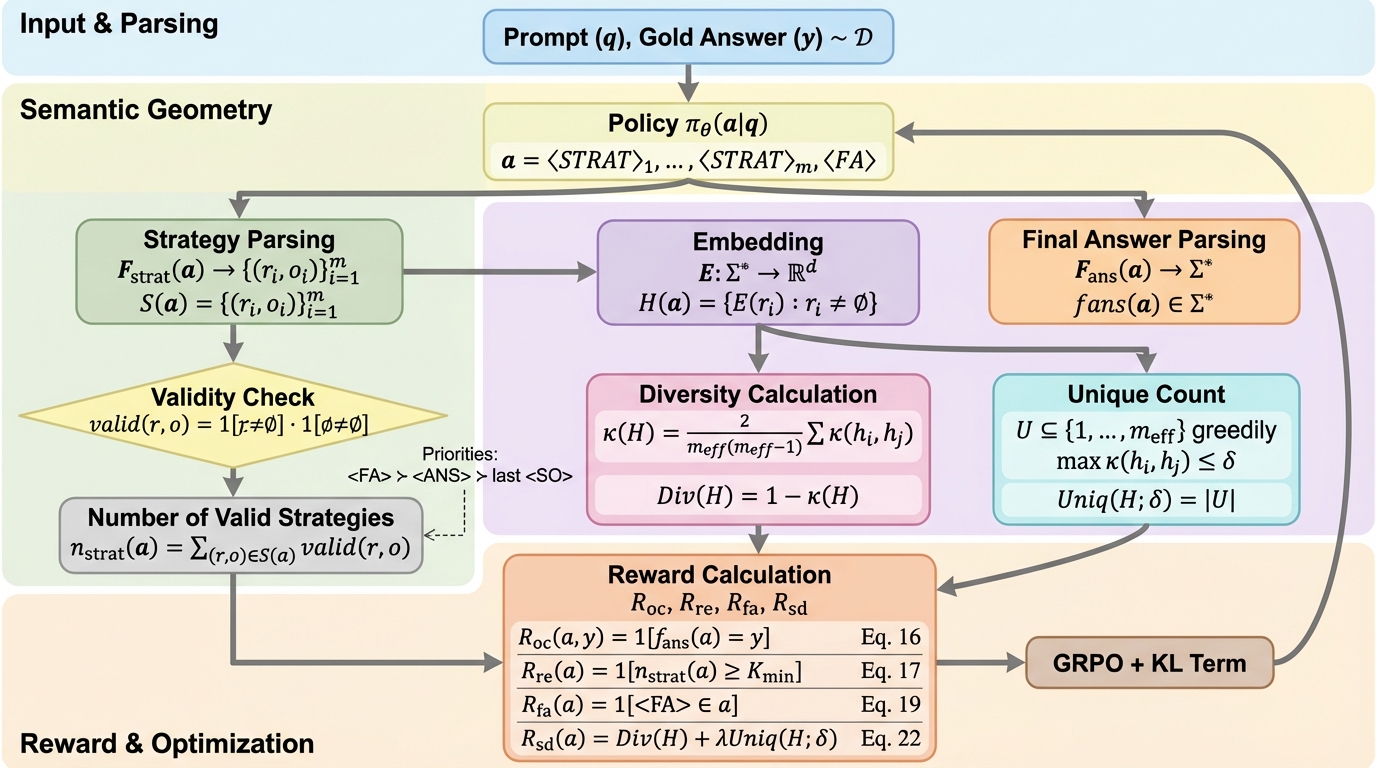
SD-E$^2$:トークン予算制約下での推論のための意味的探索
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
PEARは、機械翻訳の品質評価(QE)において、従来の1つの翻訳文を独立して絶対評価する手法ではなく、2つの翻訳文を同時に読み込ませてその品質差の方向と大きさを直接予測する「段階的なペアワイズ比較」という新しいフレームワークを提案している。
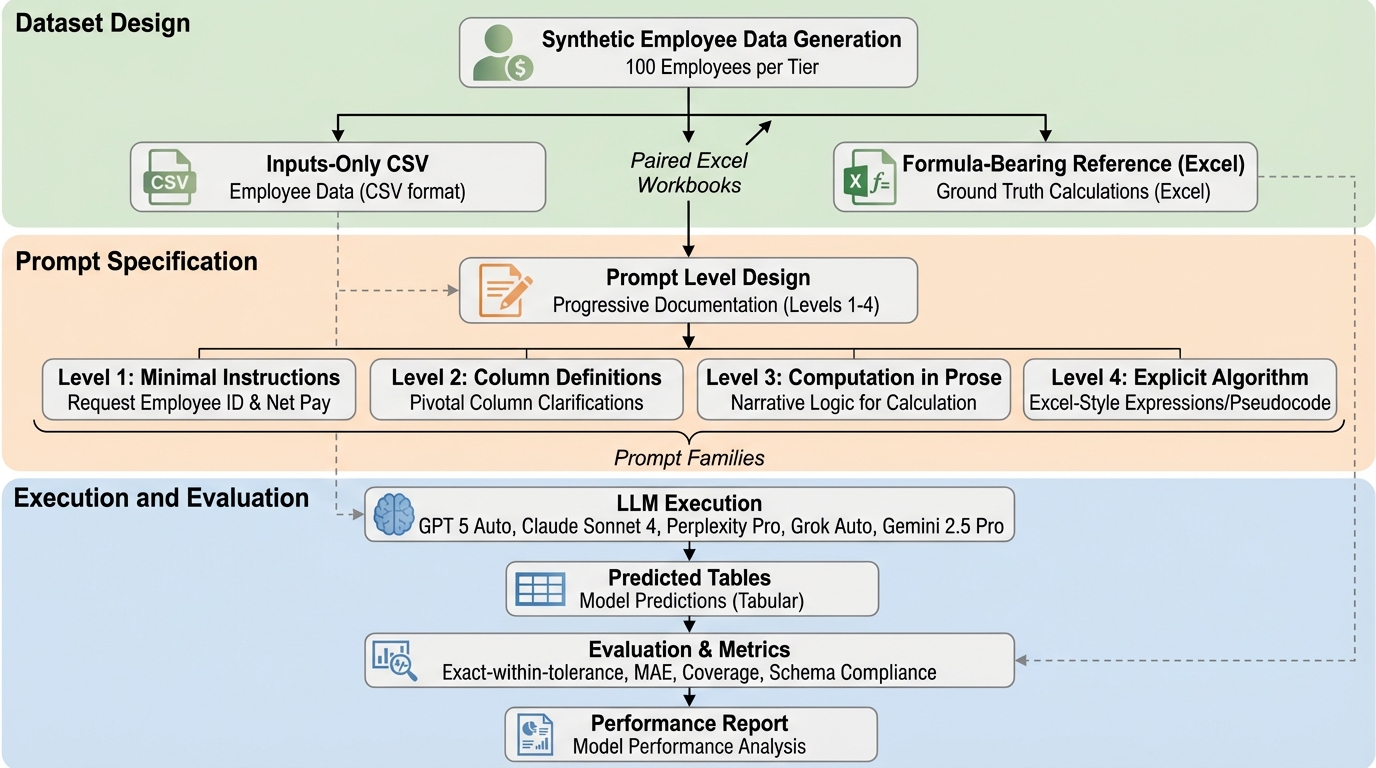
給与計算は、わずか数セントの誤差が法令遵守に影響を与えるため、大規模言語モデル(LLM)にとって極めて高い精度と監査可能性が求められる過酷なテストケースとなります。現在のLLMは文章作成や分析において優れた能力を示していますが、厳密な数値計算や、複雑なビジネスルールを正しい順序で適用する能力については依然として不確実性が残っており、本研究ではその限界と可能性を検証しました。 研究では、GPT 5 Auto、Claude Sonnet 4、Perplexity Pro、Grok Auto、Gemini 2.5 Proといった主要なモデルを対象に、5段階の難易度を持つデータセットと4段階のプロンプト手法を用いて、給与計算スキーマの意味理解と計算精度を評価しました。検証の結果、単純な計算では多くのモデルが100%の精度を達成したものの、複雑なシナリオではプロンプトの詳細度が精度に大きく影響し、特に明示的な数式を提供したレベル4においてPerplexity Proが最も高い信頼性を示しました。 実験データによれば、単純な乗算を超えた複雑なタスクにおいて、LLMが単独で正確な結果を出すには限界があり、明示的なアルゴリズムの提示や外部ツールの活用が不可欠であることが明らかになりました。特に、多州にまたがる税金の按分や為替変換を含む高度なシナリオでは、モデル間で性能の差が顕著に現れており、実務への導入には慎重なプロンプト設計と検証プロセスの構築が求められるという結論に至っています。
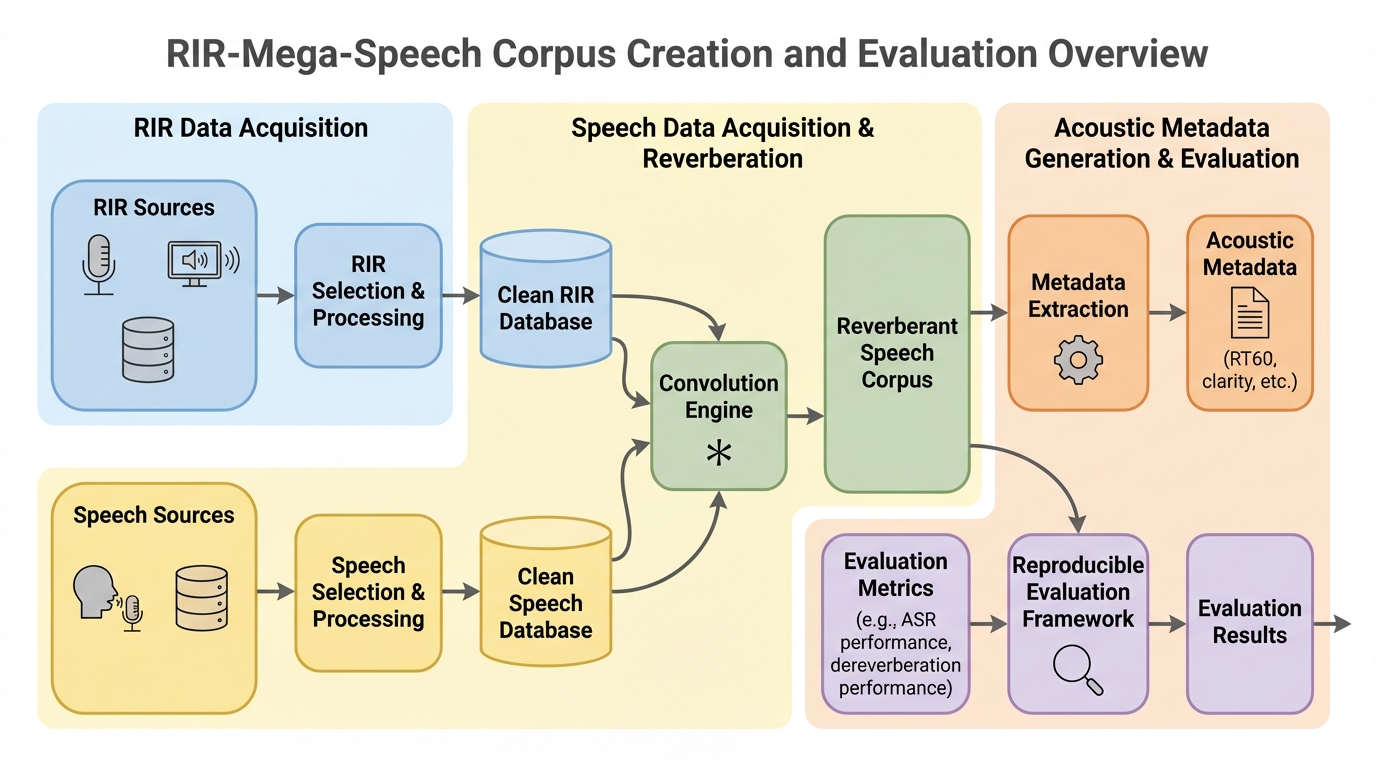
RIR-Mega-Speechは、LibriSpeechの音声と約5,000のシミュレーションされた部屋インパルス応答(RIR)を組み合わせた、約117.5時間の新しい残響音声コーパスである。最大の特徴は、全ファイルに対してRT60、直接音対残響音比(DRR)、明瞭度指数(C50)といった詳細な音響メタデータが付与されている点にあり、WindowsおよびLinux環境でデータセットの再構築や評価結果の再現が可能なスクリプトが提供されている。Whisper smallモデルを用いた検証では、残響によって単語誤り率(WER)が5.20%から7.70%へと相対的に48%悪化することが示され、RT60の増加やDRRの低下に伴って認識精度が単調に低下する物理的特性と一致する傾向が確認された。
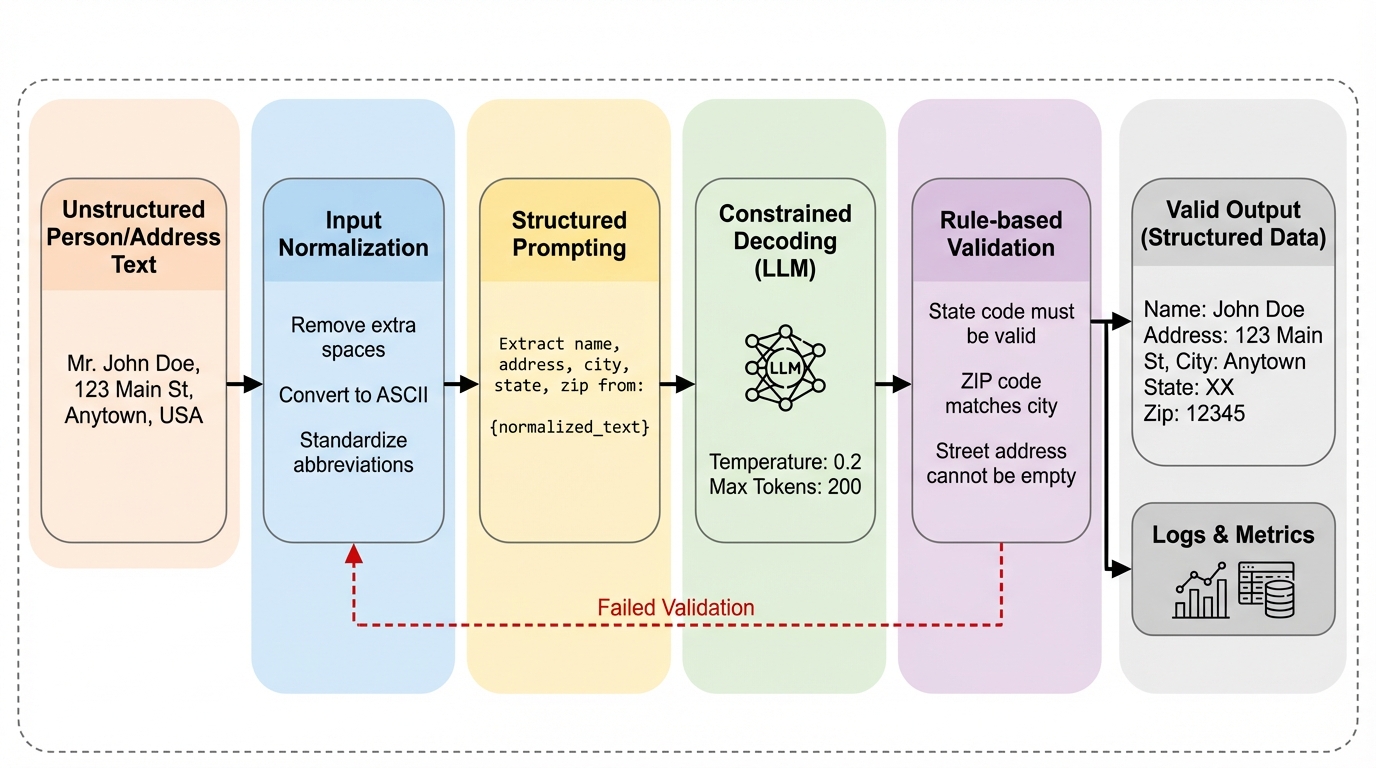
非構造化された氏名や住所のテキストを、大規模言語モデルと決定論的な検証レイヤーを組み合わせることで、17項目の詳細なスキーマに変換する新しいフレームワークを提案しました。 追加のファインチューニングを一切行わず、入力の正規化、構造化されたプロンプト、制約付きデコード、そして厳格なルールベースの検証を統合することで、99.8%という極めて高い解析精度を達成しています。 このシステムは、多言語対応や誤字脱字への耐性を持ちながら、郵便番号と州の整合性チェックなどの実世界の制約を強制することで、大規模な情報システムにおける信頼性と再現性の高いデータ抽出を低コストで実現します。
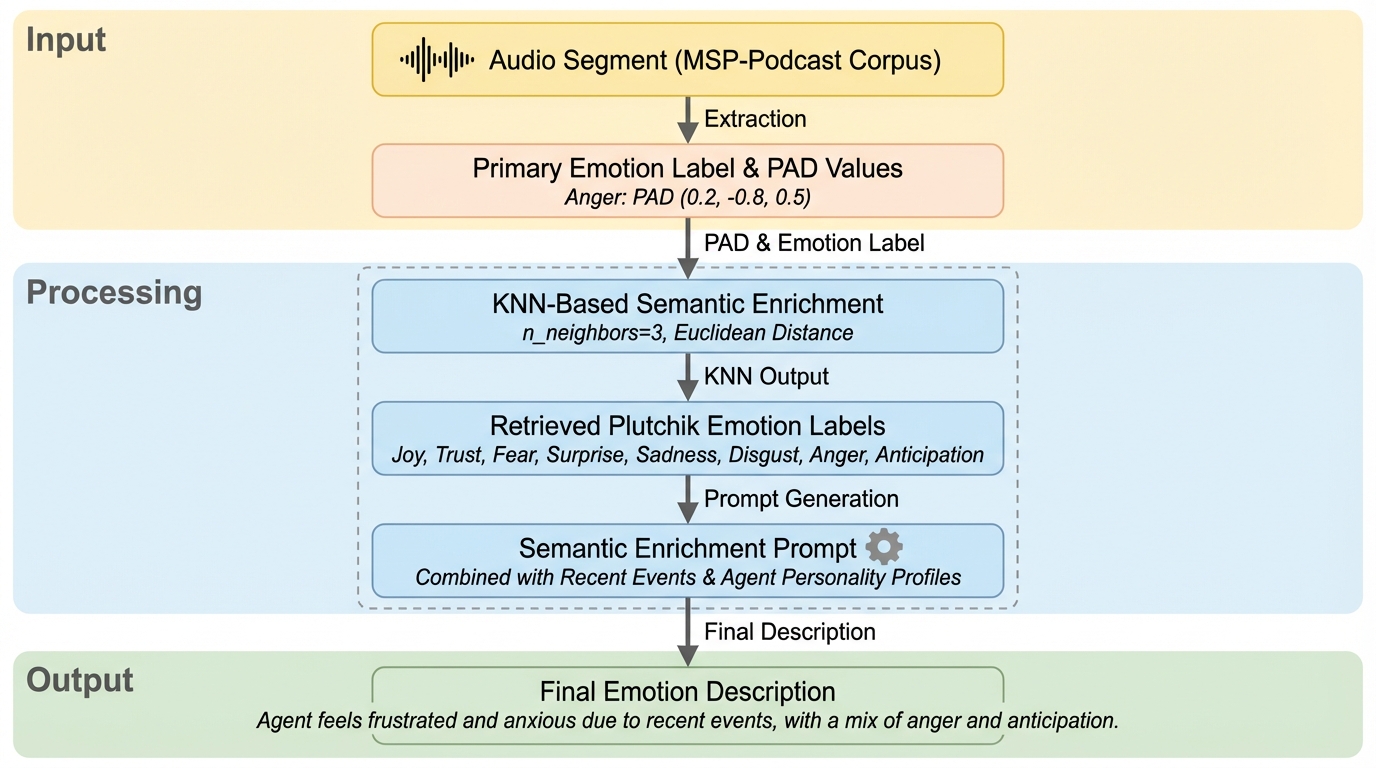
従来の大規模言語モデル(LLM)エージェントは、感情を一時的な信号としてのみ処理するため、長期的な対話において感情の一貫性が失われる「感情的健忘(emotional amnesia)」という深刻な課題を抱えていました。
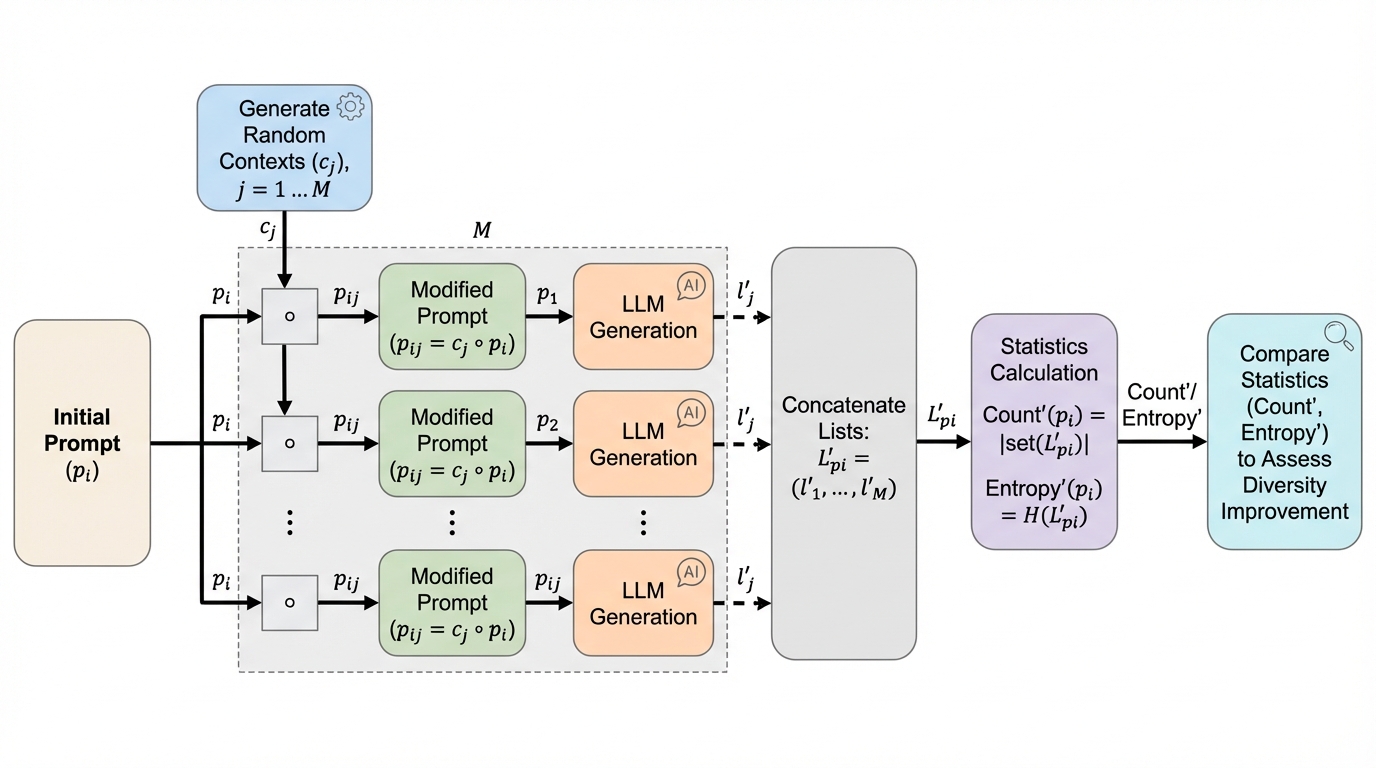
大規模言語モデル(LLM)が特定の一般的な回答ばかりを生成してしまう「ロングテール問題(モード崩壊)」に対し、プロンプトの先頭に無関係なランダムな単語や文章を付加するだけで、出力の多様性が統計的に有意に向上することを明らかにしました。
本論文は、バイリンガルが第二言語(L2)で文を作る際に第一言語(L1)の文法構造が干渉する「統語転移」の仕組みを、最新の神経計算モデル「ROSE」を用いて解明しています。具体的には、脳内の神経振動(オシレーション)の乱れが原因で、L1の強力なパターンがL2の計画を物理的に妨害する「サブスペース競合」と、文法要素を並べるタイミングがずれる「シーケンシング失敗」という2つの経路を提案しています。従来の脳波測定(ERP)では捉えきれなかった脳内の時間的・空間的な動態を明らかにすることで、言語間の干渉がどのように脳内で物理的に発生し、解決されるのかを説明する新しい理論的枠組みを提示しています。
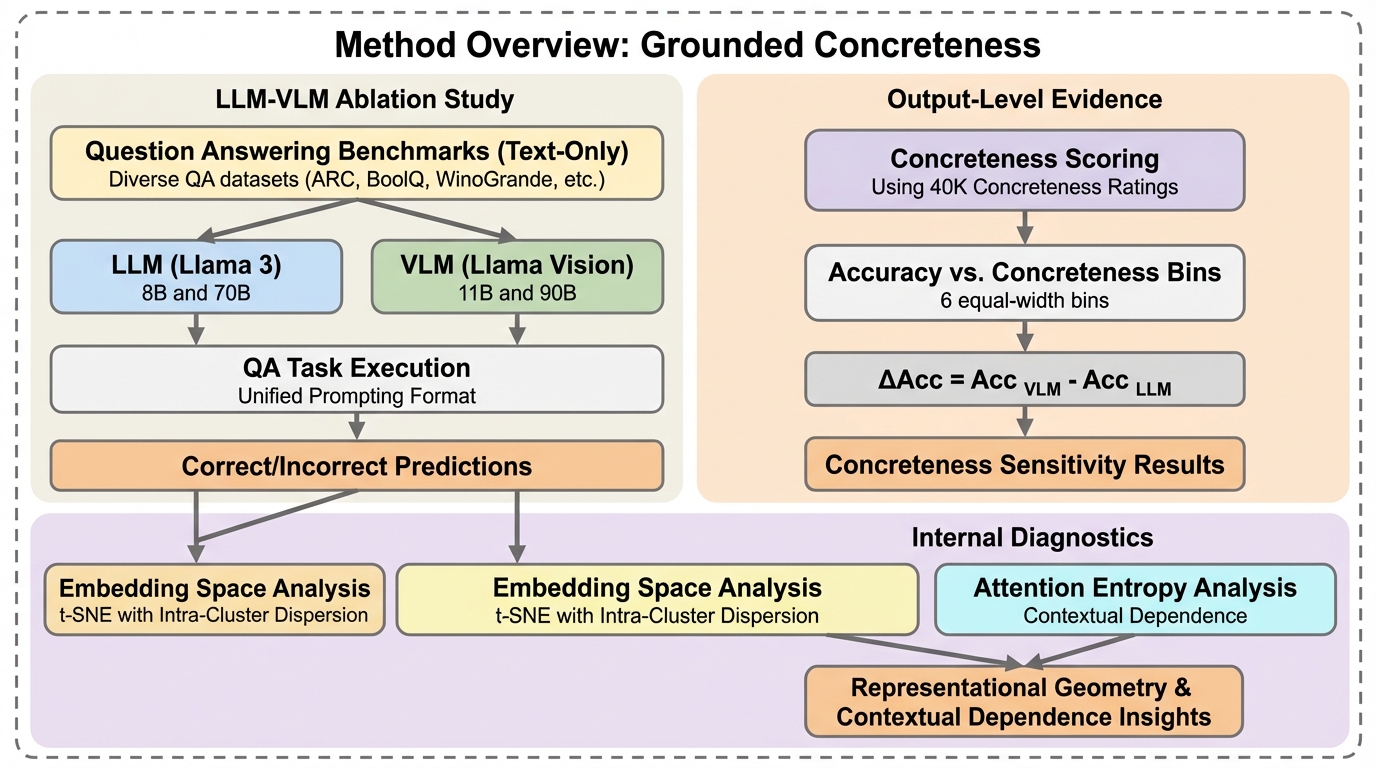
視覚と言語を統合して学習したモデル(VLM)が、テキストのみのモデル(LLM)と比較して、言葉の「具体性」に対して人間により近い感受性を持つかを、Llamaシリーズを用いた制御された比較実験によって検証した。
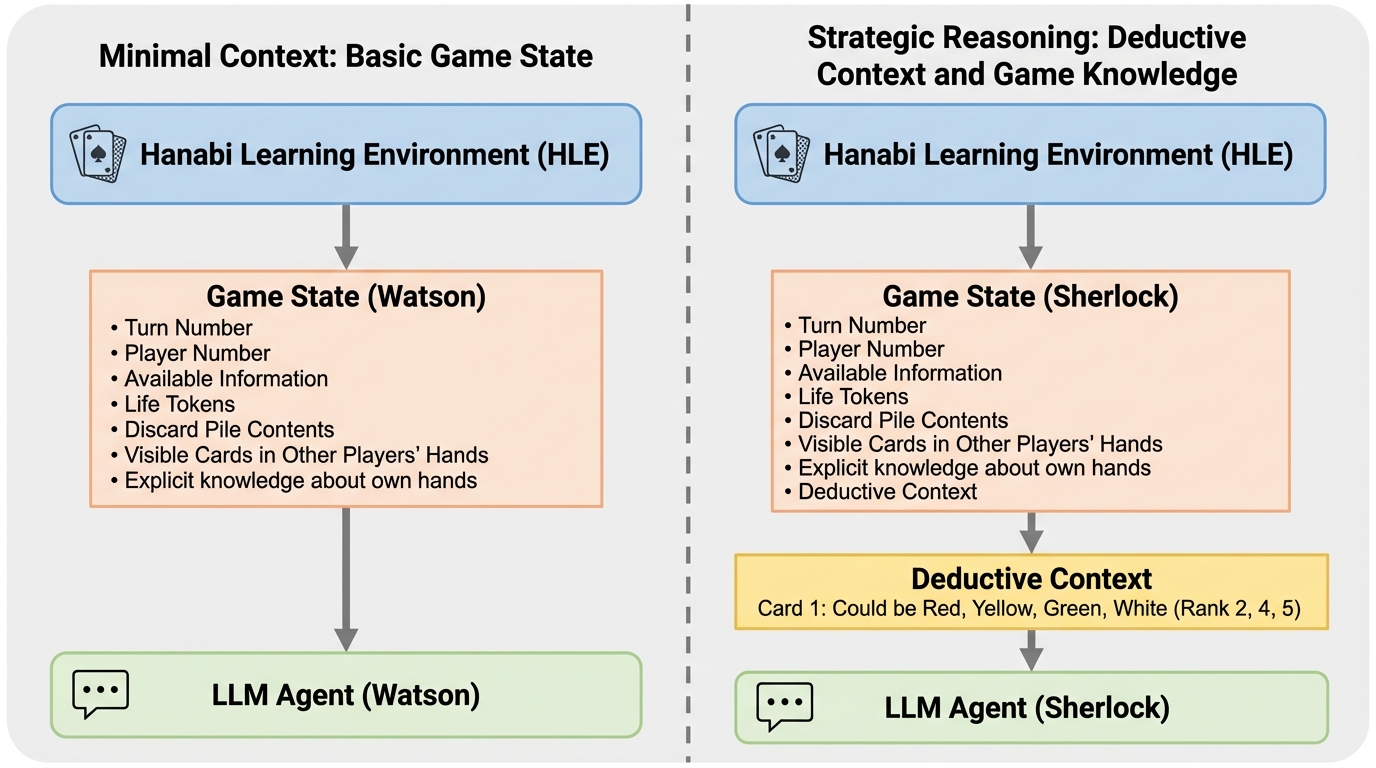
大規模言語モデル(LLM)を対象に、不完全情報下での高度な協調が必要なカードゲーム「花火(Hanabi)」を用いた過去最大規模の評価を実施し、最新の推論モデルが25点満点中平均15点から18点という高いスコアを記録することを明らかにした。