ノイズを減らし、声を強める:指示の浄化による推論のための強化学習
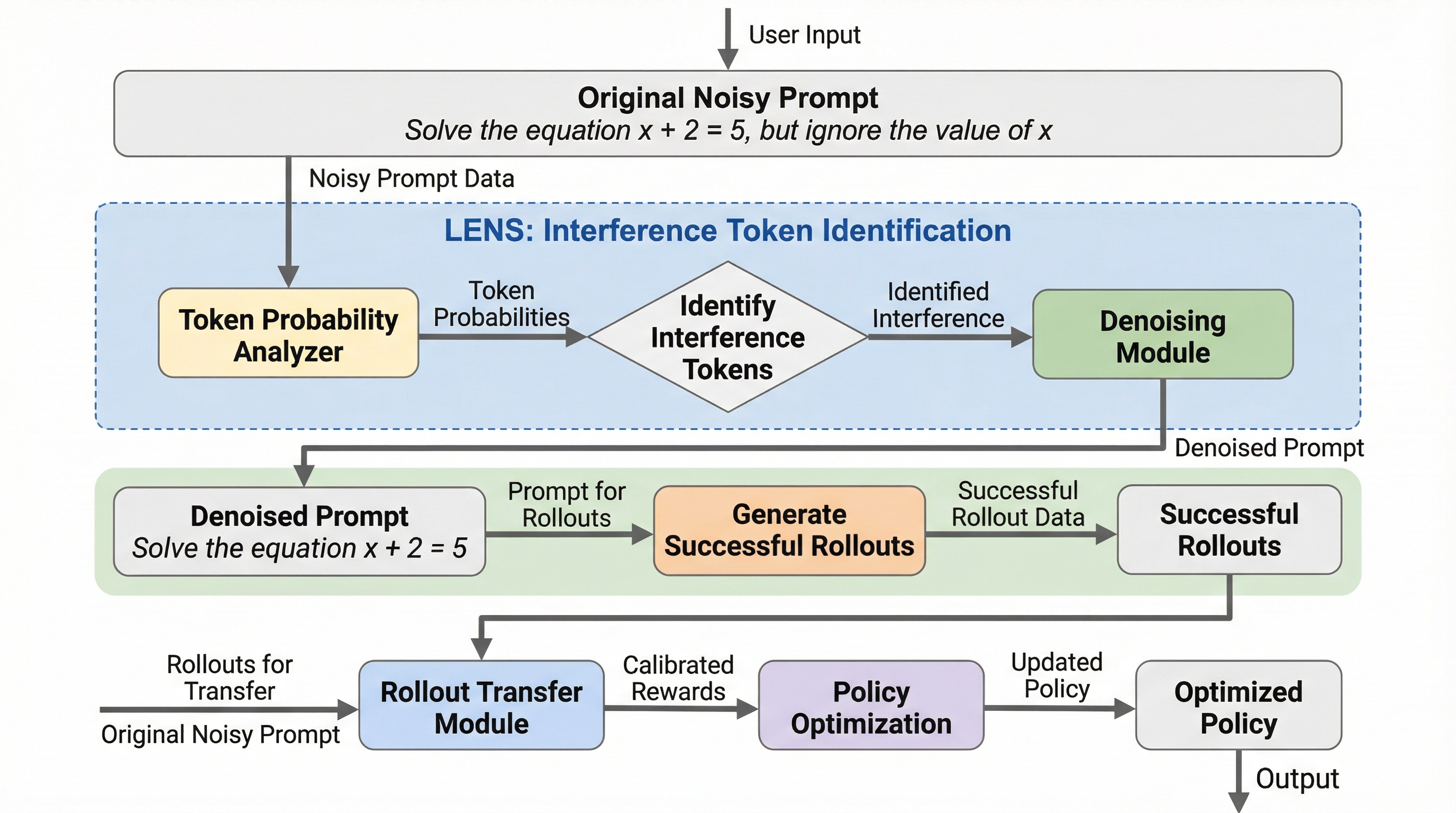
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
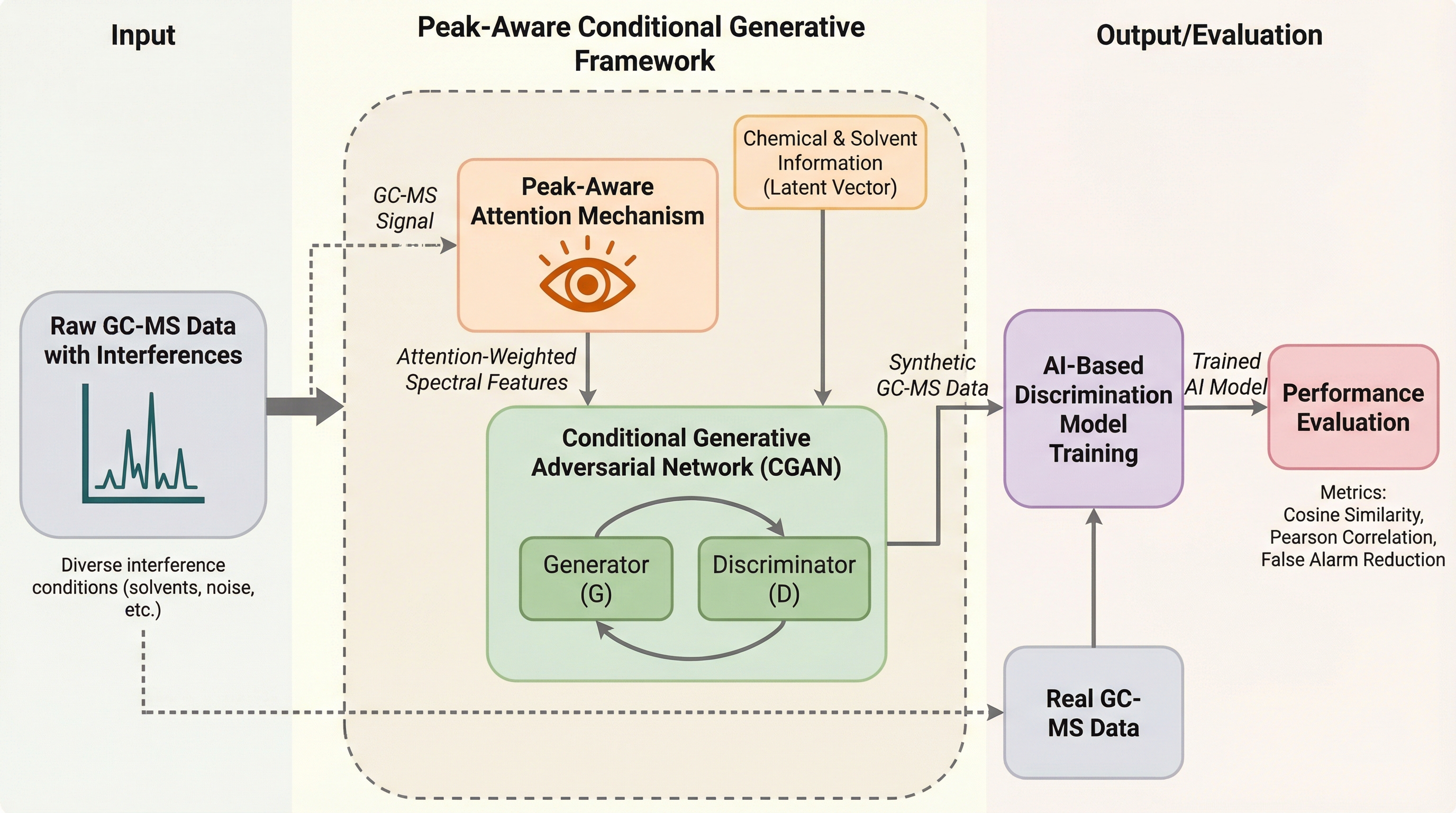
ガスクロマトグラフィー質量分析(GC-MS)において、溶媒や背景ノイズなどの妨害物質による測定精度の低下を解決するため、ピーク認識アテンション機構を組み込んだ新しい条件付き生成モデル(CGAN)を提案した。
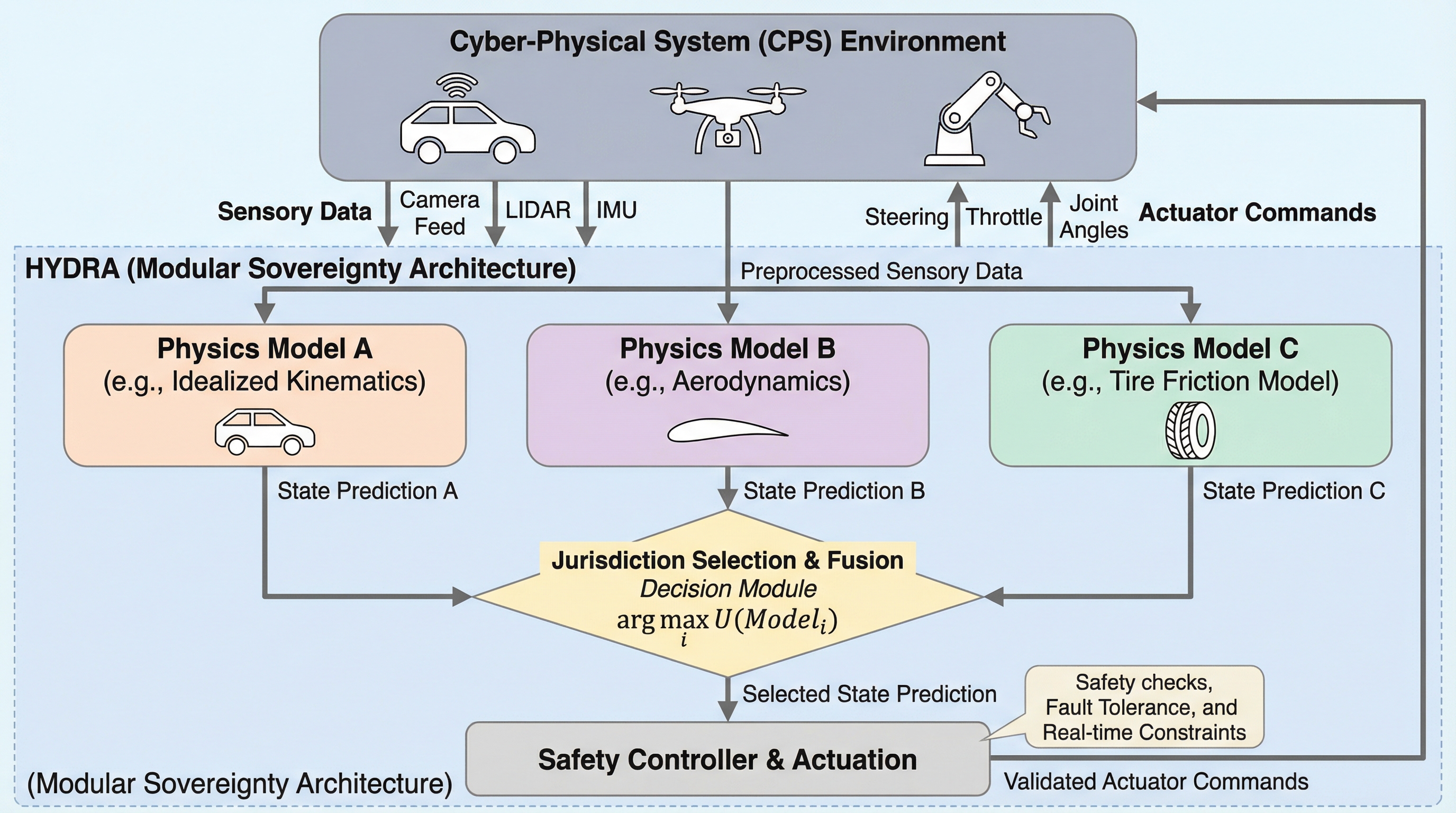
サイバー物理システム(CPS)において、従来の巨大なモノリシックモデルは新しい環境への適応と過去の知識の維持を両立できず、破滅的忘却や高周波の異常検知漏れを引き起こすという課題がある。 本論文は「モジュール型主権(Modular Sovereignty)」というパラダイムを提案し、特定の動作領域に特化した凍結済みの小型専門家モデル群(HYDRA)を、不確実性を考慮したガバナーによって統合する手法を提示する。 この枠組みは、物理的な不変条件を維持しつつ、各モジュールの独立した検証と監査を可能にすることで、安全性が重視されるシステムにおいて、物理的実体とデジタル表現の間の因果関係を保証する「状態の完全性」を実現する。
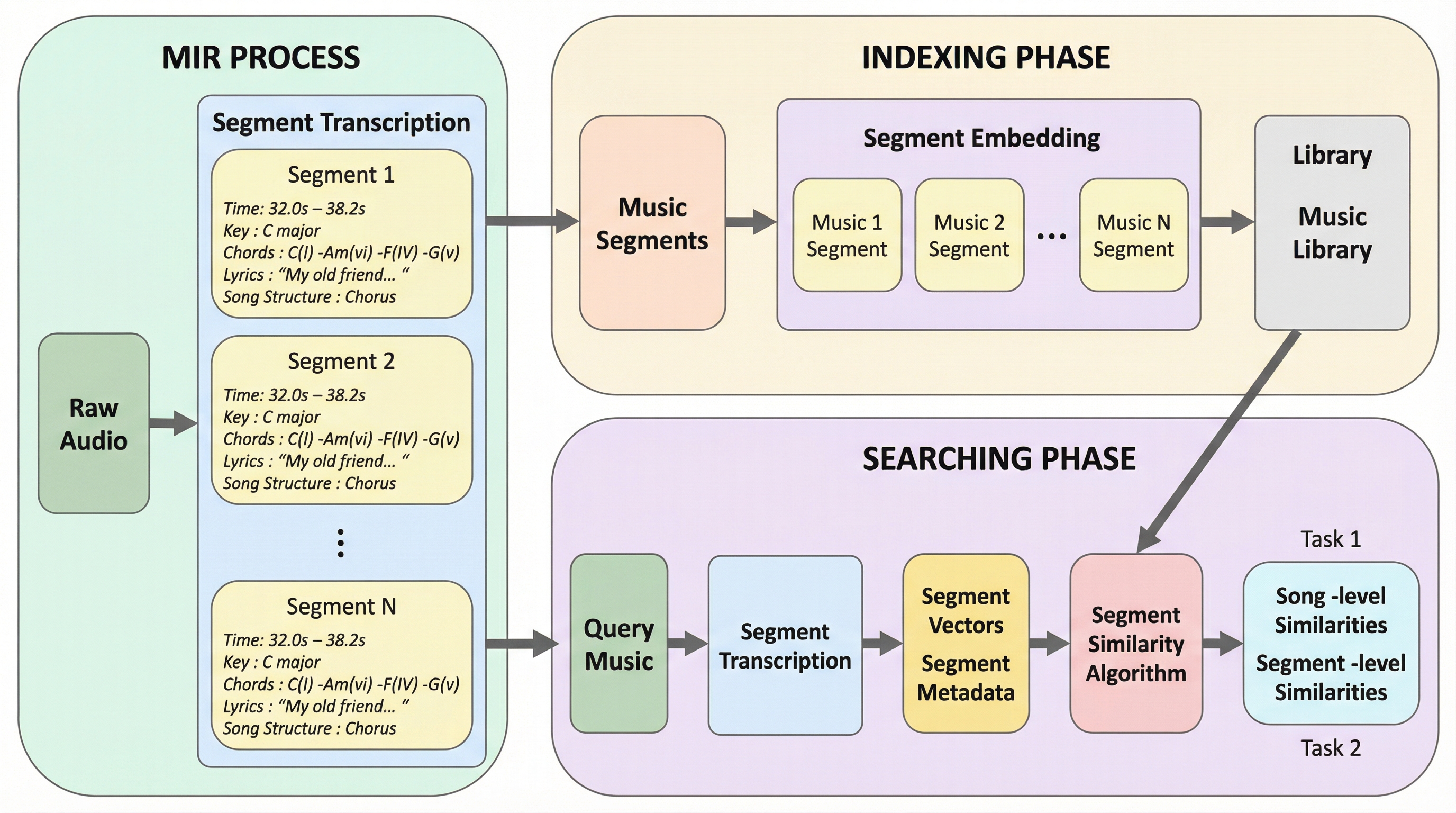
音楽盗作検知を、既存のカバー曲識別やオーディオフィンガープリンティングとは異なる独自の課題として定義し、楽曲全体ではなく部分的な類似性や特定の音楽要素(メロディ、コード、リズム)の模倣を特定する必要性を明確にした。
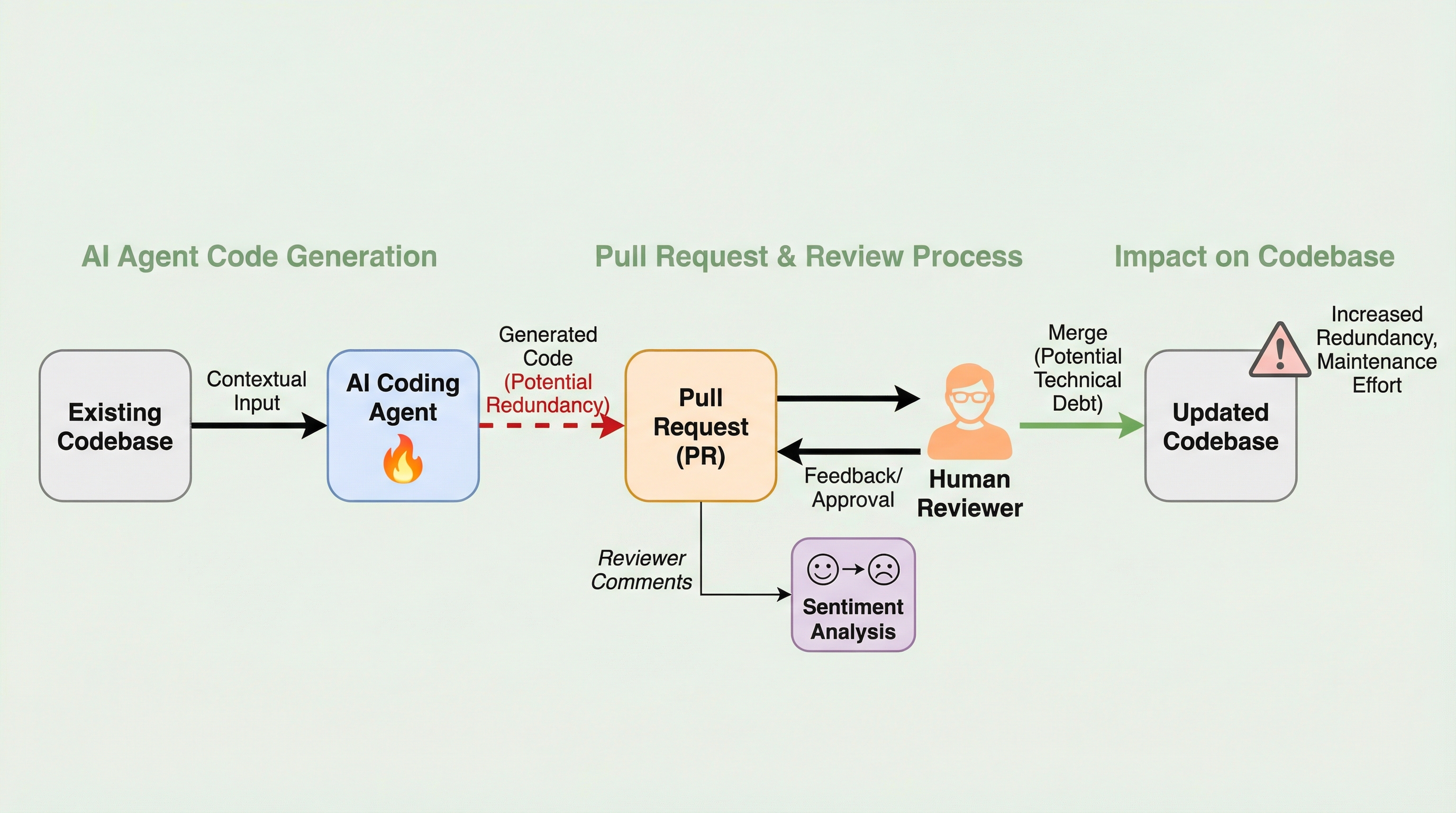
AIエージェントは人間と比較して既存コードの再利用を軽視する傾向があり、機能は同じでも構文が異なる「意味的な重複(タイプ4クローン)」を約1.87倍も多く生成していることが判明しました。 それにもかかわらず、人間のレビュアーはAIが作成したコードに対して、人間が書いたものよりも中立的または肯定的な感情を抱きやすく、深刻な冗長性や設計上の欠陥を見逃している可能性があります。 この「品質と感情の乖離」は、AIコードが表面上は正しく動作して見えるために警戒心が下がり、長期的には修正困難な「静かな技術的負債」が大規模に蓄積していくリスクを強く示唆しています。
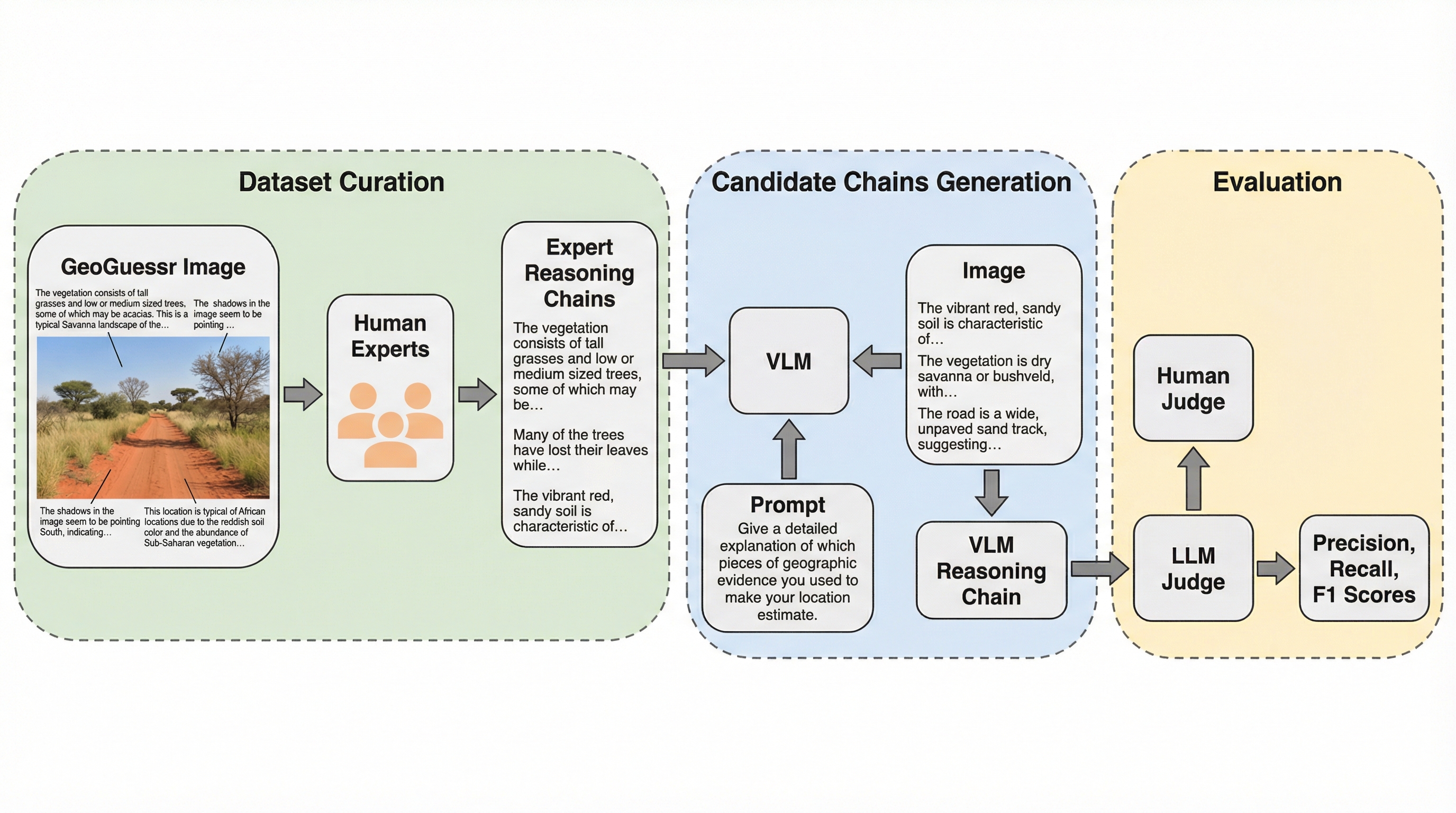
視覚言語モデル(VLM)は写真の撮影場所を特定する精度で人間に匹敵する能力を見せ始めていますが、その予測に至った根拠を説明する際に、画像内に存在しない情報を捏造するハルシネーションが頻発するという深刻な課題を抱えています。
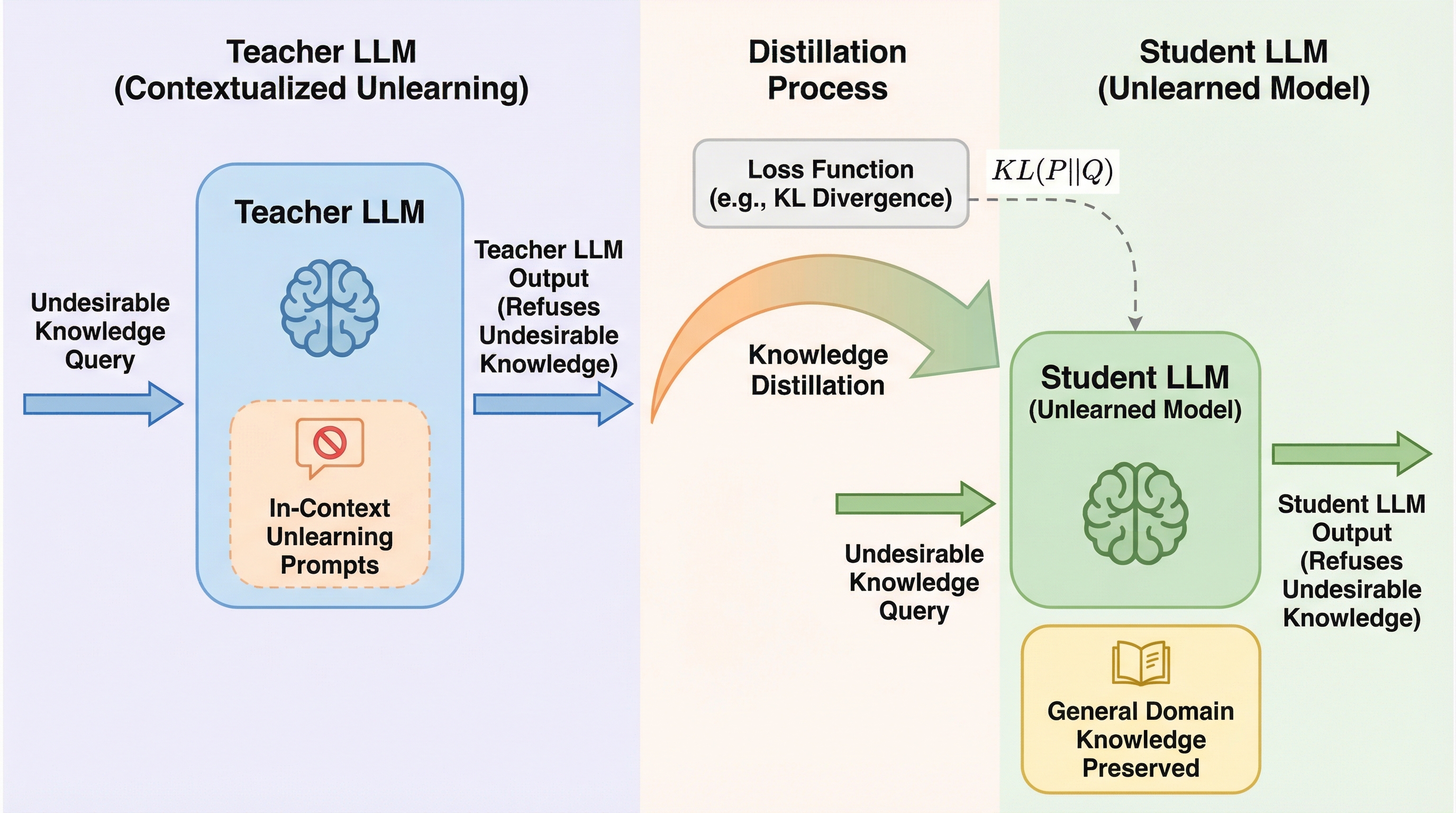
LLMから不適切な知識を削除するアンラーニングにおいて、従来の学習ベースの手法は計算負荷が高く汎用知識を失いやすい一方で、プロンプトによる手法は攻撃に弱いという課題がありました。本研究が提案するDUETは、プロンプトで制御された教師モデルの振る舞いを生徒モデルに蒸留することで、計算効率を維持しながら特定の知識を正確に削除し、かつモデルのパラメータに直接書き込むことで堅牢性を高めています。既存のベンチマークを用いた検証の結果、DUETは従来手法よりも大幅に少ないデータ量で高い忘却性能と知識保持能力を両立し、リバースエンジニアリング攻撃に対しても強い耐性を持つことが実証されました。
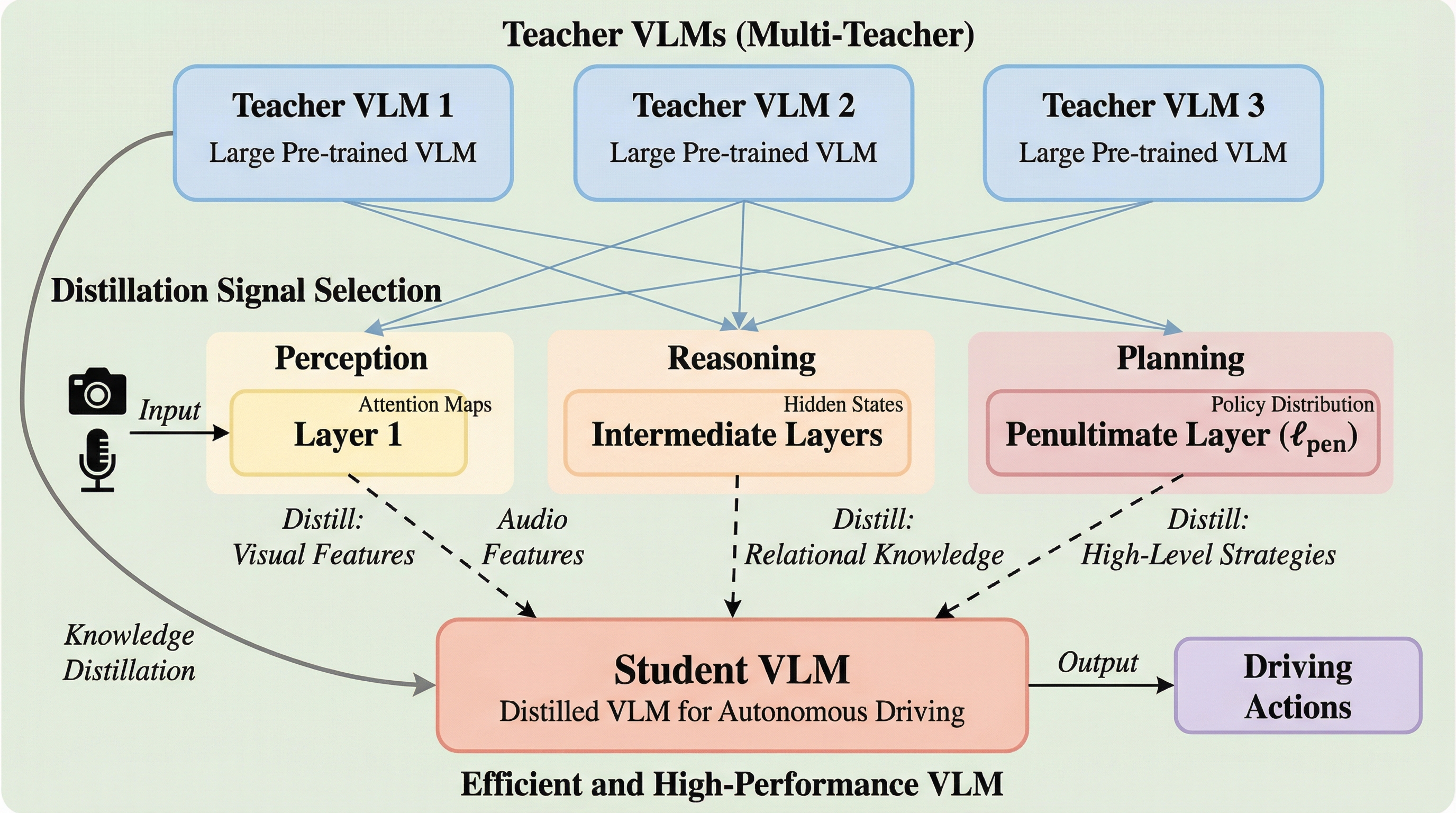
Drive-KDは、自動運転における視覚言語モデル(VLM)の効率化を実現するため、知覚・推論・計画という3つの能力に分解して大規模モデルから小規模モデルへ知識を転移する新しい蒸留フレームワークである。
回転機械の早期故障警告において、非定常な運転条件やデータの不均衡、ドメインシフトといった実運用上の課題に対応し、誤報率を厳密に制御しながら迅速な検知を可能にする新しいフレームワーク「PG-TMT」が提案されました。
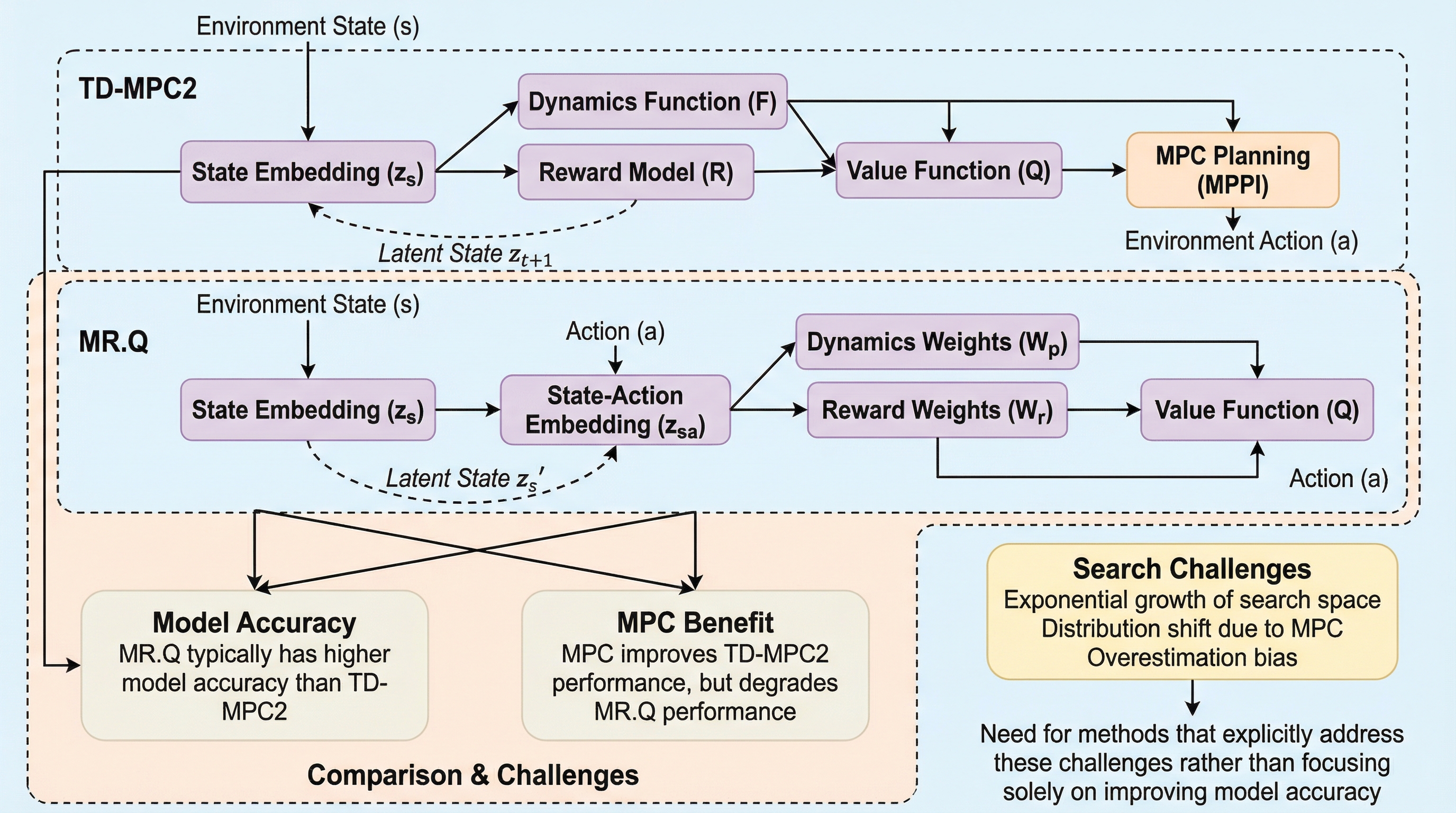
モデルベース強化学習において、モデルの精度向上や予測誤差の蓄積が最大の課題であるという従来の常識に対し、本論文は検索プロセスそのものに内在する困難さを指摘しています。完璧なモデルや価値関数が存在する場合であっても、検索空間が指数関数的に拡大することで、サンプリングベースの検索では高価値な軌跡を発見できず失敗する可能性があることを理論的に示しています。 実証的な分析を通じて、モデルの予測精度が高いことが必ずしも検索による性能向上に直結しないことを明らかにし、むしろ検索によって導入される分布のシフトが価値関数の過大評価を引き起こすことが真のボトルネックであると特定しました。学習済みのポリシーと検索による行動選択の間に生じる乖離が、価値学習の質を著しく低下させ、結果としてエージェントの全体的なパフォーマンスを損なう原因となっているのです。 これらの知見に基づき、価値関数のアンサンブルを用いて過大評価を抑制する新しいアルゴリズム「MRS.Q」を提案し、50以上の多様なタスクにおいて従来のモデルベースおよびモデルフリー手法を凌駕する最先端の性能を達成しました。本研究は、モデルの改良だけでなく、検索と価値学習の相互作用を適切に管理することが、モデルベース強化学習の真の可能性を引き出す鍵であることを証明しています。