Drive-KD: 自動運転VLMのためのマルチティーチャー知識蒸留
Drive-KDは、自動運転における視覚言語モデル(VLM)の効率化を実現するため、知覚・推論・計画という3つの能力に分解して大規模モデルから小規模モデルへ知識を転移する新しい蒸留フレームワークである。
TL;DR(結論)
Drive-KDは、自動運転における視覚言語モデル(VLM)の効率化を実現するため、知覚・推論・計画という3つの能力に分解して大規模モデルから小規模モデルへ知識を転移する新しい蒸留フレームワークである。特定の層における注意機構(アテンション)を蒸留信号として抽出し、複数の教師モデルから得られる異なる能力の勾配衝突を「非対称勾配投影(AGP)」によって解消することで、学習の安定性と高い性能の両立に成功している。実証実験では、蒸留された10億パラメータのモデルが、780億パラメータの巨大モデルと比較してGPUメモリを約42分の1に削減しつつ、DriveBenchにおいて総合性能で上回り、計画能力ではGPT-5.1を凌駕する成果を達成した。
なぜこの問題か
自動運転は極めて複雑かつ安全性が重視される領域であり、近年の大規模言語モデル(LLM)や視覚言語モデル(VLM)の進展は、この分野における推論や計画の新たな可能性を切り拓いている。しかし、これらの大規模なモデルは膨大なGPUメモリを要求し、推論の遅延も大きいため、リソースが限られたエッジデバイスやリアルタイム性が求められる車両への搭載には大きな障壁が存在する。従来の解決策として、物体検出や軌道計画を個別のサブモジュールに分割するモジュール方式があるが、これは各段階でエラーが蓄積しやすいという課題を抱えている。一方で、センサー入力を直接制御コマンドに変換するエンドツーエンドの学習方式も存在するが、解釈可能性が低く、複雑な環境下では脆弱になりやすいという欠点がある。 小規模なモデルに対して教師あり微調整(SFT)を行う手法も試みられているが、大規模モデルとの能力差を埋めるには不十分であることが多い。知識蒸留(KD)は大規模な教師モデルから小規模な生徒モデルへ知識を転移する有効な手法であるが、自動運転VLMにおいてどの層のどのような信号を蒸留すべきかという体系的な研究はこれまで不足していた。…
核心:何を提案したのか
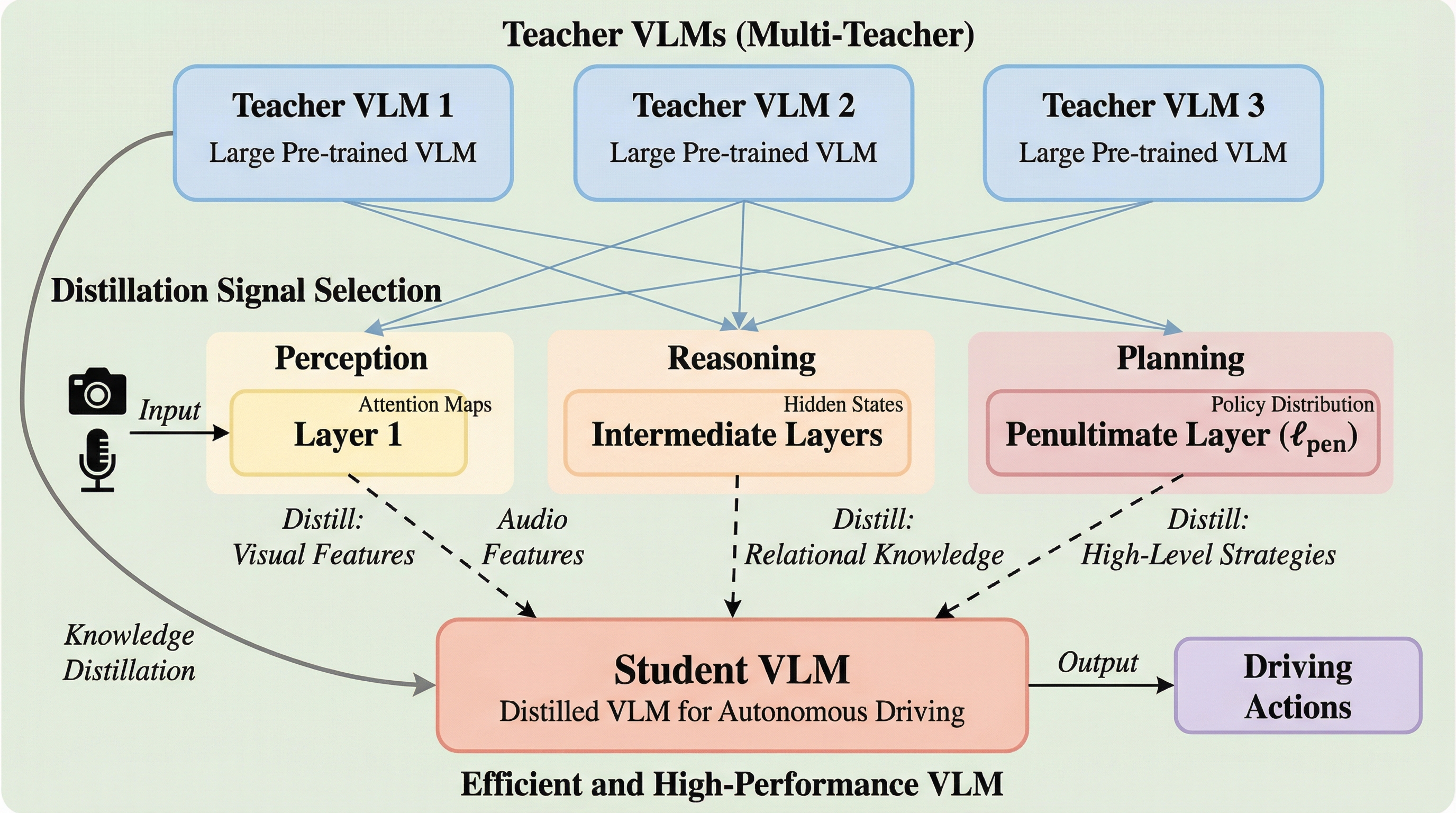
本論文では、自動運転の思考プロセスを「知覚(Perception)」「推論(Reasoning)」「計画(Planning)」という3つの連続した能力の三和音(トリアド)として定義し、これらを効果的に転移する「Drive-KD」フレームワークを提案している。Drive-KDの核心は、各能力に特化した複数の教師モデルから生徒モデルへ知識を流し込むマルチティーチャー蒸留の仕組みにある。まず、モデルの内部表現と能力の安定性の両面から分析を行い、各能力を蒸留するために最も情報量の多い特定の層を特定している。具体的には、知覚には初期層、推論には中間層、計画には最後から2番目の層(ペナルティメイト層)が適していることを見出した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related