モデルベース強化学習における探索の驚くべき困難さ
モデルベース強化学習において、モデルの精度向上や予測誤差の蓄積が最大の課題であるという従来の常識に対し、本論文は検索プロセスそのものに内在する困難さを指摘しています。完璧なモデルや価値関数が存在する場合であっても、検索空間が指数関数的に拡大することで、サンプリングベースの検索では高価値な軌跡を発見できず失敗する可能性があることを理論的に示しています。 実証的な分析を通じて、モデルの予測精度が高いことが必ずしも検索による性能向上に直結しないことを明らかにし、むしろ検索によって導入される分布のシフトが価値関数の過大評価を引き起こすことが真のボトルネックであると特定しました。学習済みのポリシーと検索による行動選択の間に生じる乖離が、価値学習の質を著しく低下させ、結果としてエージェントの全体的なパフォーマンスを損なう原因となっているのです。 これらの知見に基づき、価値関数のアンサンブルを用いて過大評価を抑制する新しいアルゴリズム「MRS.Q」を提案し、50以上の多様なタスクにおいて従来のモデルベースおよびモデルフリー手法を凌駕する最先端の性能を達成しました。本研究は、モデルの改良だけでなく、検索と価値学習の相互作用を適切に管理することが、モデルベース強化学習の真の可能性を引き出す鍵であることを証明しています。
TL;DR(結論)
モデルベース強化学習において、モデルの精度向上や予測誤差の蓄積が最大の課題であるという従来の常識に対し、本論文は検索プロセスそのものに内在する困難さを指摘しています。完璧なモデルや価値関数が存在する場合であっても、検索空間が指数関数的に拡大することで、サンプリングベースの検索では高価値な軌跡を発見できず失敗する可能性があることを理論的に示しています。 実証的な分析を通じて、モデルの予測精度が高いことが必ずしも検索による性能向上に直結しないことを明らかにし、むしろ検索によって導入される分布のシフトが価値関数の過大評価を引き起こすことが真のボトルネックであると特定しました。学習済みのポリシーと検索による行動選択の間に生じる乖離が、価値学習の質を著しく低下させ、結果としてエージェントの全体的なパフォーマンスを損なう原因となっているのです。 これらの知見に基づき、価値関数のアンサンブルを用いて過大評価を抑制する新しいアルゴリズム「MRS.Q」を提案し、50以上の多様なタスクにおいて従来のモデルベースおよびモデルフリー手法を凌駕する最先端の性能を達成しました。本研究は、モデルの改良だけでなく、検索と価値学習の相互作用を適切に管理することが、モデルベース強化学習の真の可能性を引き出す鍵であることを証明しています。
なぜこの問題か
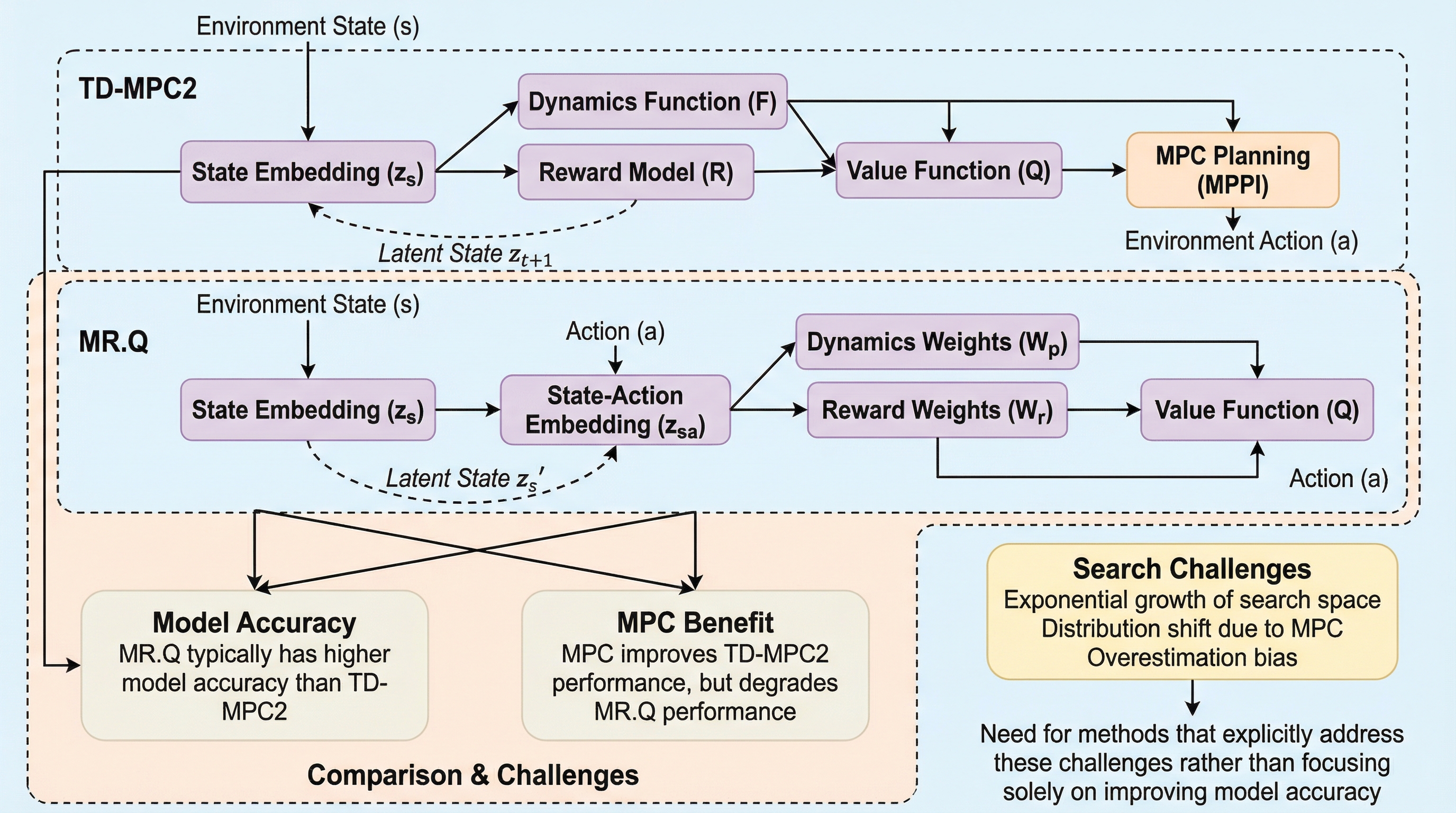
モデルベース強化学習(MBRL)は、複雑な環境においてサンプル効率の高い意思決定を実現するための有望なパラダイムとして長年期待されてきました。明示的なダイナミクスモデルを学習することで、エージェントは将来の軌跡をシミュレーションし、事前に計画を立てることが可能になります。これにより、現実世界での何百万回もの試行錯誤を必要とせずに、情報に基づいた意思決定を行えるようになると考えられてきました。しかし、概念的な魅力があるにもかかわらず、MBRLはモデルフリーの手法に対して有意な優位性を示すことにしばしば苦労してきました。 この性能不足に対する一般的な説明は、モデルの精度不足と予測誤差の蓄積(コンパウンディング・エラー)に集約されてきました。モデルを使用して長期間の軌跡をシミュレートすると、小さな予測誤差が蓄積し、状態推定が次第に信頼できなくなるという現象です。このため、これまでの研究の多くは、モデルの精度向上、不確実性を考慮したモデルの構築、あるいは長期予測の改善に焦点を当ててきました。これらの努力の根底には、より優れたモデルが直接的に優れた計画、ひいては優れたパフォーマンスにつながるという暗黙の仮定が存在していました。…
核心:何を提案したのか
本論文の核心的な提案は、検索の成功を左右するのはモデルの精度そのものではなく、検索と価値学習の相互作用、特に「分布のシフト」とそれに伴う「過大評価バイアス」をいかに管理するかであるという洞察です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related