DUET:効率的に文脈化された教師からの蒸留されたLLMアンラーニング
LLMから不適切な知識を削除するアンラーニングにおいて、従来の学習ベースの手法は計算負荷が高く汎用知識を失いやすい一方で、プロンプトによる手法は攻撃に弱いという課題がありました。本研究が提案するDUETは、プロンプトで制御された教師モデルの振る舞いを生徒モデルに蒸留することで、計算効率を維持しながら特定の知識を正確に削除し、かつモデルのパラメータに直接書き込むことで堅牢性を高めています。既存のベンチマークを用いた検証の結果、DUETは従来手法よりも大幅に少ないデータ量で高い忘却性能と知識保持能力を両立し、リバースエンジニアリング攻撃に対しても強い耐性を持つことが実証されました。
TL;DR(結論)
LLMから不適切な知識を削除するアンラーニングにおいて、従来の学習ベースの手法は計算負荷が高く汎用知識を失いやすい一方で、プロンプトによる手法は攻撃に弱いという課題がありました。本研究が提案するDUETは、プロンプトで制御された教師モデルの振る舞いを生徒モデルに蒸留することで、計算効率を維持しながら特定の知識を正確に削除し、かつモデルのパラメータに直接書き込むことで堅牢性を高めています。既存のベンチマークを用いた検証の結果、DUETは従来手法よりも大幅に少ないデータ量で高い忘却性能と知識保持能力を両立し、リバースエンジニアリング攻撃に対しても強い耐性を持つことが実証されました。
なぜこの問題か
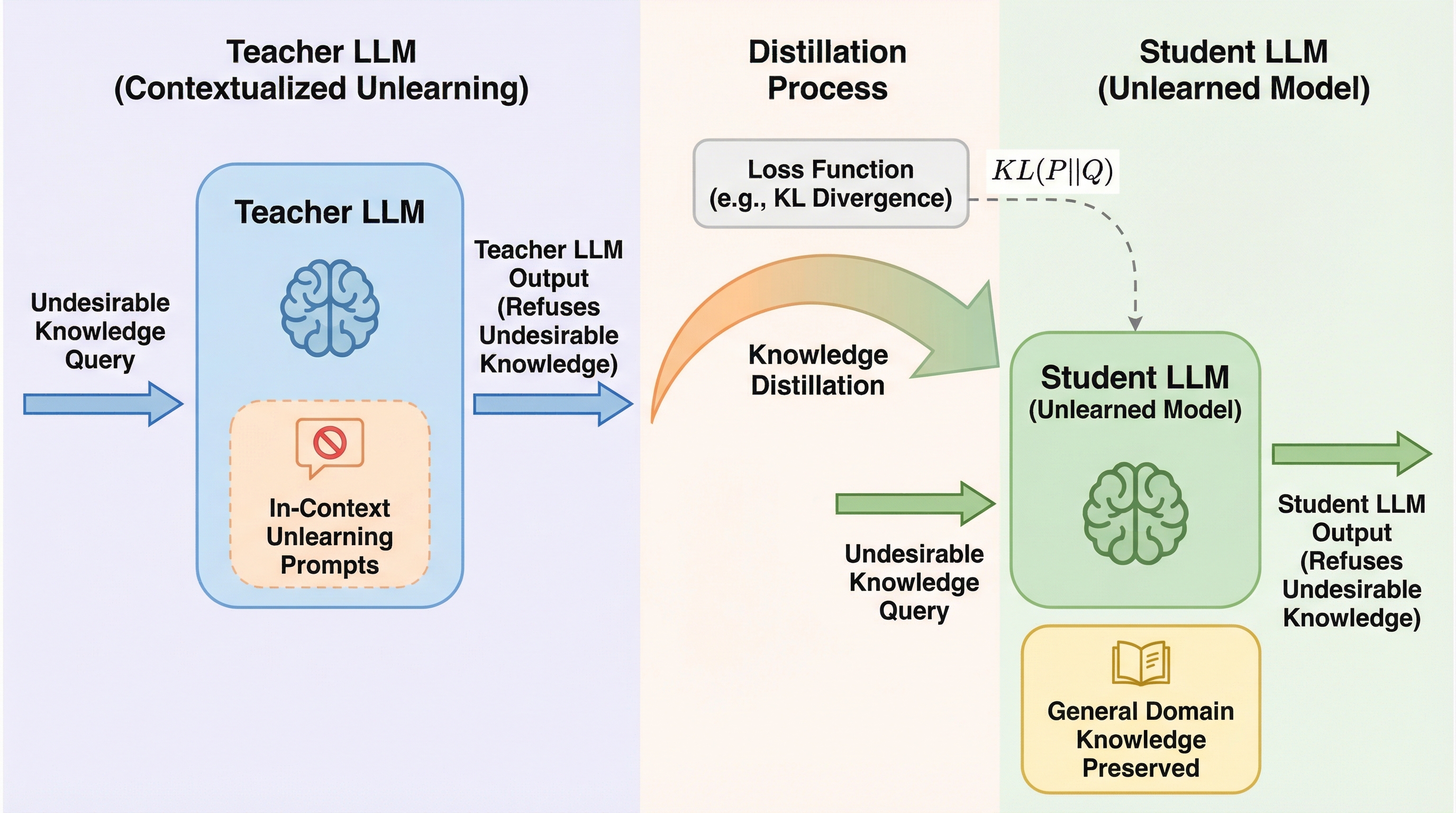
大規模言語モデル(LLM)は、膨大なデータを用いた事前学習を通じて驚異的な知能を獲得しますが、その副作用としてプライバシーに関わる個人情報や著作権で保護されたコンテンツ、さらには有害な知識まで記憶し、それを再現してしまうリスクを抱えています。信頼できるAIシステムを構築するためには、モデルを最初から再学習することなく、特定の不適切な知識の影響のみを取り除く「アンラーニング」技術が不可欠です。しかし、既存のアンラーニング手法には解決すべき大きな制限が存在します。 まず、勾配上昇法(GA)などの従来の手法は、削除対象の知識を表現するために大量の学習データを必要とし、計算負荷が非常に高くなります。さらに、削除すべきではない一般的な知識まで失ってしまう「破滅的忘却」を引き起こしやすく、モデルの全体的な性能を著しく損なう傾向があります。一方で、特定のプロンプトを用いてモデルの出力を制御する「インコンテキスト・アンラーニング」は、パラメータを更新しないため軽量で正確な制御が可能ですが、本質的な堅牢性に欠けています。…
核心:何を提案したのか
本研究では、効率的な教師モデルからの蒸留によるアンラーニング手法である「DUET(Distilled Unlearning from an Efficient Teacher)」を提案しました。この手法の核心は、インコンテキスト・プロンプトによって適切に制御された教師モデルの振る舞いを、生徒モデルであるターゲットLLMに模倣させることにあります。具体的には、特定の知識(例えばハリー・ポッターの物語など)を「知らない」と回答するように誘導された教師モデルのロジット分布の変化を、生徒モデルが学習します。これにより、プロンプトによる精密な制御能力を維持しつつ、その効果をモデルのパラメータとして直接定着させることができます。 DUETは、従来のアンラーニング手法が直面していた「忘却の徹底」と「汎用知識の保持」のトレードオフを、教師・生徒間の知識蒸留という枠組みで解決しようとしています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related