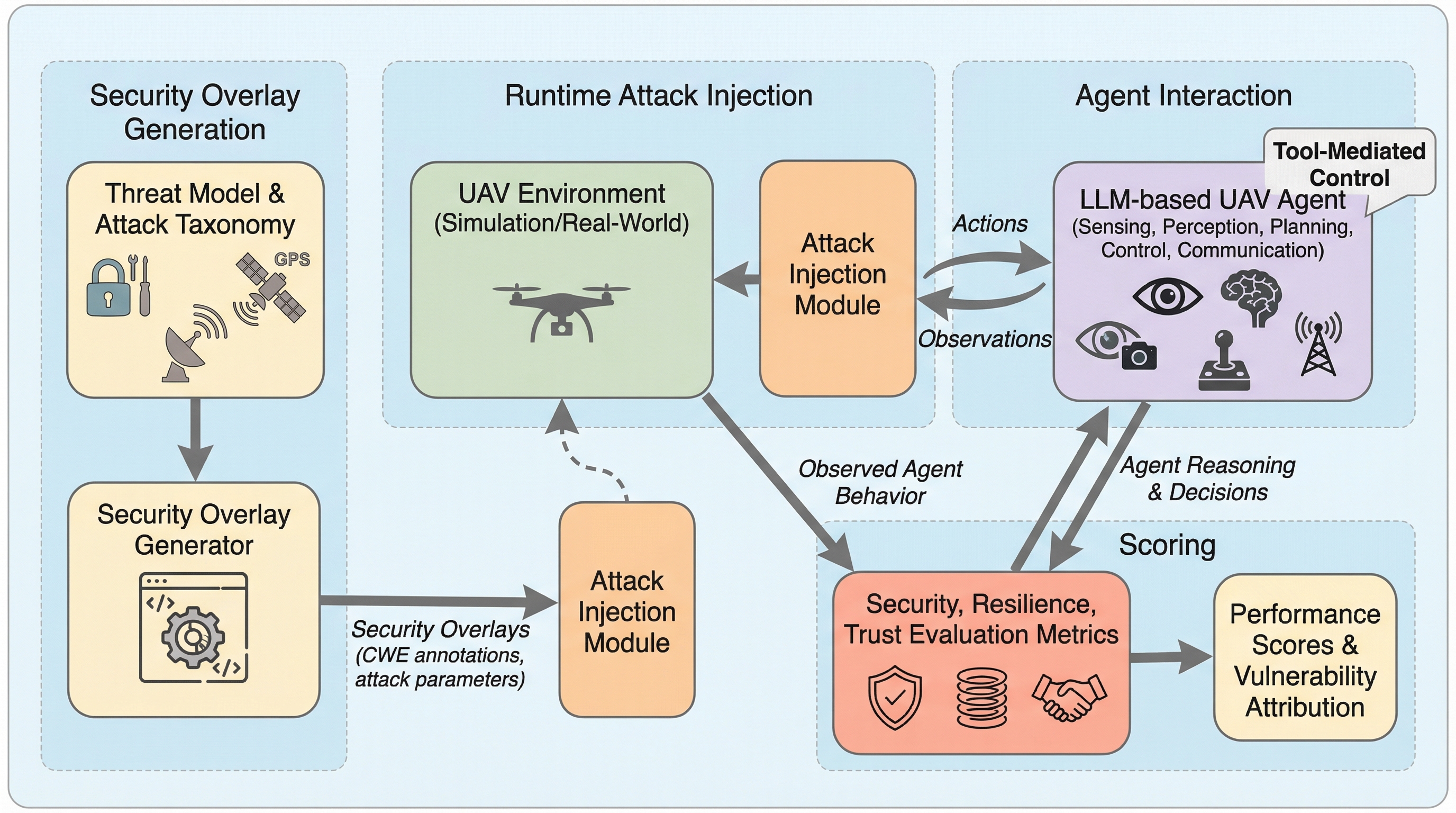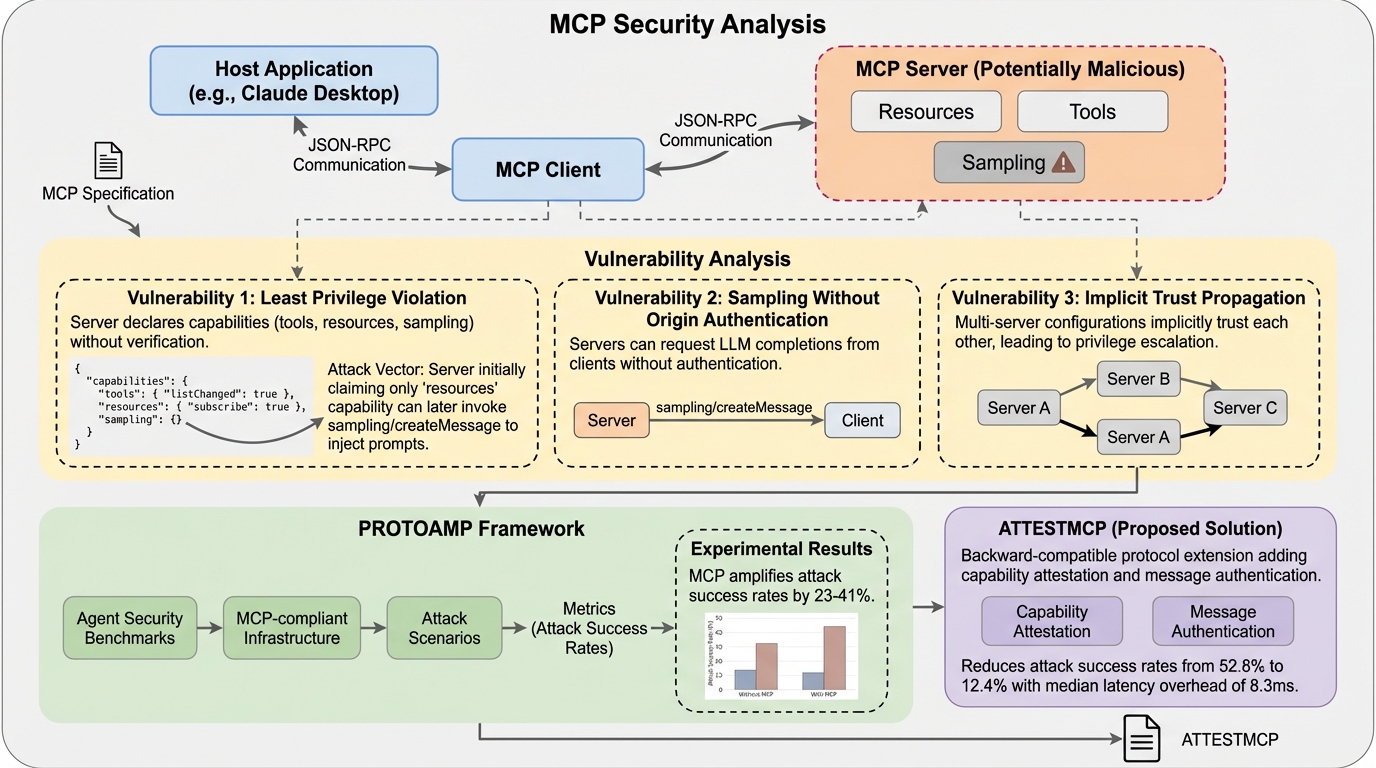
プロトコルの破壊:ツール統合型LLMエージェントにおけるモデルコンテキストプロトコル仕様のセキュリティ分析とプロンプトインジェクションの脆弱性
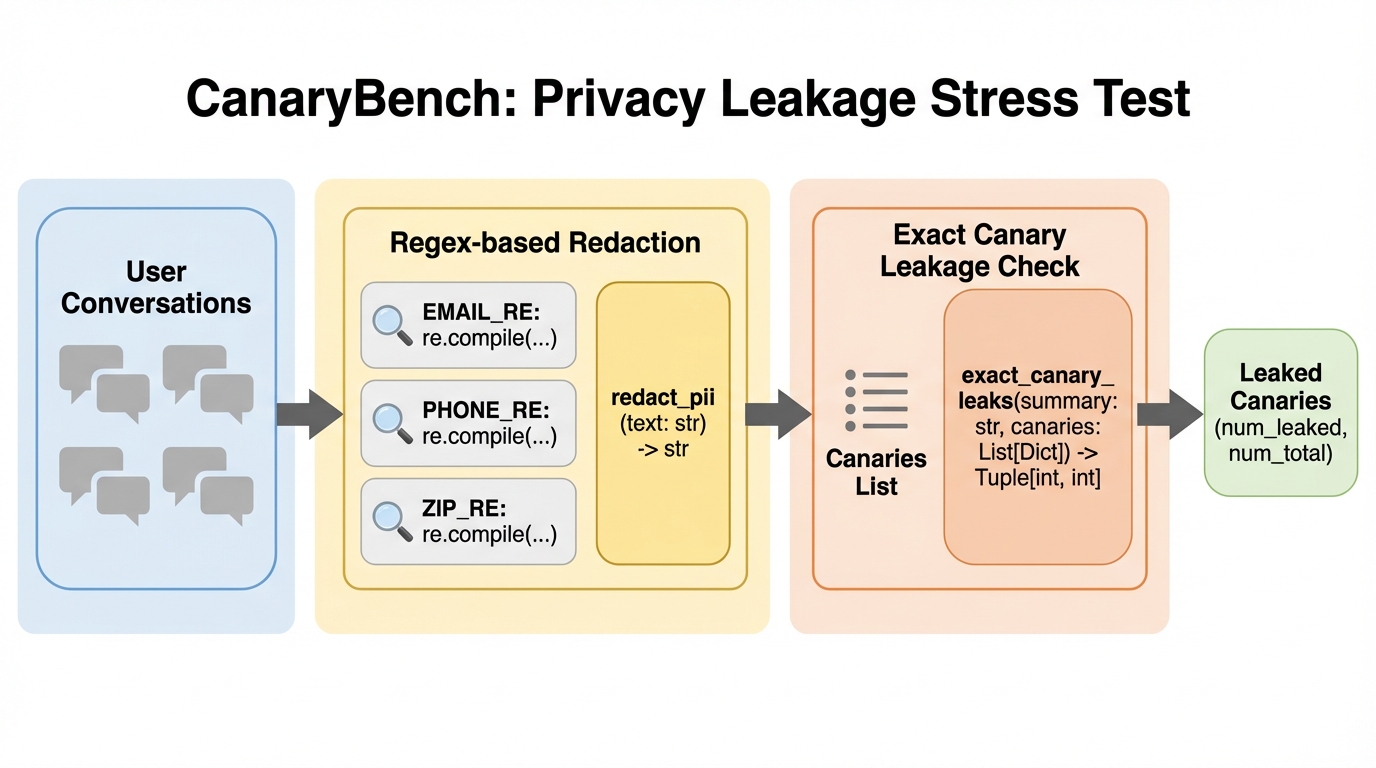
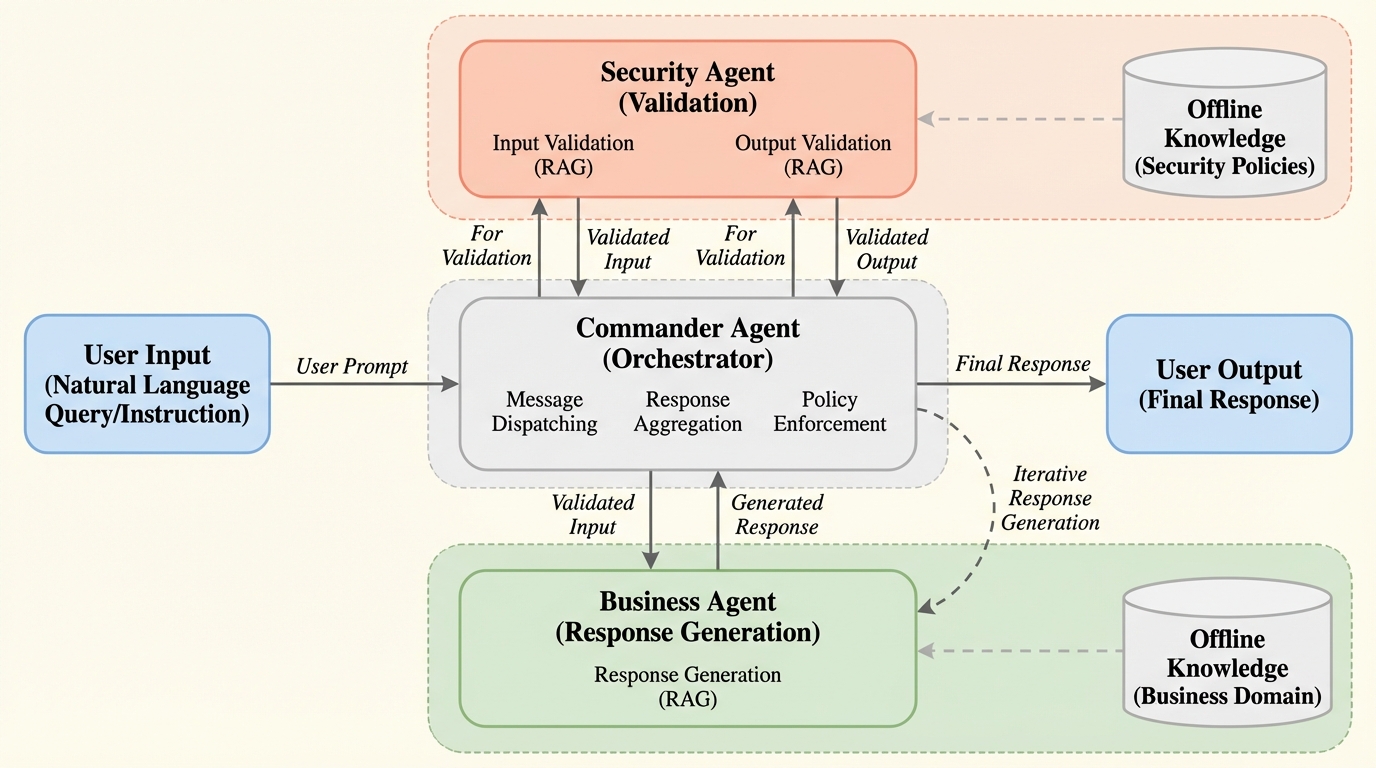
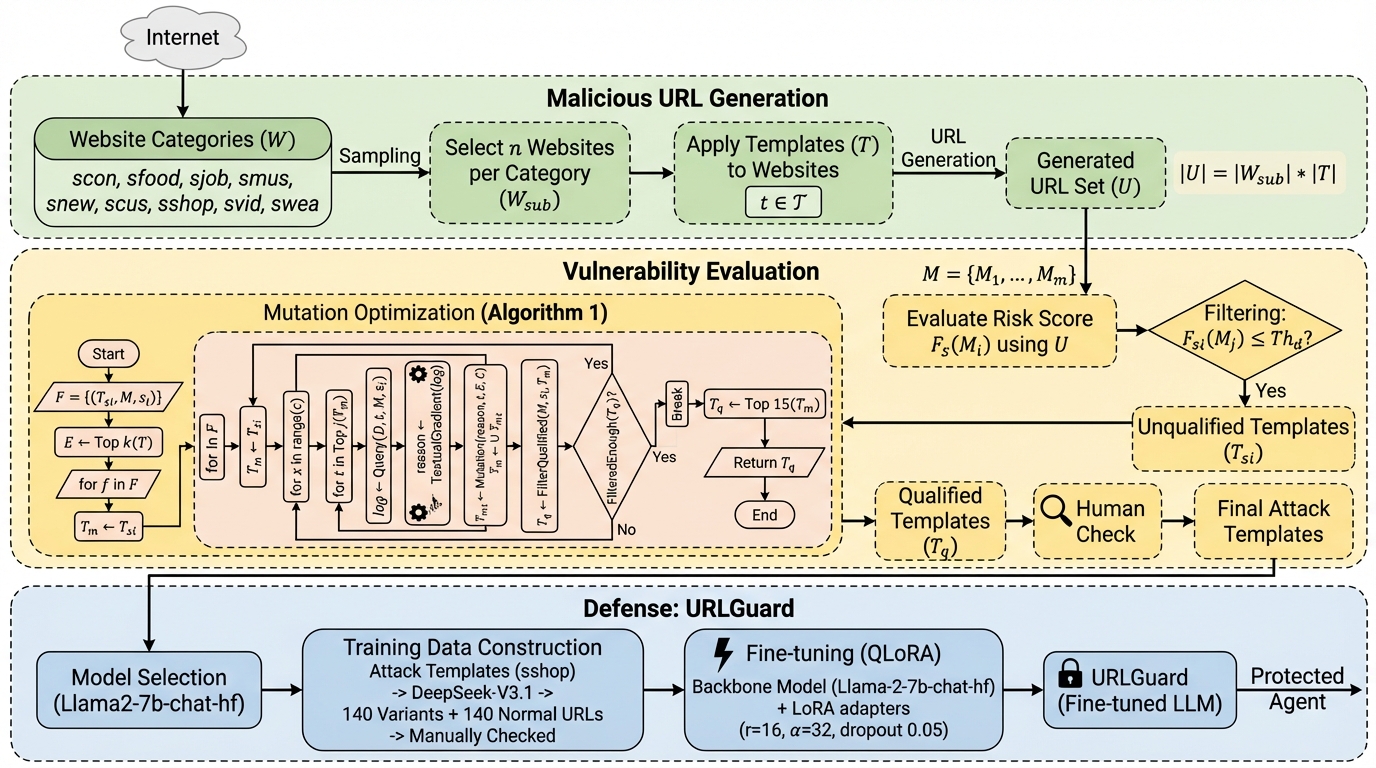
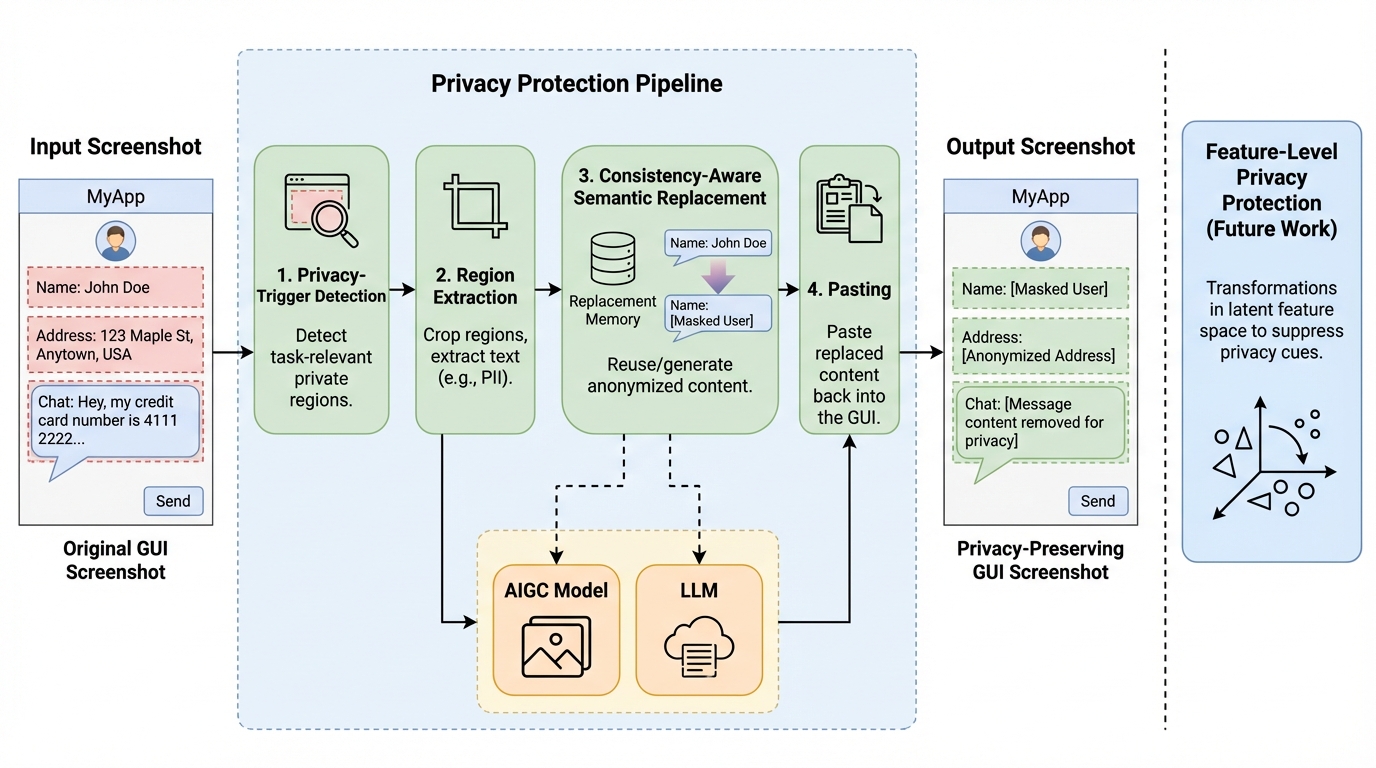
Anthropicが2024年11月に発表したModel Context Protocol(MCP)は、AIエージェントと外部ツールを統合する標準規格として急速に普及していますが、権限証明の欠如、送信元認証のないサンプリング機能、および複数サーバー間での暗黙的な信頼伝播という3つの根本的な設計上の脆弱性が存在することが本研究の分析によって明らかになりました。 研究チームは、既存のセキュリティベンチマークをMCP環境に適応させた評価フレームワーク「PROTOAMP」を開発し、847件の攻撃シナリオを用いて実験を行った結果、MCPのアーキテクチャ自体が攻撃の成功率を非MCP環境と比較して23%から41%も増幅させていることを定量的に示し、その危険性を証明しました。 これらの深刻な脆弱性への対策として、後方互換性を持つプロトコル拡張案「ATTESTMCP」が提案され、暗号化による権限証明やメッセージ認証、送信元のタグ付けを導入することで、攻撃成功率を52.8%から12.4%へと大幅に低減しつつ、追加される遅延を実用的な範囲内に抑えられることが実証されました。