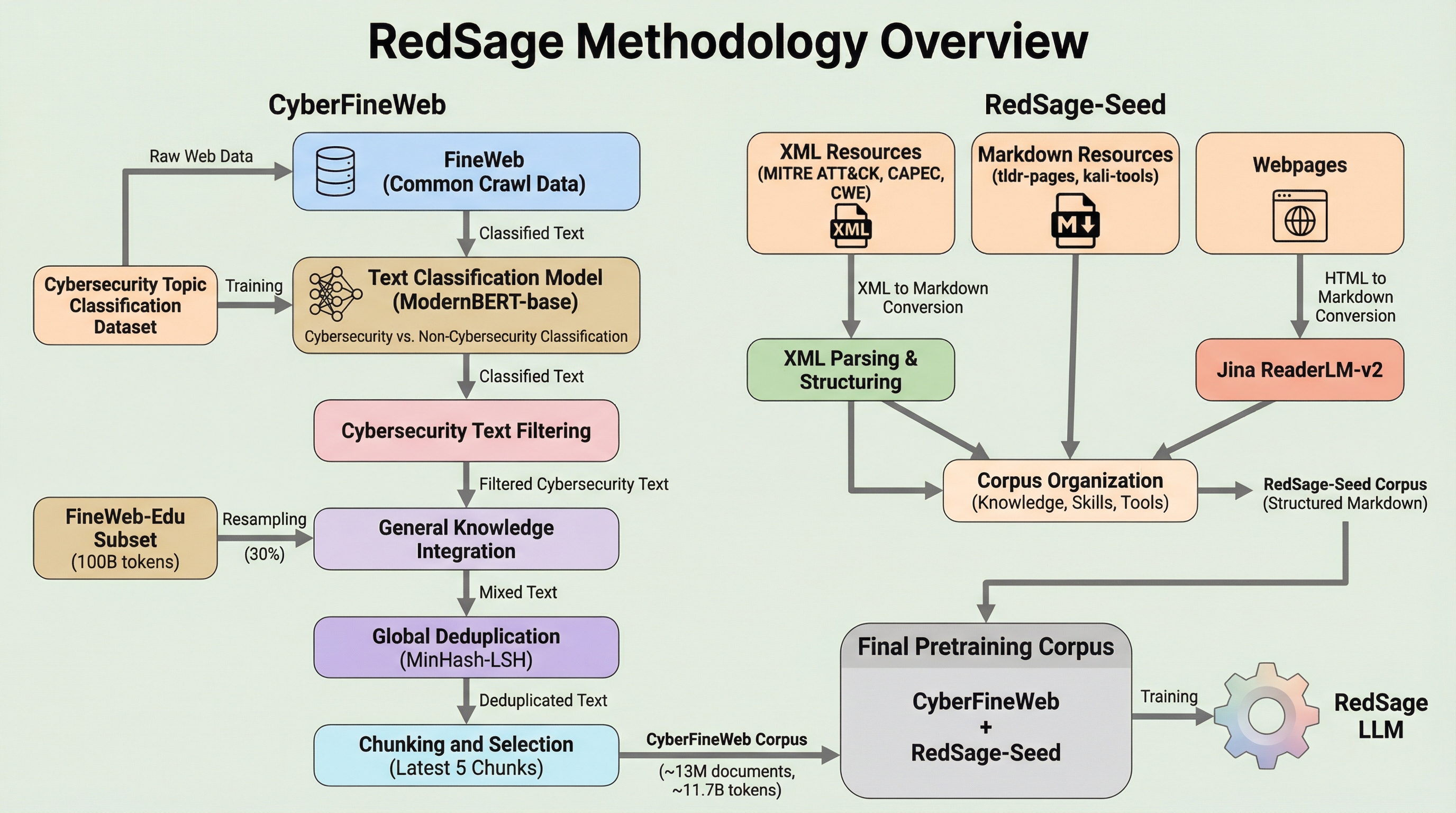
RedSage: サイバーセキュリティに特化した汎用LLM
RedSageは、11.8Bトークンの専門データを用いた継続事前学習と、エージェントによる266K件の高品質な対話データ拡充を組み合わせ、サイバーセキュリティ領域に特化したオープンソースの8Bパラメータモデルである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
RedSageは、11.8Bトークンの専門データを用いた継続事前学習と、エージェントによる266K件の高品質な対話データ拡充を組み合わせ、サイバーセキュリティ領域に特化したオープンソースの8Bパラメータモデルである。
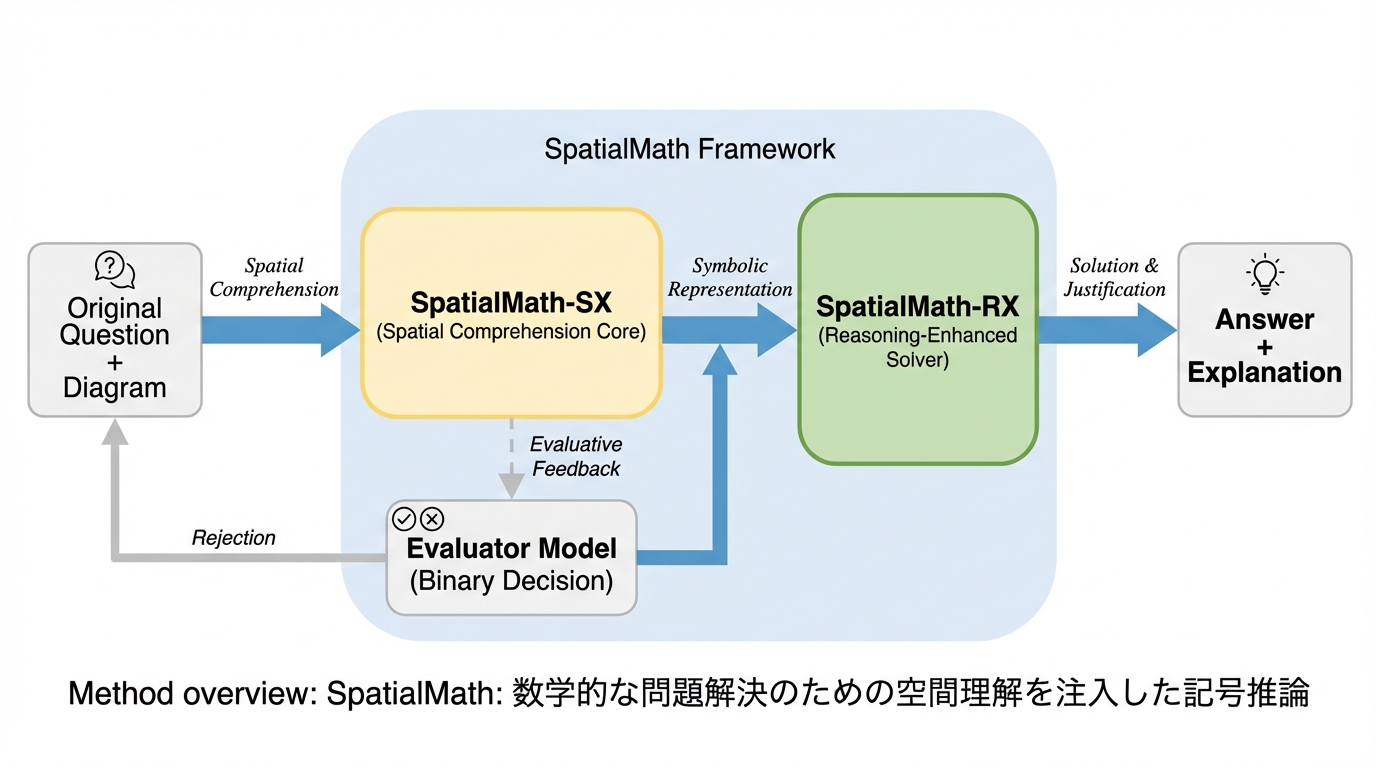
マルチモーダル中小規模言語モデル(MSLM)が幾何学問題で直面する、視覚的理解と論理的推論の乖離を解消するため、空間情報を記号的推論鎖に統合する新フレームワーク「SpatialMath」が提案されました。
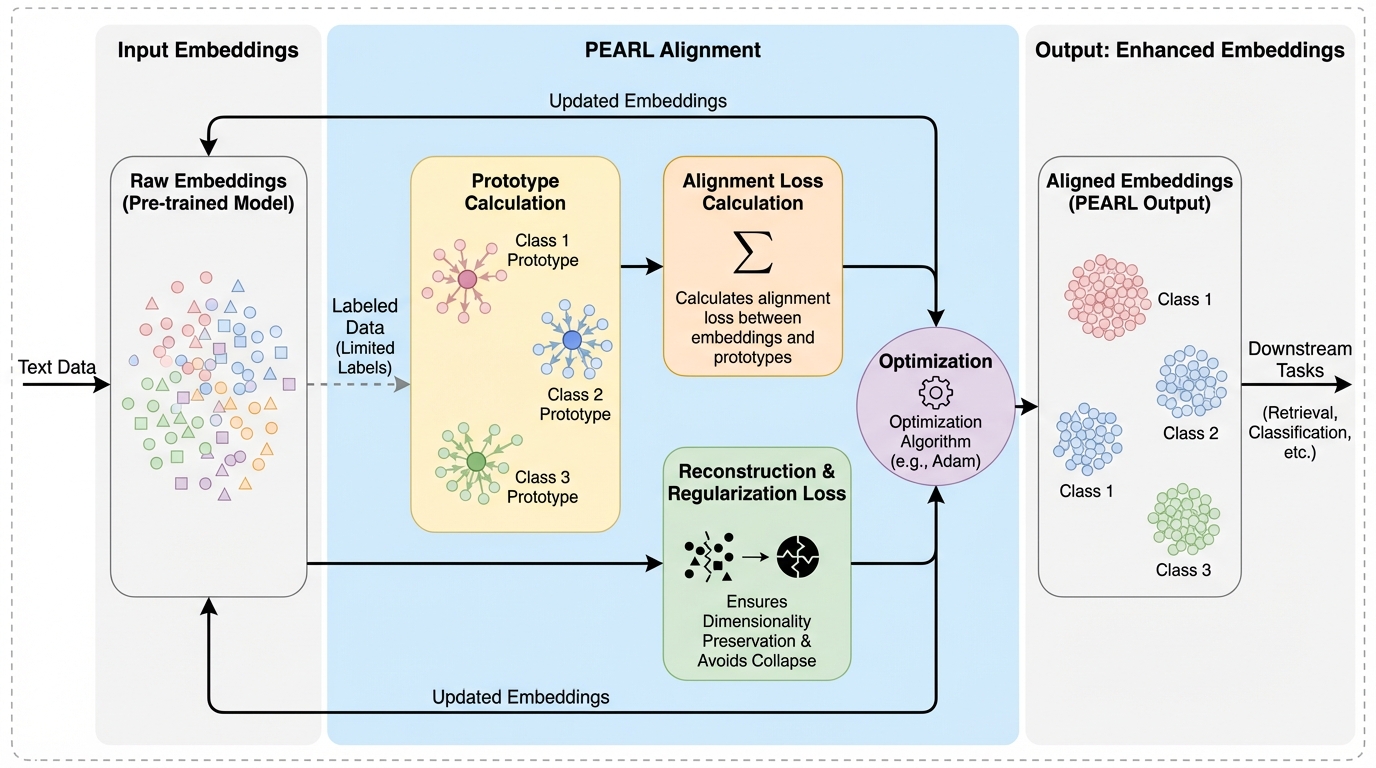
デジタルガバナンス等の実運用システムでは、固定された埋め込み表現の近傍構造が不正確で誤った事例を検索してしまう課題があるが、本研究が提案するPEARLは、限られたラベル情報を用いて埋め込みをクラスプロトタイプに軟らかく整列させることで、次元数を維持したまま近傍の幾何学的構造を劇的に改善する。
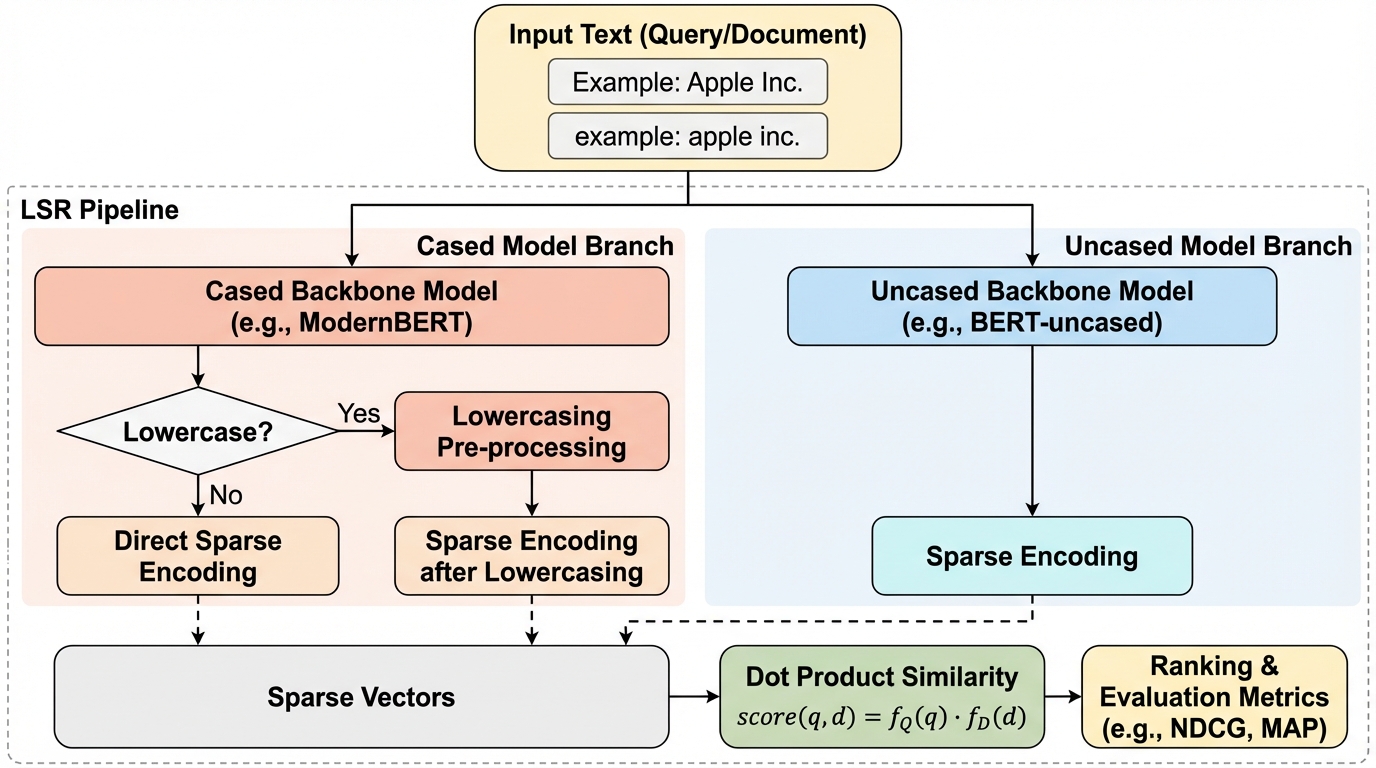
学習型スパース検索(LSR)において、従来主流だった小文字限定(uncased)モデルに対し、最新の言語モデルで一般的な大文字・小文字区別(cased)モデルが与える影響を調査した結果、標準状態では検索精度が大幅に低下することが判明した。
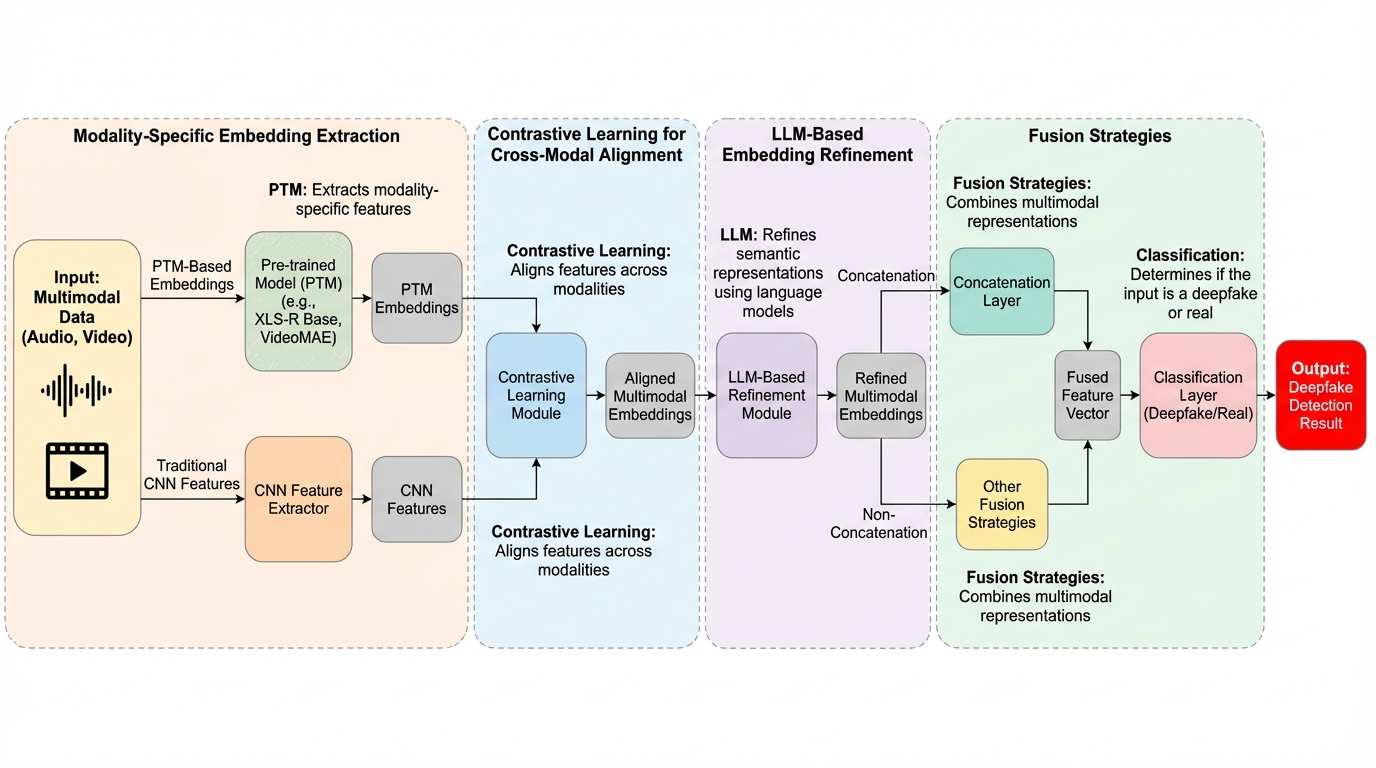
生成AIの進化により、音声と映像を組み合わせた高度なディープフェイクが社会的な脅威となっていますが、従来の検出手法は各要素を個別に処理するため、要素間の微細な矛盾を見逃す「モダリティの断片化」や「浅い相互推論」という課題を抱えていました。
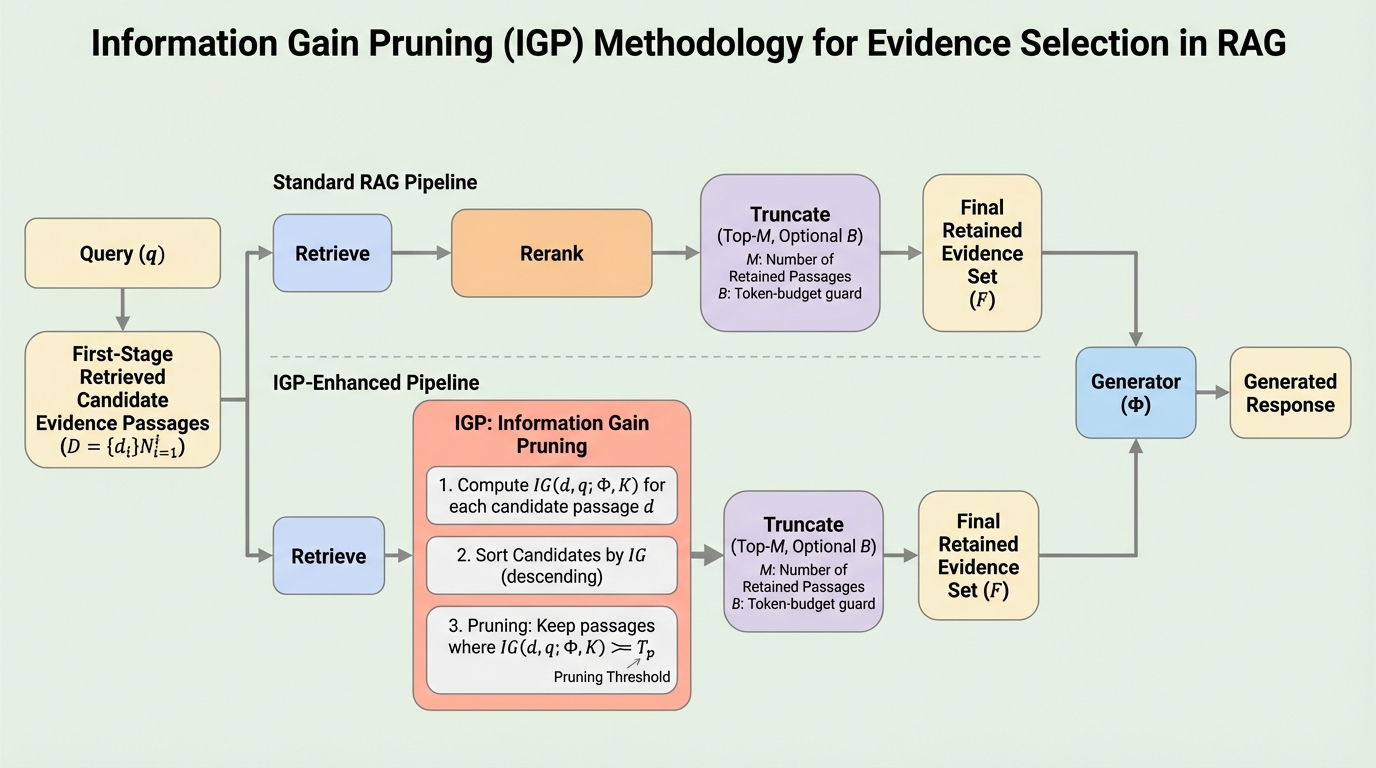
RAG(検索拡張生成)において、検索の関連性指標と最終的な回答精度が必ずしも一致せず、複数の証拠を注入すると冗長性や矛盾によって生成が不安定になるという「関連性と実用性のミスマッチ」を解消するため、生成モデルの不確実性の減少量を基準に証拠を選択する手法「Information Gain Pruning (IGP)」を提案しました。 / IGPは、追加の学習やラベルを必要とせず、生成モデルが出力するトークンの確率分布(ロジット)のみを用いて、回答の安定性に寄与する「情報利得」が高い証拠を特定し、生成を混乱させる低利得な情報をコンテキスト予算に到達する前に排除することで、限られたリソース内での最適な証拠選択を実現します。 / 5つのオープンドメイン質問回答ベンチマークを用いた検証において、IGPは従来手法と比較して回答精度(F1スコア)を約12〜20%向上させると同時に、生成モデルへの入力トークン数を約76〜79%削減するという、精度向上とコスト削減を同時に達成する極めて優れたパフォーマンスを実証しました。
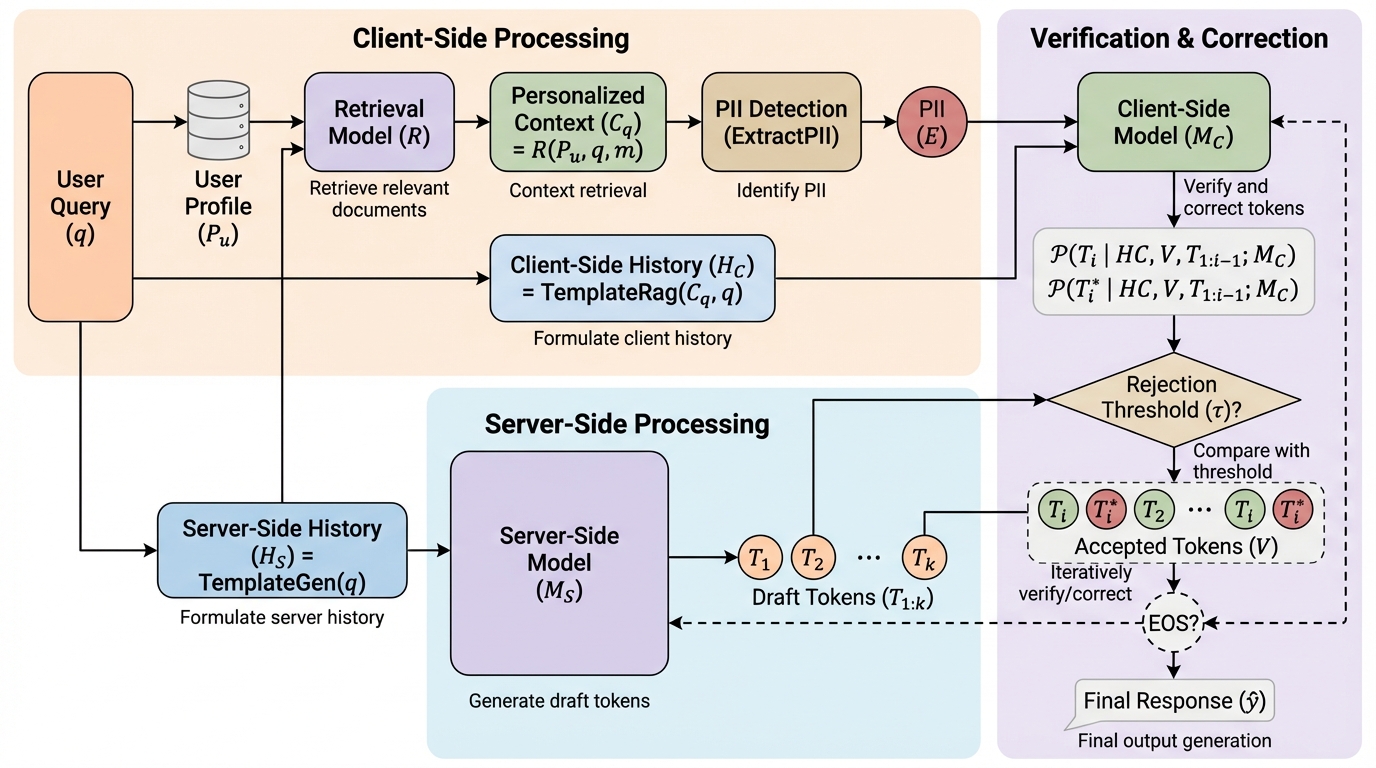
大規模言語モデル(LLM)のパーソナライズにおいて、ユーザーの機密情報をクラウドサーバーに一切開示することなく、高品質な回答を生成するための新しい対話型フレームワーク「P3」が提案されました。 この手法は、サーバー側の強力なモデルが回答候補を生成し、ユーザー手元の小規模モデルが個人のプロフィールに基づき内容を検証・修正する「推測、検証、修正」のプロセスを繰り返すことで、プライバシーと性能を両立させます。 実験では、個人情報を完全に公開した場合の9割以上の性能を維持しつつ、情報漏洩を最小限に抑え、従来のローカルモデル単体や非パーソナライズモデルを平均で7.4%から9%上回る精度を達成することに成功しました。
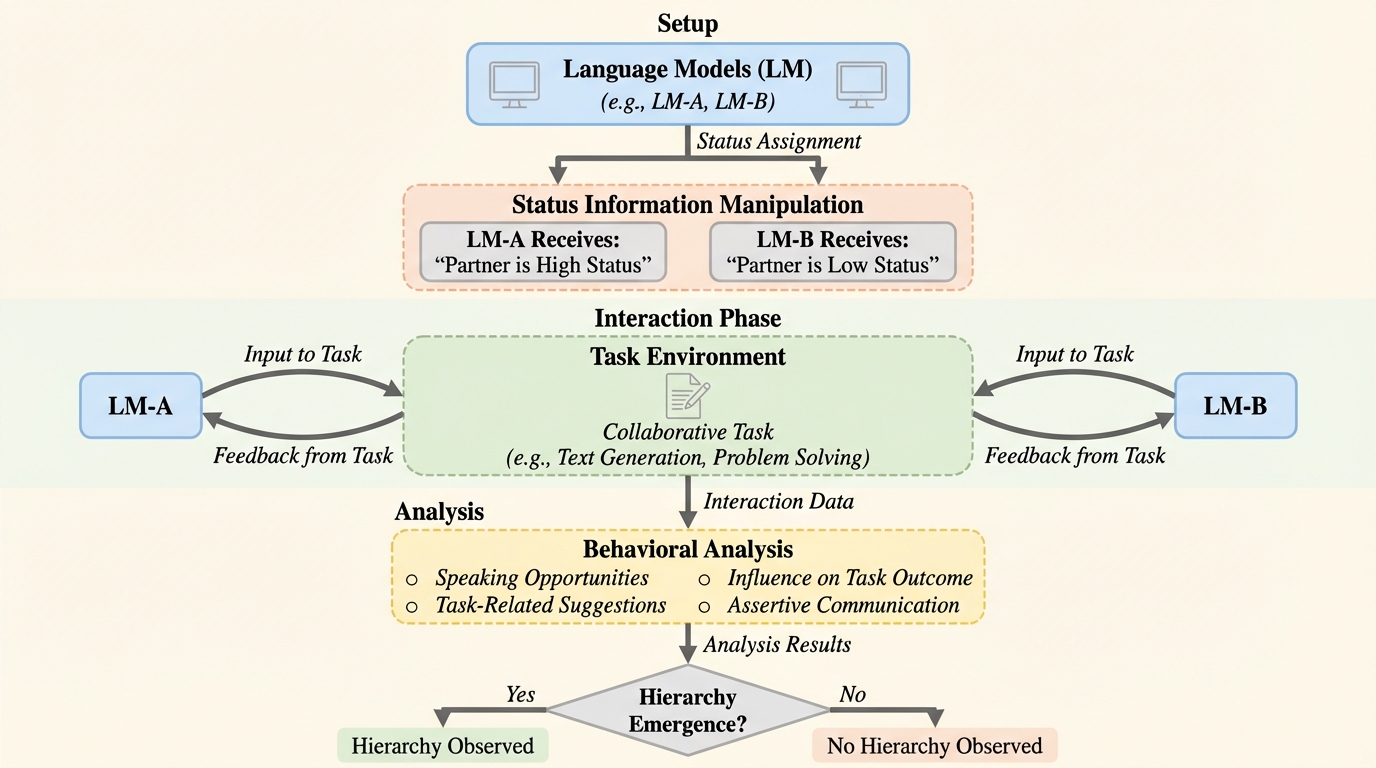
人間の社会組織に普遍的な「地位の階層構造」が言語モデル間でも発生するかを検証するため、感情分類タスクを用いたマルチエージェント環境での実験が行われ、能力が同等のモデル間では専門家やリーダーといった明示的な地位の割り当てによって、下位モデルが上位モデルに従う「譲歩」の非対称性が35ポイント確認された。
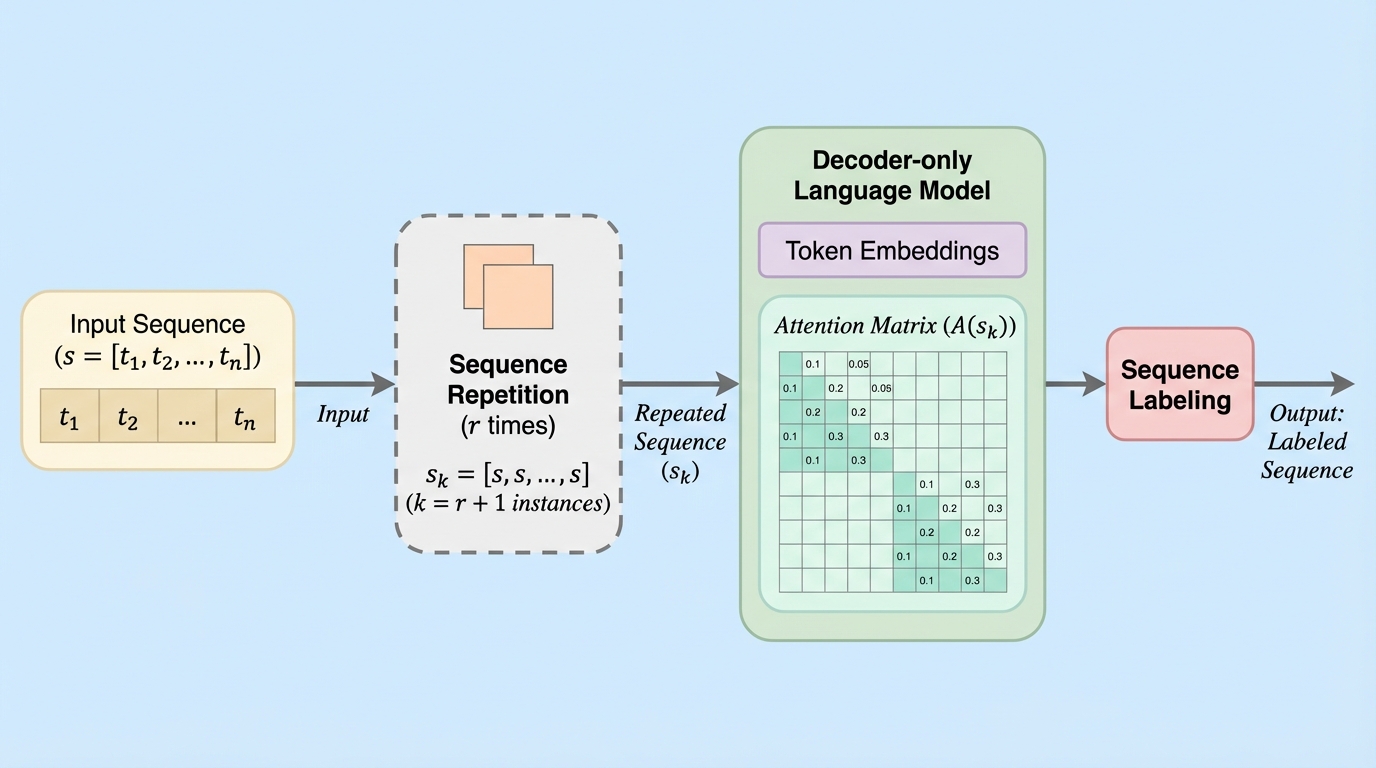
デコーダー専用言語モデルにおいて、入力系列を複数回繰り返す「系列繰り返し(SR)」という手法が、系列ラベリング(SL)タスクにおけるトークン埋め込みの質を大幅に向上させることを明らかにした。 従来の因果的マスクの除去といった侵襲的な手法とは異なり、SRはモデル構造を変更せずに双方向性を擬似的に実現し、エンコーダー専用モデルやマスク解除済みデコーダーを上回る精度を達成している。 繰り返し回数を増やすことで性能が向上する傾向があり、さらに中間層での早期終了(Early Exit)を組み合わせることで、計算コストを抑えつつ最終層と同等の高いパフォーマンスを維持できることが実証された。
知能の成立には、記号を外部世界の参照先と結びつけて意味を付与する「グラウンディング(記号接地)」が不可欠であるが、物理的な肉体を持つ「身体性」は必須ではない。 知能を「動機付け」「信号予測」「因果関係の理解」「経験からの学習」という4つの特性の集合として定義し、これらはデジタル環境のエージェントでも達成可能であることを論じている。 大規模言語モデル(LLM)などの進展を背景に、物理世界に限定されない一貫した規則を持つ環境との相互作用こそが知能の本質であり、身体性は知能の十分条件ではあっても必要条件ではないと結論付けている。