マルチモーダルディープフェイク検出のためのConLLMを用いた真実の解明
生成AIの進化により、音声と映像を組み合わせた高度なディープフェイクが社会的な脅威となっていますが、従来の検出手法は各要素を個別に処理するため、要素間の微細な矛盾を見逃す「モダリティの断片化」や「浅い相互推論」という課題を抱えていました。
TL;DR(結論)
生成AIの進化により、音声と映像を組み合わせた高度なディープフェイクが社会的な脅威となっていますが、従来の検出手法は各要素を個別に処理するため、要素間の微細な矛盾を見逃す「モダリティの断片化」や「浅い相互推論」という課題を抱えていました。 本研究では、対照学習と大規模言語モデル(LLM)の構造を融合させたハイブリッドフレームワーク「ConLLM」を提案し、事前学習済みモデルによる特徴抽出、対照学習による空間の整列、そしてトランスフォーマーによる高度な意味的推論を組み合わせることで、偽造コンテンツの識別能力を飛躍的に向上させました。 広範な検証の結果、ConLLMは音声検出のエラー率を最大50%削減し、映像や音声・映像混合のタスクにおいても既存の最先端モデルを凌駕する精度を達成しただけでなく、推論速度やメモリ効率の面でも極めて優れた実用性を持つことが証明されました。
なぜこの問題か
現在、生成モデルやマルチモーダル合成技術は驚異的な速度で進化を遂げており、人間が肉眼や耳で判別することが困難なほどリアルな合成メディア、いわゆるディープフェイクが容易に作成できるようになりました。このような技術は、政治家が実際には行っていない発言をしているかのような偽ビデオの作成などに悪用され、公衆の認識を操作し、社会的および政治的な安定を根底から揺るがす深刻なリスクをもたらしています。ディープフェイクの手法は、GAN(敵対的生成ネットワーク)やVAE(変分自己符号化器)、さらにはトランスフォーマーベースの音声合成システムなどを駆使して、音声、映像、テキストを極めて自然に融合させる段階に達しています。しかし、これに対抗するための既存の検出技術には、主に二つの大きな限界が存在することが明らかになっています。 第一の課題は「モダリティの断片化(Modality Fragmentation)」です。これは、音声や映像といった異なる種類のデータから抽出された特徴が、システム内部で孤立して処理されてしまう現象を指します。…
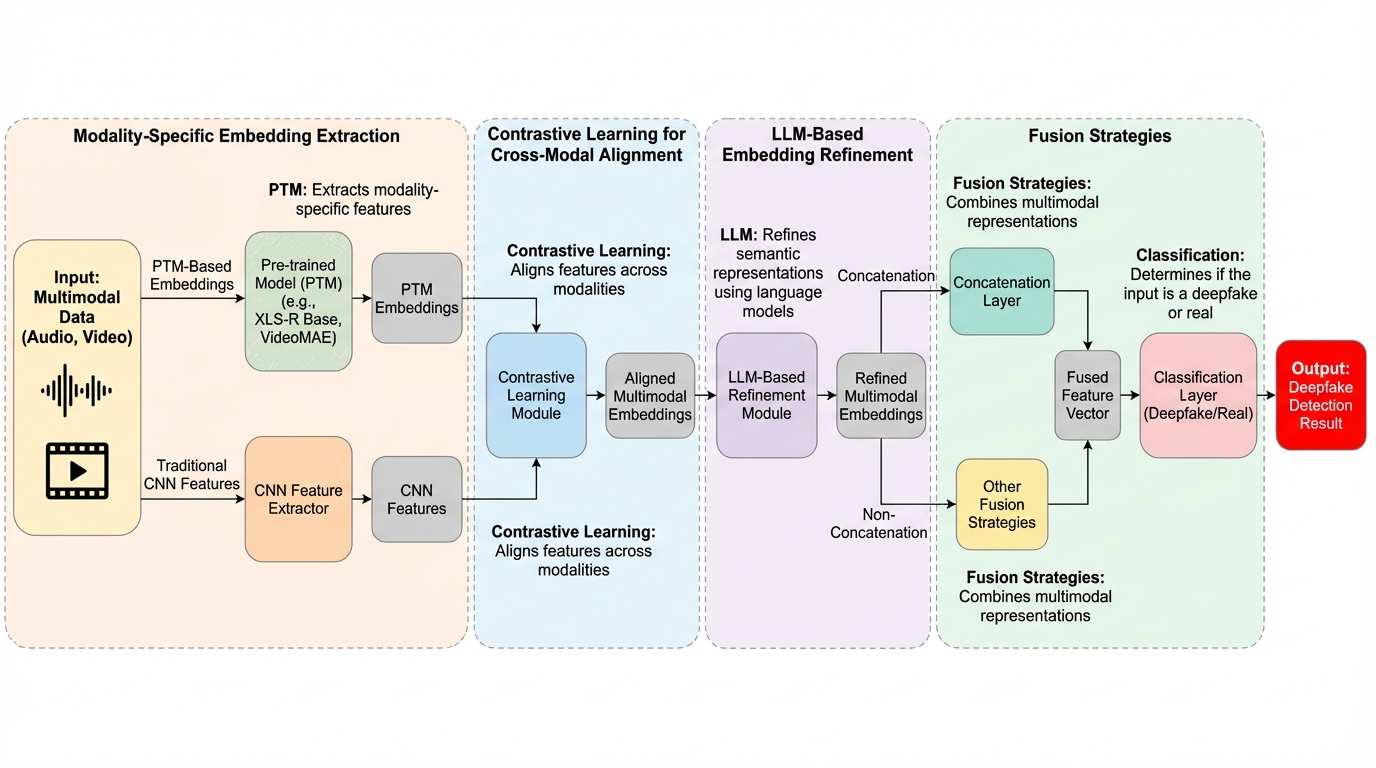
核心:何を提案したのか
本研究が提案する「ConLLM(Contrastive Learning with Large Language Models)」は、対照学習の利点と大規模言語モデル(LLM)の強力な推論能力を統合した、マルチモーダルディープフェイク検出のためのハイブリッドフレームワークです。このフレームワークの核心は、特徴抽出と意味的な統合を明確に分離した「2段階のモジュール構成」を採用している点にあります。これにより、従来の検出器が抱えていた構造的な弱点を根本から解決することを目指しています。 第1段階では、各モダリティに特化した事前学習済みモデル(PTM)を活用し、音声や映像の固有の性質を損なうことなく、高精度な埋め込み(Embedding)を抽出します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related