大文字にするかしないか:学習型スパース検索における実証的研究
学習型スパース検索(LSR)において、従来主流だった小文字限定(uncased)モデルに対し、最新の言語モデルで一般的な大文字・小文字区別(cased)モデルが与える影響を調査した結果、標準状態では検索精度が大幅に低下することが判明した。
TL;DR(結論)
学習型スパース検索(LSR)において、従来主流だった小文字限定(uncased)モデルに対し、最新の言語モデルで一般的な大文字・小文字区別(cased)モデルが与える影響を調査した結果、標準状態では検索精度が大幅に低下することが判明した。 しかし、入力テキストを事前に小文字化する前処理を施すことで、casedモデルであってもuncasedモデルと同等の高い検索精度を達成できることが実証され、ModernBERTなどの最新のcased限定モデルをLSRに統合するための実用的な道筋が示された。 トークンレベルの分析により、小文字化された入力に対してcasedモデルは大文字トークンの出力をほぼ完全に抑制し、実質的にuncasedモデルとして振る舞うことが明らかになり、この挙動が検索性能を回復させる鍵となっていることが確認された。
なぜこの問題か
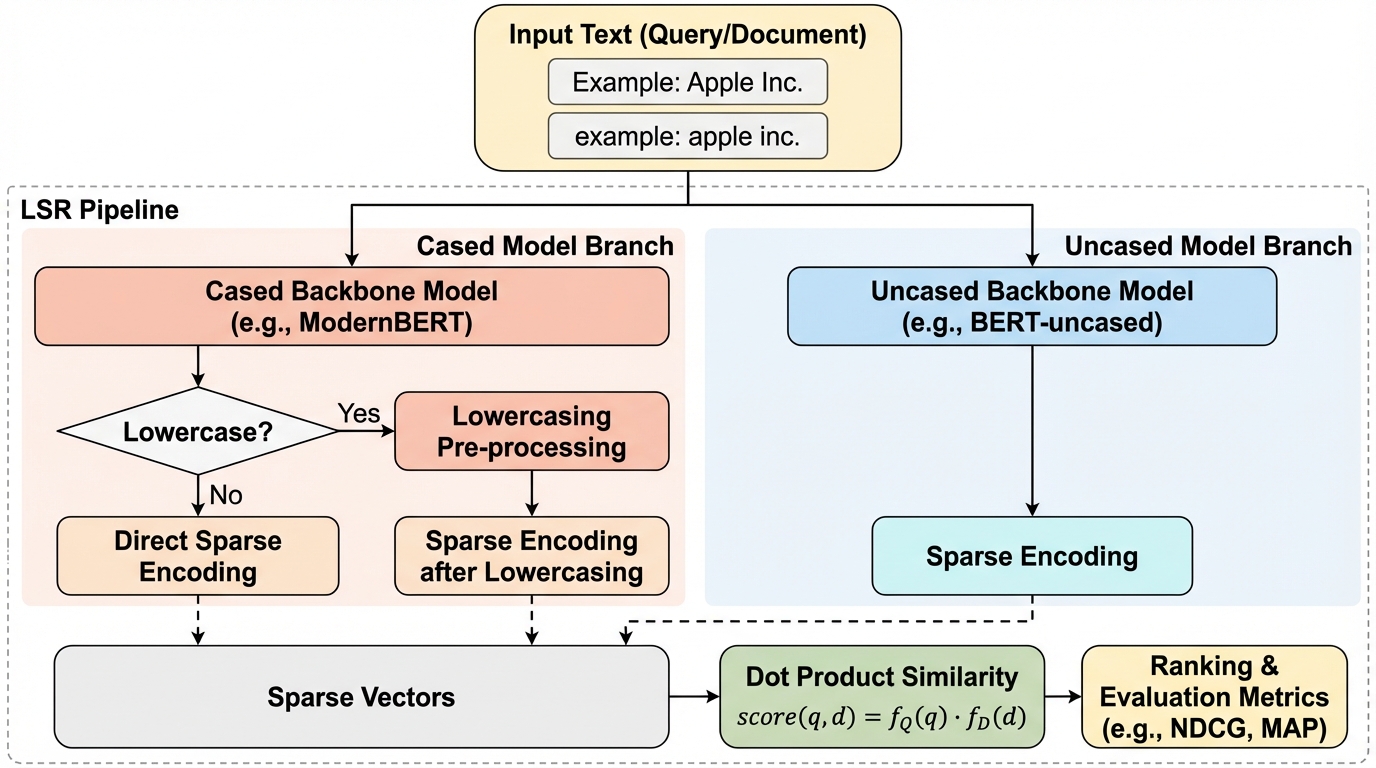
学習型スパース検索(LSR)は、クエリと文書をスパースな語彙表現に変換し、転置インデックスを用いて効率的な検索を可能にする手法である。SPLADEなどの既存のLSR手法は、これまでほぼ例外なく小文字限定(uncased)のバックボーンモデルに依存してきた。これは、大文字と小文字の区別を排除することで語彙の不一致を減らし、検索精度を高めるという伝統的な情報検索(IR)の慣習に基づいている。しかし、近年登場したModernBERTなどの最先端言語モデルは、大文字と小文字を区別するcased版のみで提供される傾向が強まっている。この状況は、LSR手法の将来的な存続可能性に対する懸念を生じさせている。もしcasedモデルがLSRにおいて本質的に不利であれば、最新の強力なアーキテクチャを検索システムに活用できなくなるからである。 これまで、バックボーンモデルの大文字・小文字の区別がLSRの性能にどのような影響を与えるかについての系統的な調査は行われてこなかった。…
核心:何を提案したのか
本研究の核心は、LSRにおけるcasedモデルの性能低下の原因を特定し、それを解消するための具体的な手法を提案・検証した点にある。具体的には、BERTおよびDistilBERTをバックボーンとして、casedモデルとuncasedモデルのペアを用いた系統的な評価を実施した。提案されたアプローチは、入力段階での前処理と出力段階での後処理の二段構えとなっている。前処理としては、入力テキストをそのまま使用する設定と、すべて小文字に変換する設定(Lowercasing)を比較した。後処理においては、出力されるスパースベクトルの次元を制御する三つの戦略を導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related