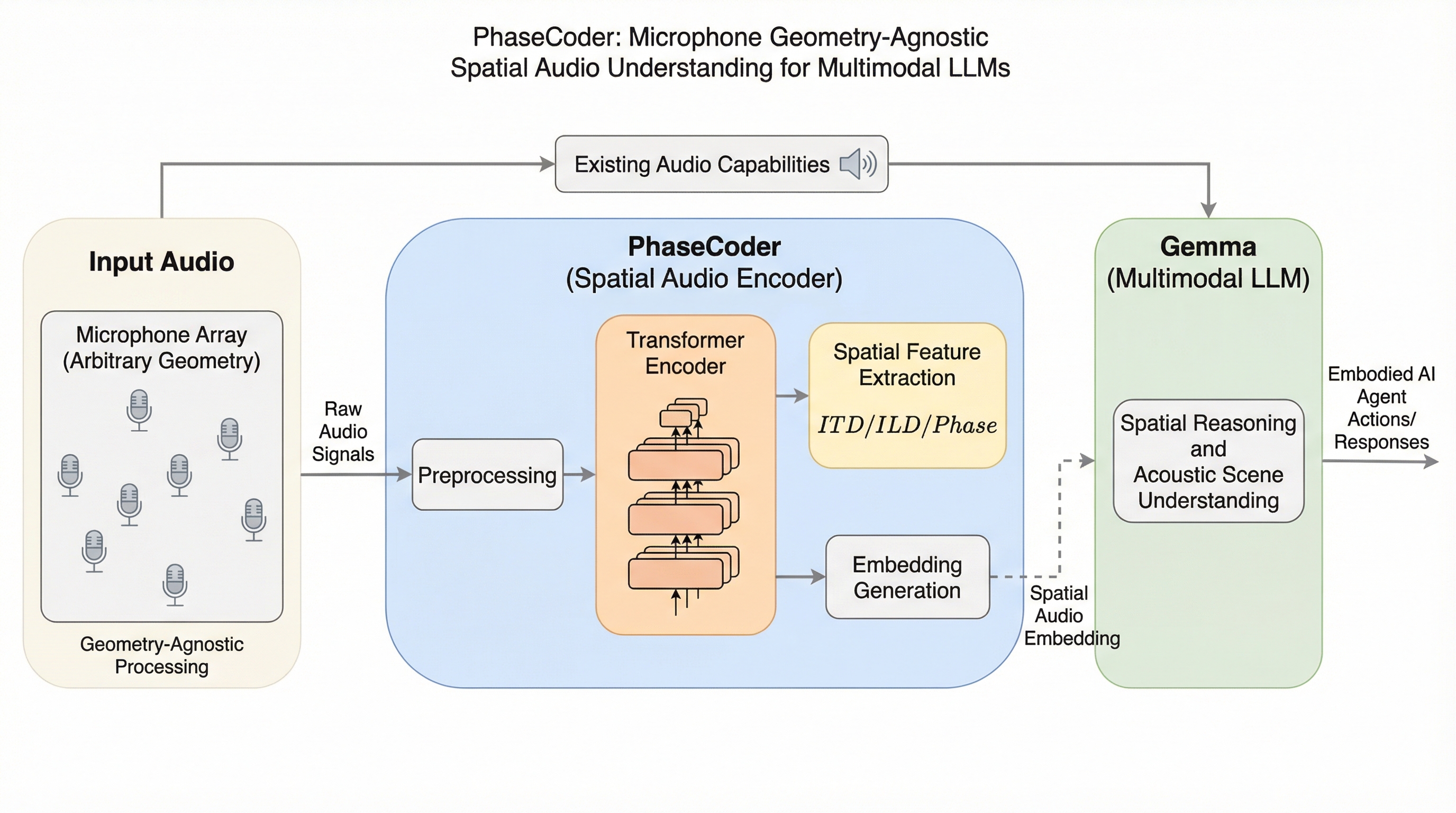
PhaseCoder:マルチモーダルLLMのためのマイク配置に依存しない空間オーディオ理解
PhaseCoderは、マイクの数や配置に縛られず、多チャンネルの生音声とマイクの3次元座標から直接空間情報を抽出できる、トランスフォーマーのみで構成された革新的な空間オーディオエンコーダーである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
PhaseCoderは、マイクの数や配置に縛られず、多チャンネルの生音声とマイクの3次元座標から直接空間情報を抽出できる、トランスフォーマーのみで構成された革新的な空間オーディオエンコーダーである。
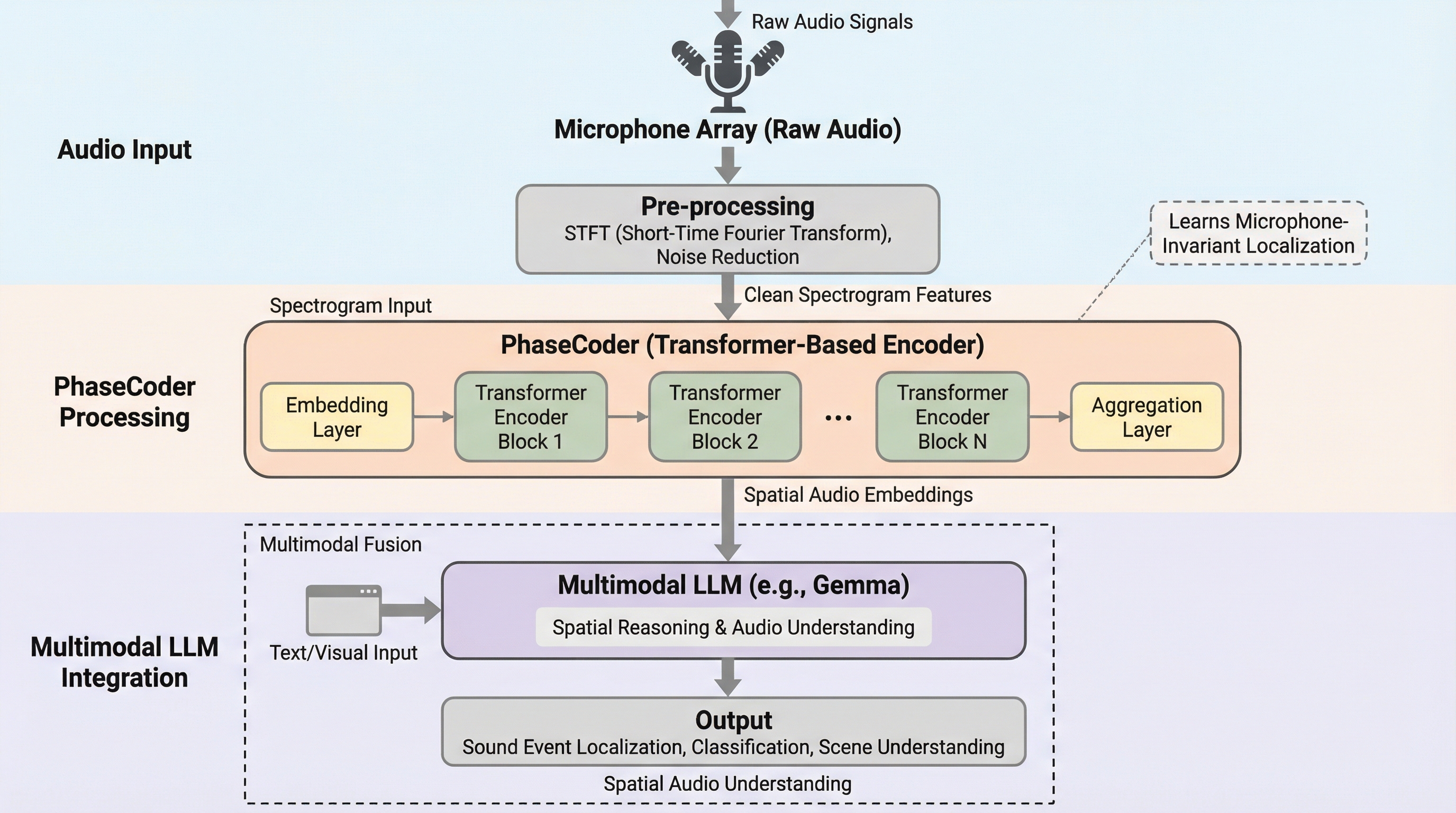
現在のマルチモーダル大規模言語モデル(LLM)は音声をモノラルとして処理しており、音の方向や距離といった空間情報の活用が困難であったが、本研究ではマイクの数や幾何学的配置に依存せず、あらゆるデバイスで利用可能な空間オーディオエンコーダ「PhaseCoder」を提案した。
現在の手話翻訳(SLT)データセットは、一つの手話に対して一つの書き言葉しか対応していないため、翻訳の多様性を評価できないという課題がありました。本研究では、大規模言語モデル(LLM)を用いて書き言葉のパラフレーズ(言い換え)を自動生成し、複数の正解候補(参照訳)として活用する手法を提案しました。
現在の手話翻訳データセットは、一つの手話表現に対して一つの書き言葉の翻訳しか紐付けられていないことが多く、手話と書き言葉の非同型な関係性を十分に捉えきれていないという課題がある。 本研究では、大規模言語モデル(LLM)を活用して翻訳文の言い換え(パラフレーズ)を自動生成し、これを合成的な代替参照文として用いることで、手話翻訳モデルの学習と評価の両面に与える影響を詳細に調査した。 検証の結果、言い換えを単純に学習に組み込むだけでは性能向上に繋がらない一方で、評価指標に複数の言い換えを取り入れた「BLEUpara」は、標準的な指標よりも人間の主観評価と強く相関することが明らかになった。
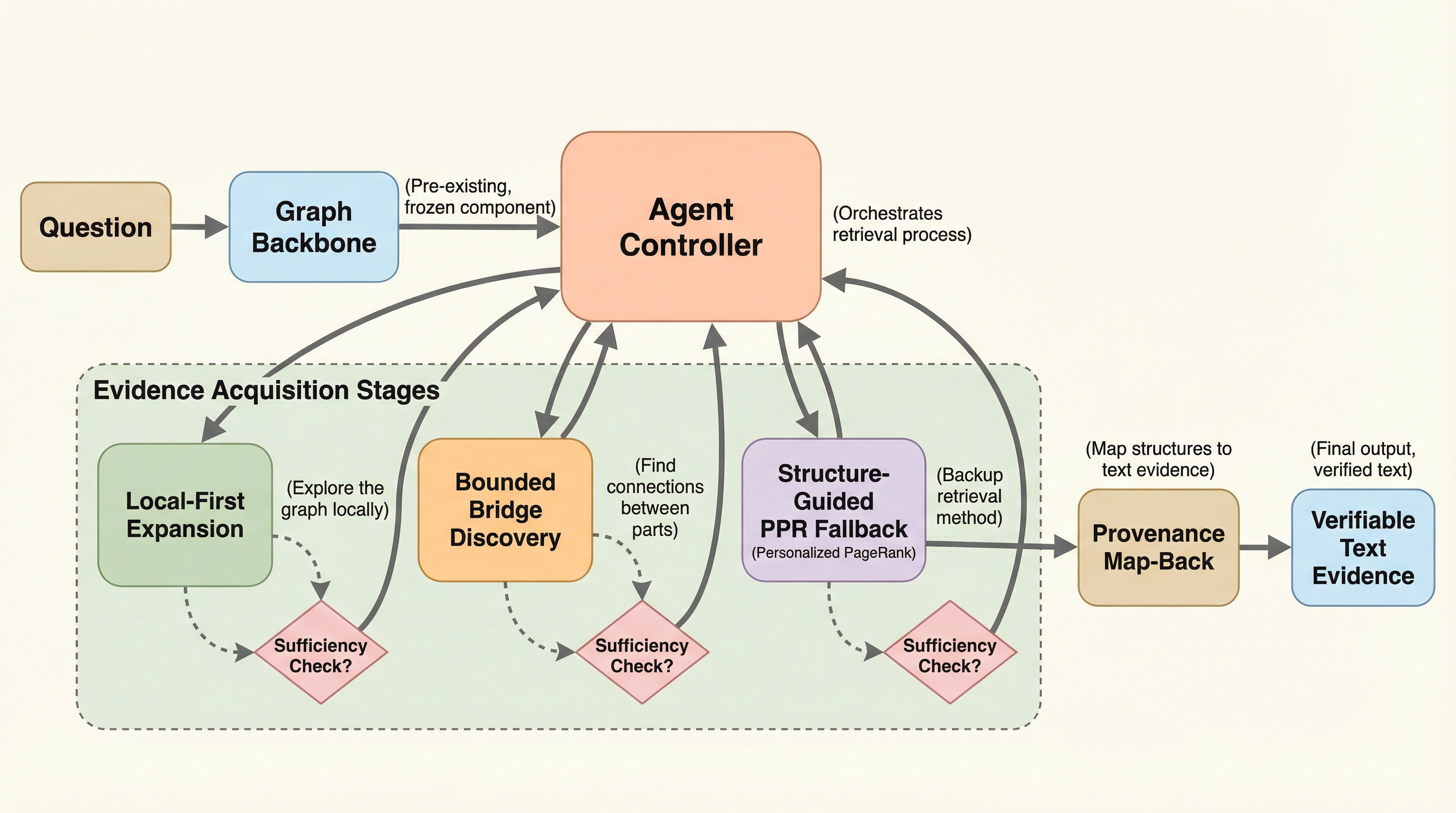
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
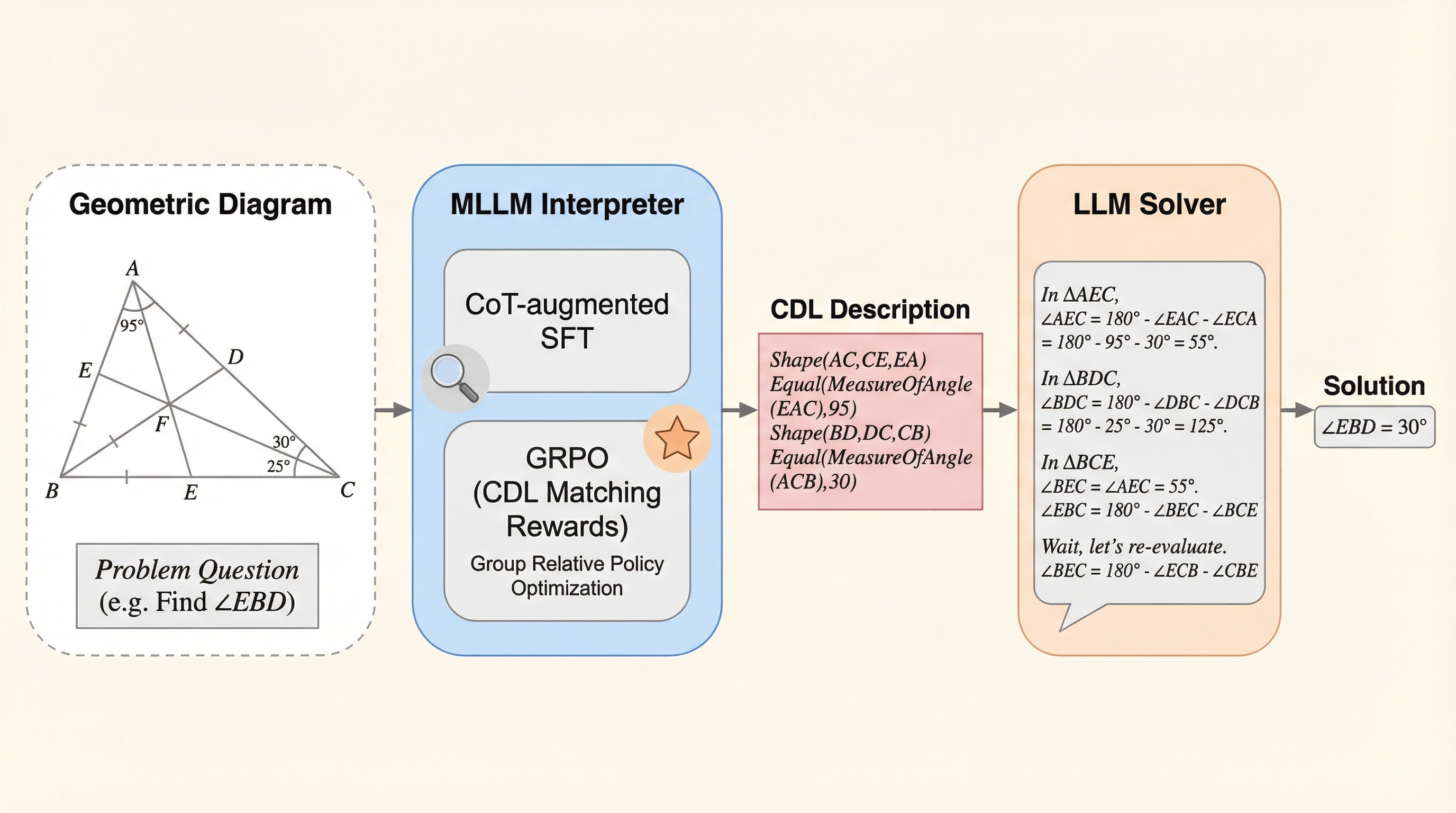
平面幾何問題(PGPS)において、マルチモーダルLLM(MLLM)が抱える視覚的誤認や推論能力の低下という課題を解決するため、幾何学図形を「条件宣言言語(CDL)」という簡潔なテキスト記述に変換し、それを既存の強力なLLMに読み込ませて解かせるという新しい推論パラダイムを提案しました。
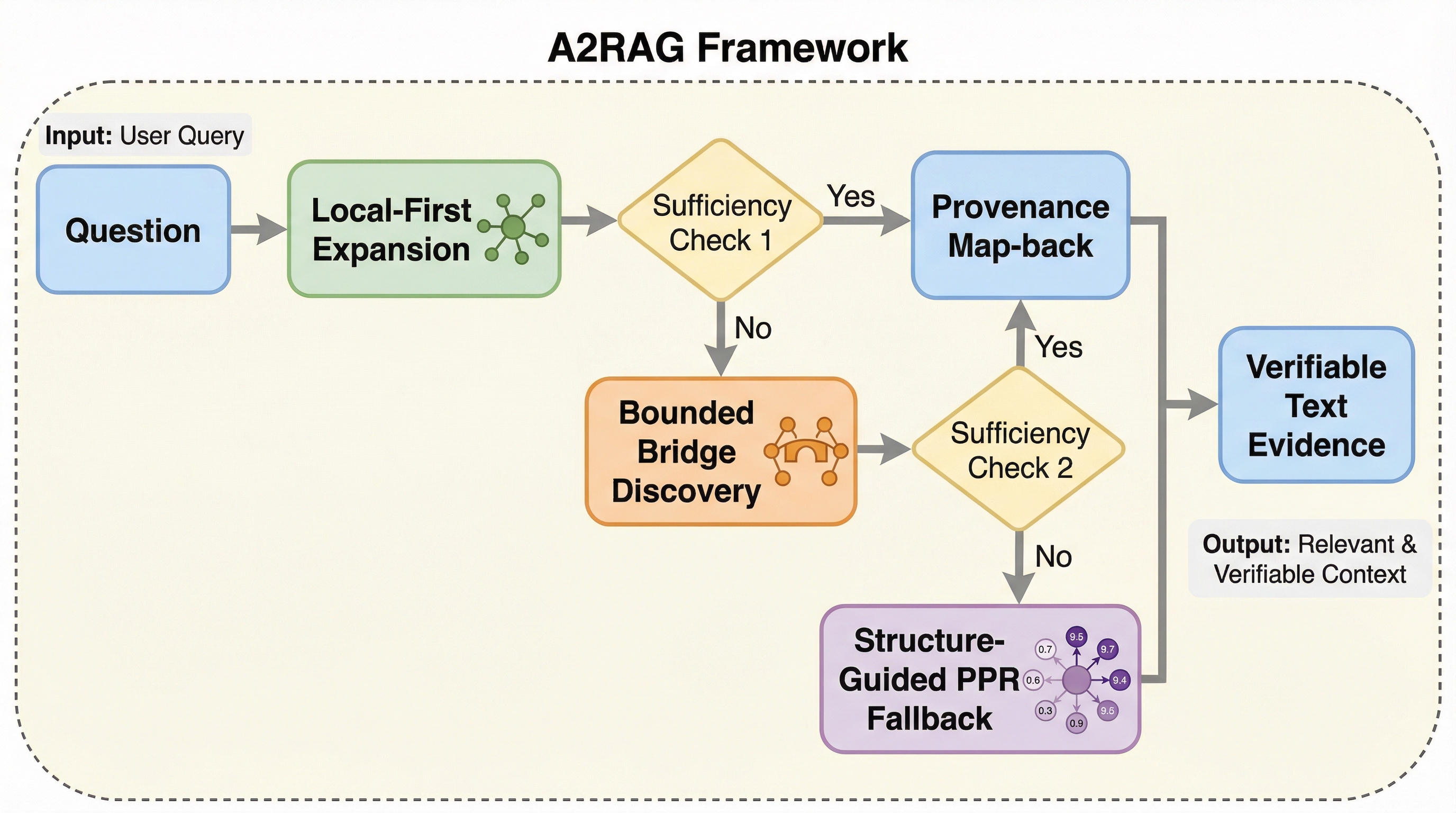
従来のGraphRAGは、全ての質問に対して一律の高度な検索を行うため、簡単な質問での過剰なコスト消費と、複雑な質問におけるグラフ化の際の情報欠落という二つの課題を抱えていました。 本研究が提案するA2RAGは、回答の妥当性を検証して必要時のみ再試行する「適応型制御ループ」と、局所から広域へ段階的に探索範囲を広げつつ元のテキストから詳細を復元する「エージェント型検索機」を統合したフレームワークです。 ベンチマークを用いた検証では、従来の反復的な手法と比較して検索精度を最大11.8ポイント向上させつつ、トークン消費量と処理遅延を約50パーセント削減することに成功し、実用的な効率と信頼性の両立を証明しました。
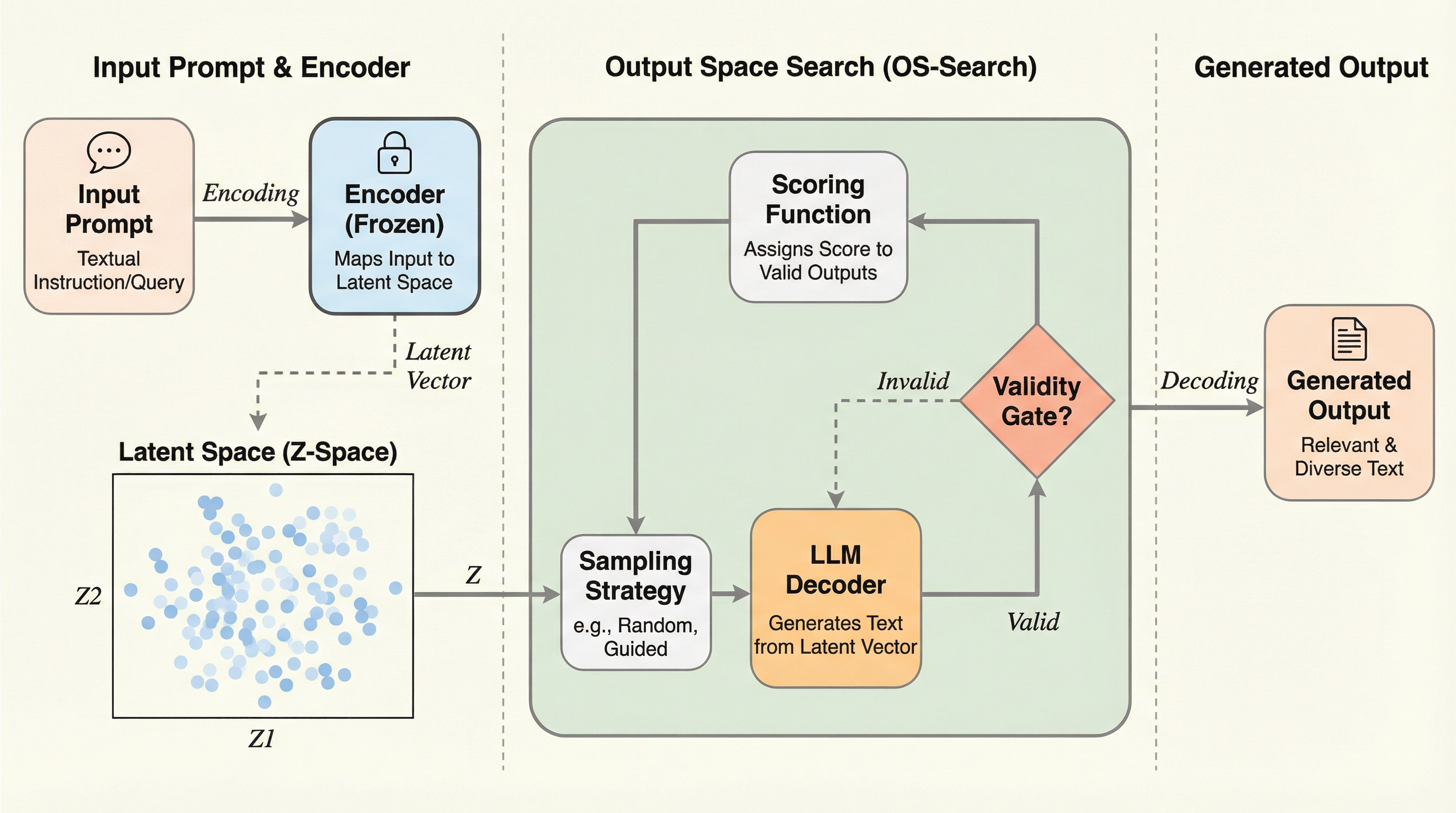
大規模言語モデル(LLM)の生成を、従来の「トークンの逐次的な選択」から、3次元の出力空間(Z空間)における「終点の探索」へと転換する手法「OS-Search」を提案した。 固定されたエンコーダと強化学習(RL)を用いて、指定された座標(z*)の近傍に着地する出力を生成するポリシーを構築し、並列的な多様性探索やブラックボックス最適化を可能にした。 物語生成では従来のプロンプトチェイニングより3.1倍高い多様性を実現し、コード生成では外部評価指標を最大化する最適化に成功するなど、高い制御性と実用性が示された。
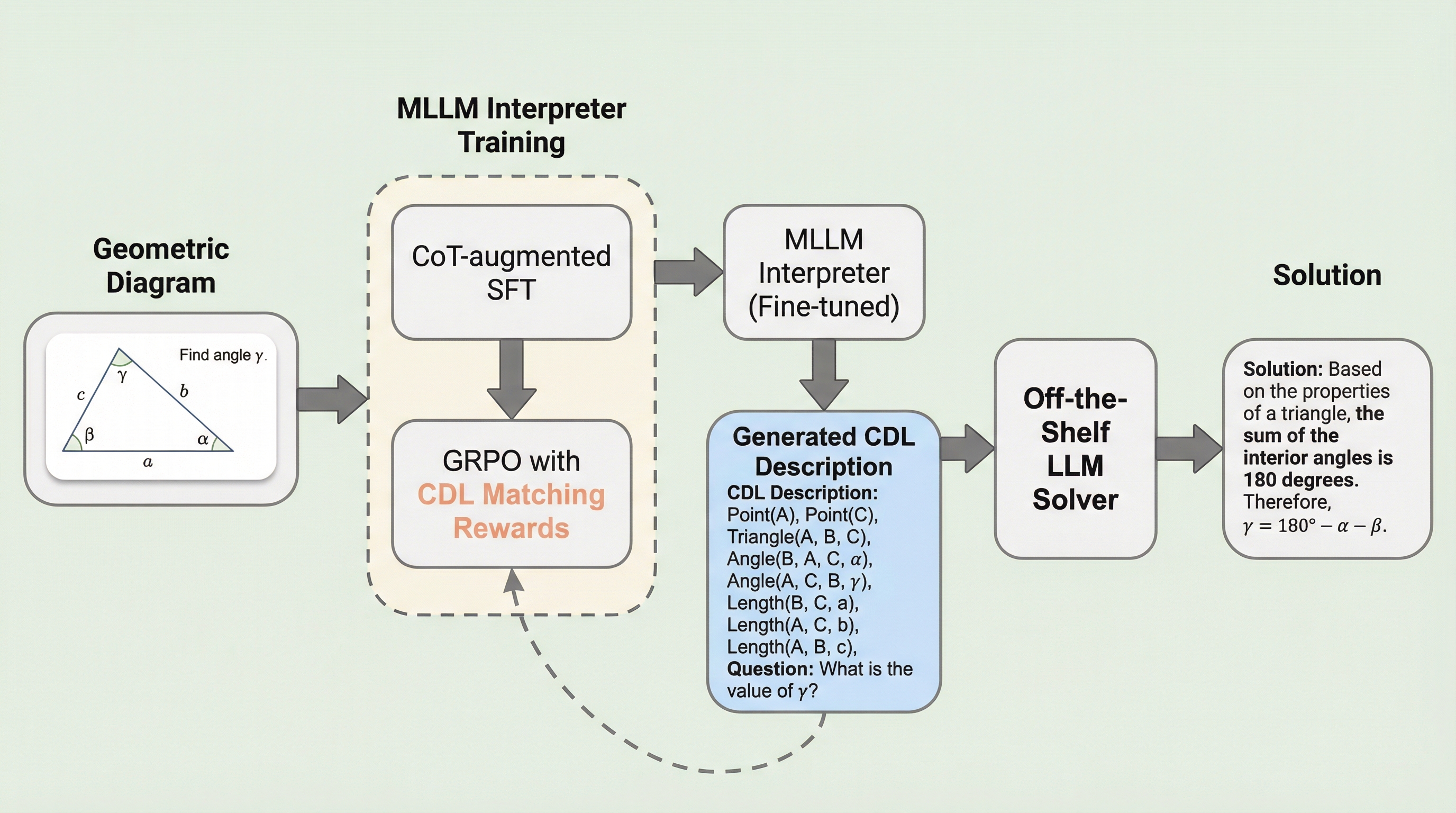
平面幾何学の問題解決において、マルチモーダルモデルが抱える視覚的な認識誤りや論理推論能力の低下を克服するため、図形を簡潔な幾何学的記述言語(CDL)へ変換する「インタープリター」と、その記述を基に解答を導く「ソルバー」を分離した二段階のフレームワークを提案しています。
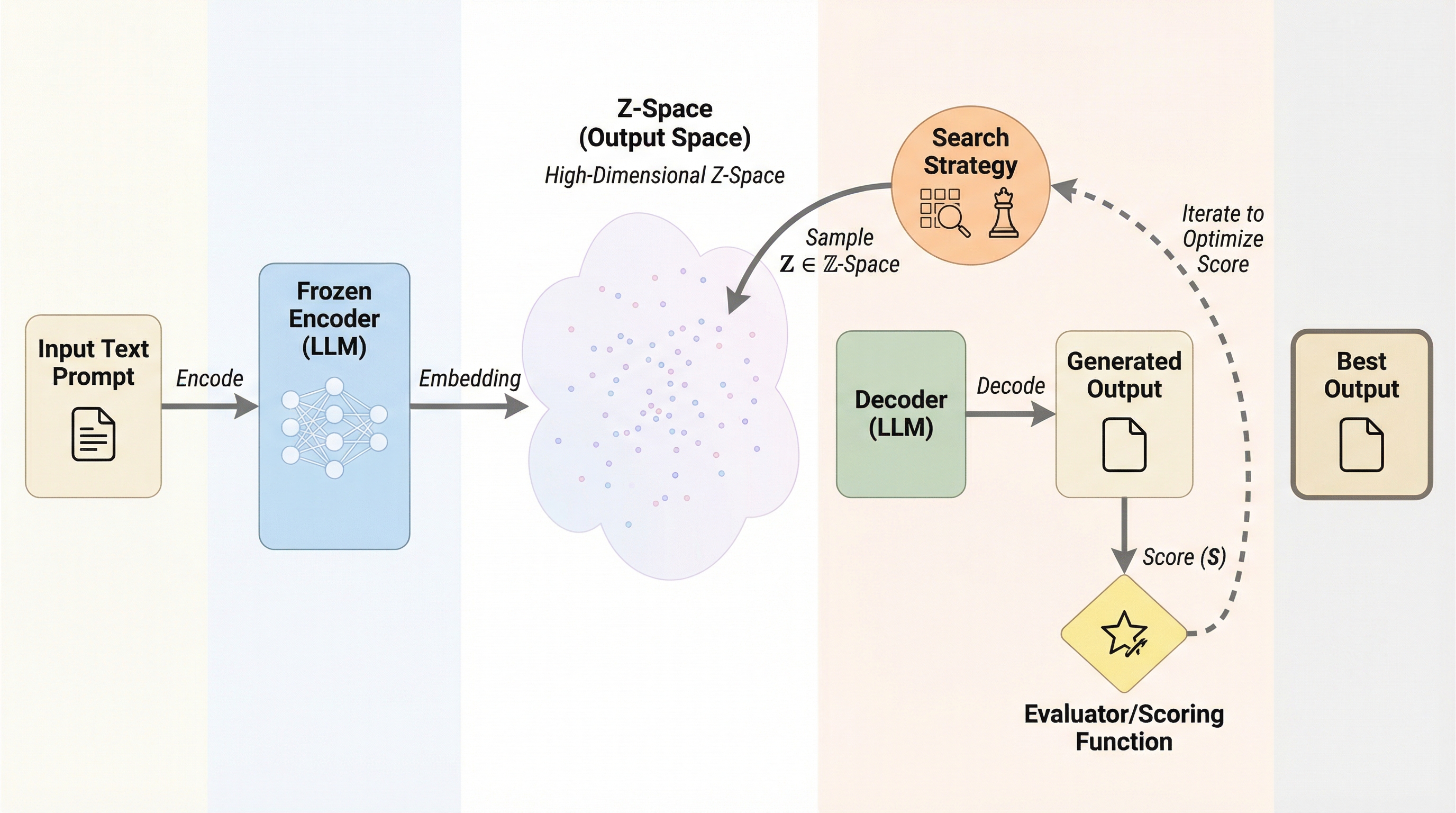
本研究は、大規模言語モデル(LLM)の生成を、トークンの逐次選択から3次元の出力空間(Z空間)における終点探索へと転換する「OS-Search」を提案した。 凍結されたエンコーダと強化学習(GRPO)を組み合わせることで、指定された座標ターゲット($z^*$)に基づき、目標地点に近い出力を直接生成する制御を可能にした。