出力空間探索:フリーズされたエンコーダによって定義された出力空間におけるLLM生成の標的化
大規模言語モデル(LLM)の生成を、従来の「トークンの逐次的な選択」から、3次元の出力空間(Z空間)における「終点の探索」へと転換する手法「OS-Search」を提案した。 固定されたエンコーダと強化学習(RL)を用いて、指定された座標(z*)の近傍に着地する出力を生成するポリシーを構築し、並列的な多様性探索やブラックボックス最適化を可能にした。 物語生成では従来のプロンプトチェイニングより3.1倍高い多様性を実現し、コード生成では外部評価指標を最大化する最適化に成功するなど、高い制御性と実用性が示された。
TL;DR(結論)
大規模言語モデル(LLM)の生成を、従来の「トークンの逐次的な選択」から、3次元の出力空間(Z空間)における「終点の探索」へと転換する手法「OS-Search」を提案した。 固定されたエンコーダと強化学習(RL)を用いて、指定された座標(z*)の近傍に着地する出力を生成するポリシーを構築し、並列的な多様性探索やブラックボックス最適化を可能にした。 物語生成では従来のプロンプトチェイニングより3.1倍高い多様性を実現し、コード生成では外部評価指標を最大化する最適化に成功するなど、高い制御性と実用性が示された。
なぜこの問題か
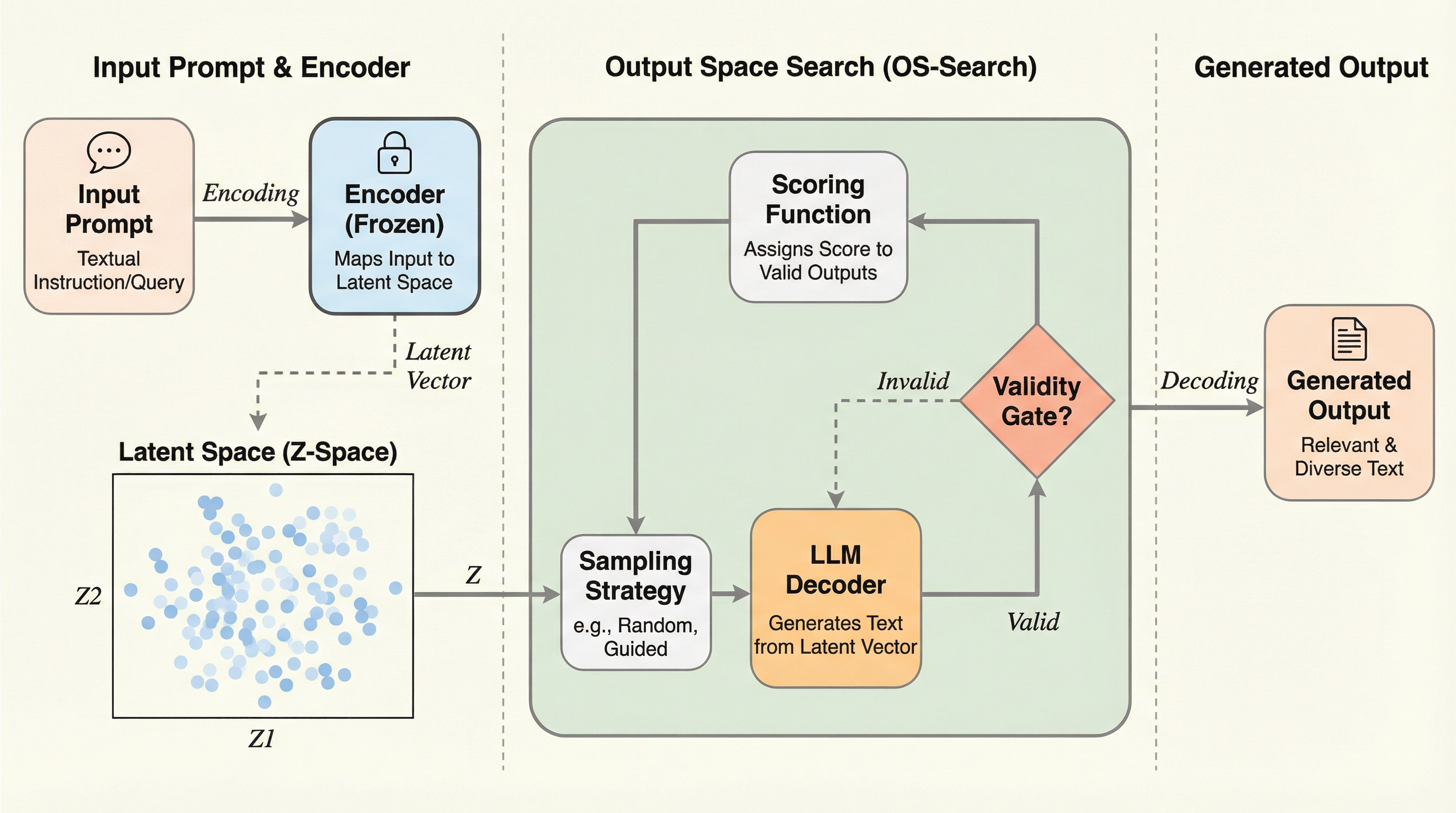
現在の大規模言語モデル(LLM)は、テキストやコードの生成において非常に強力な能力を発揮しているが、実用的なワークフローにおいては、単一の良好なサンプルを得るだけでは不十分な場合が多い。例えば、ユーザーは多様な下書きや代替案、あるいは分岐する物語を並列に探索したいと考えたり、外部のエバリュエーターによって得られるスコアを最大化するような出力を探索したいと考えたりする。しかし、現在の一般的な手法は、トークン空間での繰り返しサンプリングや、以前の生成結果をコンテキストにフィードバックする適応的なループ(プロンプトチェイニングやリジェクションサンプリング)に大きく依存している。これらの手法にはいくつかの根本的な課題がある。第一に、生成プロセスに逐次的な依存関係を導入するため、計算効率が低下し、コンテキスト長が増大する原因となる。第二に、外部ループが直接最適化できるような、安定した低次元のインターフェースを提供していない。 研究チームは、自己回帰型LLMが、出力がどこに着地すべきかを選択するための「状態のような」ターゲットを公開できるのではないかという問いを立てた。…
核心:何を提案したのか
本論文が提案する「Output-Space Search(OS-Search)」は、表現と実行を完全にモジュール化した設計思想に基づいている。この手法の核心は、固定されたエンコーダによって定義される外部の出力空間Zと、その空間内の特定の座標を狙って生成を行うように訓練されたコントローラーの組み合わせにある。まず表現の側面では、凍結されたエンコーダと線形投影(PCAおよびVarimax回転)を用いて、タスクの出力に対する固定座標を定義する。これにより、高次元のテキスト空間が3次元の連続的な空間へと圧縮される。この3次元という低次元性は、人間や外部の最適化アルゴリズムが扱いやすいインターフェースとして機能する。次に実行の側面では、指定されたターゲット座標 z* に基づいて条件付けられた、検索グラウンディング(retrieval-grounded)ポリシーを訓練する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related