出力空間探索:凍結されたエンコーダによって定義された出力空間におけるLLM生成の標的化
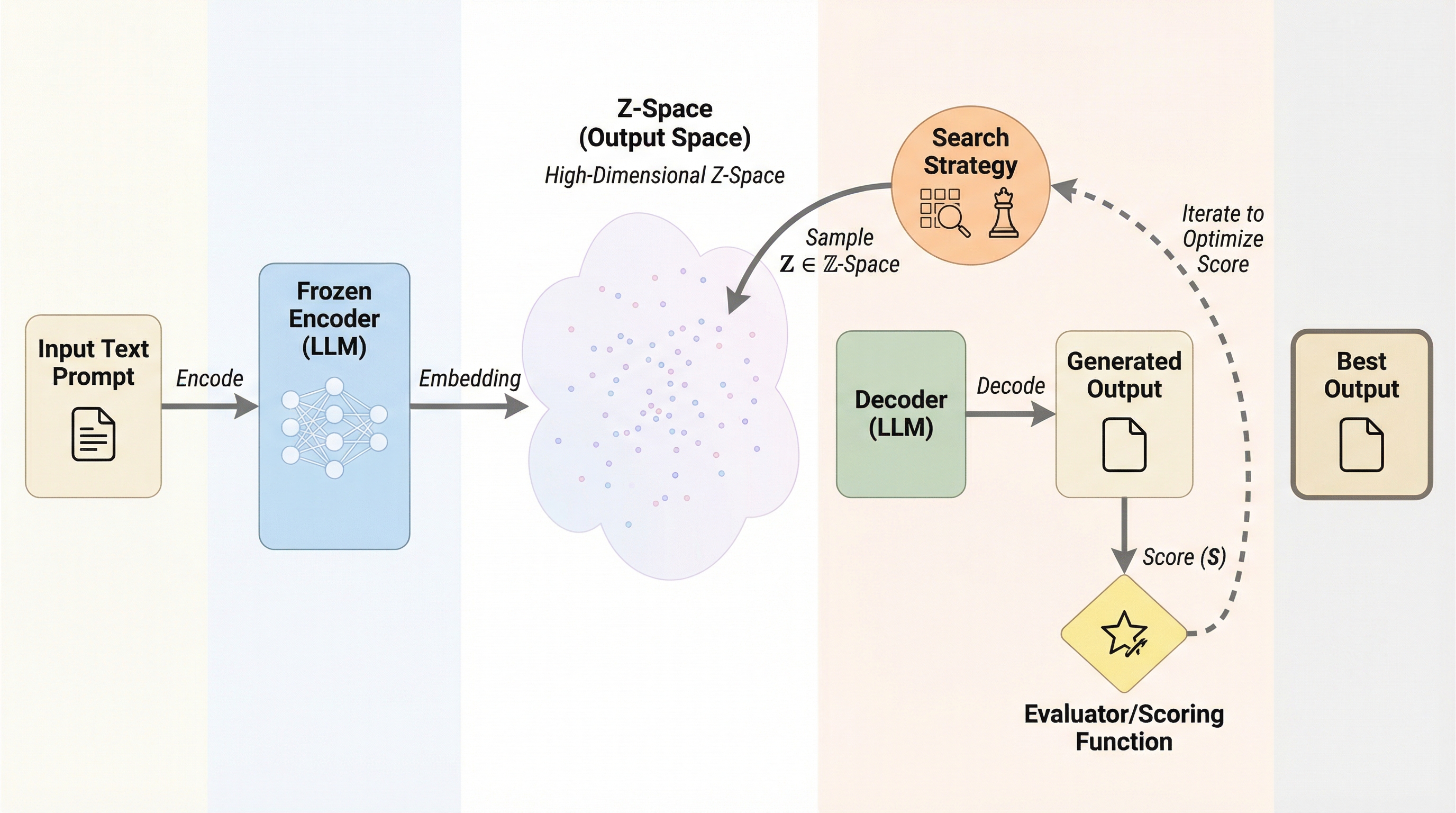
本研究は、大規模言語モデル(LLM)の生成を、トークンの逐次選択から3次元の出力空間(Z空間)における終点探索へと転換する「OS-Search」を提案した。 凍結されたエンコーダと強化学習(GRPO)を組み合わせることで、指定された座標ターゲット($z^*$)に基づき、目標地点に近い出力を直接生成する制御を可能にした。
TL;DR(結論)
本研究は、大規模言語モデル(LLM)の生成を、トークンの逐次選択から3次元の出力空間(Z空間)における終点探索へと転換する「OS-Search」を提案した。 凍結されたエンコーダと強化学習(GRPO)を組み合わせることで、指定された座標ターゲット($z^*$)に基づき、目標地点に近い出力を直接生成する制御を可能にした。 検証では、物語生成において従来のプロンプトチェイニングの3.1倍の多様性を達成し、コード生成ではモデルに目的関数を教えずに性能を向上させることに成功した。
なぜこの問題か
現在の大規模言語モデル(LLM)は、テキストやコードの生成において非常に高い能力を発揮しているが、実用的なワークフローにおいては「たった一つの優れた回答」を得るだけでは不十分な場面が多い。ユーザーは、複数の多様な草案や代替案、あるいは異なるアプローチによる解決策を並列的に探索したいと考えるのが一般的である。また、外部のエバリュエーターやヒューリスティック、あるいは学習済みの判定器を通じてのみ得られる特定のスコアを最大化するような出力を探索する必要がある場合も存在する。しかし、現在の主要な手法は、トークン空間での繰り返しサンプリングや、以前の生成結果をコンテキストにフィードバックするプロンプトチェイニング、あるいはリジェクションサンプリングといった手法に依存している。 これらの従来手法には、いくつかの根本的な課題が存在している。第一に、生成プロセスにおいて逐次的な依存関係が導入されるため、計算の並列化が困難であり、試行錯誤を繰り返すたびにコンテキスト長が増大して計算コストが膨らむ傾向がある。第二に、これらのアプローチは、外部の最適化ループが直接制御できるような、安定した低次元のインターフェースを提供していない。…
核心:何を提案したのか
本研究では、LLMの生成を終点探索へと変換する「Output-Space Search(OS-Search)」を提案している。この手法の核心は、表現(Representation)と作動(Actuation)を完全にモジュール化し、外部ループが固定された3次元の出力空間(Z空間)内でターゲットを選択できるようにした点にある。まず、表現の側面では、凍結されたエンコーダと線形投影(PCAおよびバリマックス回転)を用いて、タスクの出力に対する固定された低次元の座標系を定義する。これにより、あらゆる生成物は3次元の数値ベクトルとして表現されるようになる。この座標系は、モデルの学習中も変更されないため、安定した制御インターフェースとして機能する。 次に、作動の側面では、要求されたターゲット座標に基づいて、検索によって得られた例示(エグゼンプラー)をプロンプトに組み込む「検索グラウンディング」を採用したポリシーを訓練する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related