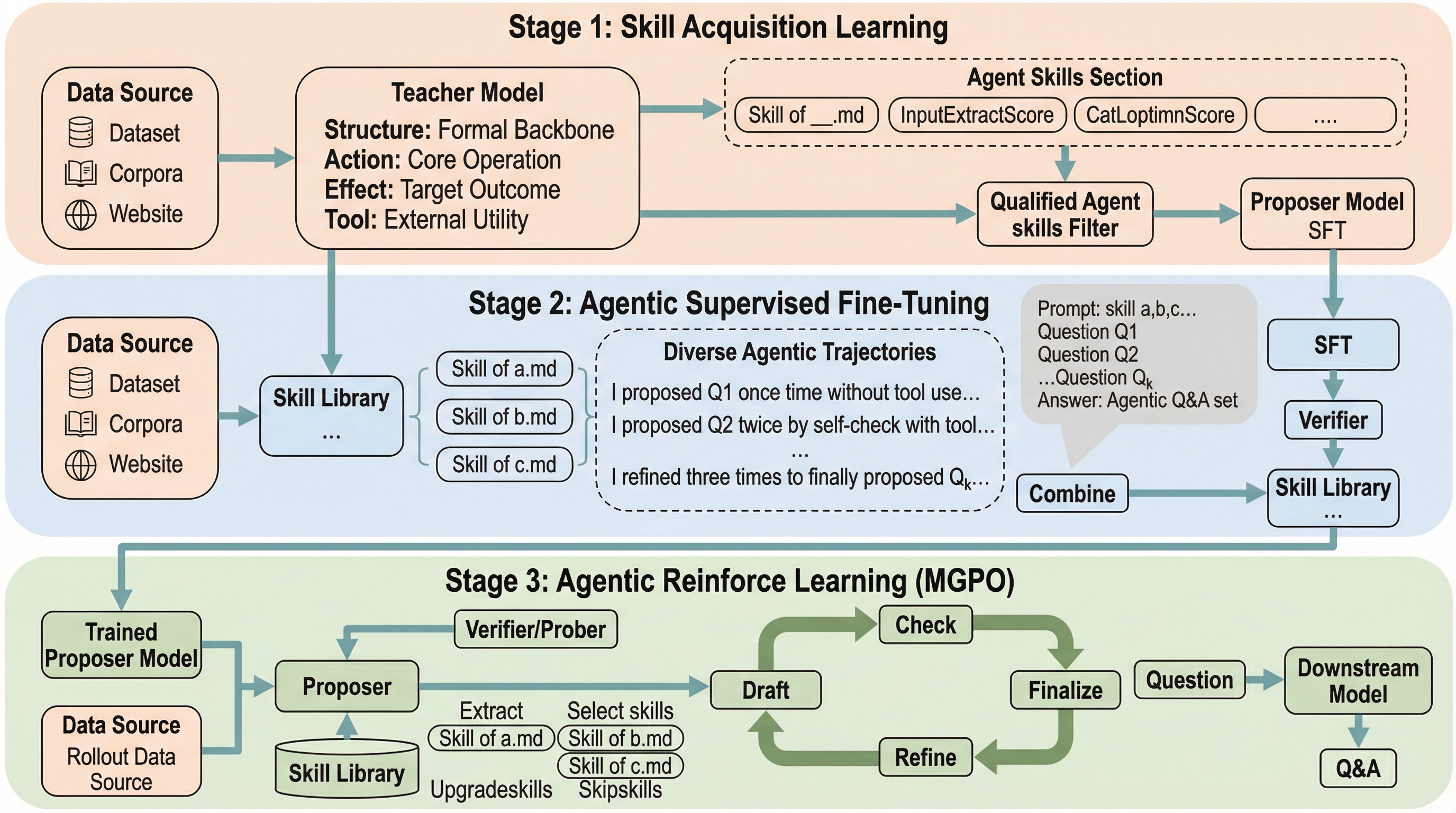
エージェンティックな提案:構成的スキル合成による大規模言語モデルの推論の強化
大規模言語モデルの複雑な推論能力を向上させるためには、高品質かつ検証可能な学習データセットが不可欠ですが、人間によるアノテーションはコストが極めて高く、大規模な拡張が困難であるという深刻な課題に直面しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの複雑な推論能力を向上させるためには、高品質かつ検証可能な学習データセットが不可欠ですが、人間によるアノテーションはコストが極めて高く、大規模な拡張が困難であるという深刻な課題に直面しています。
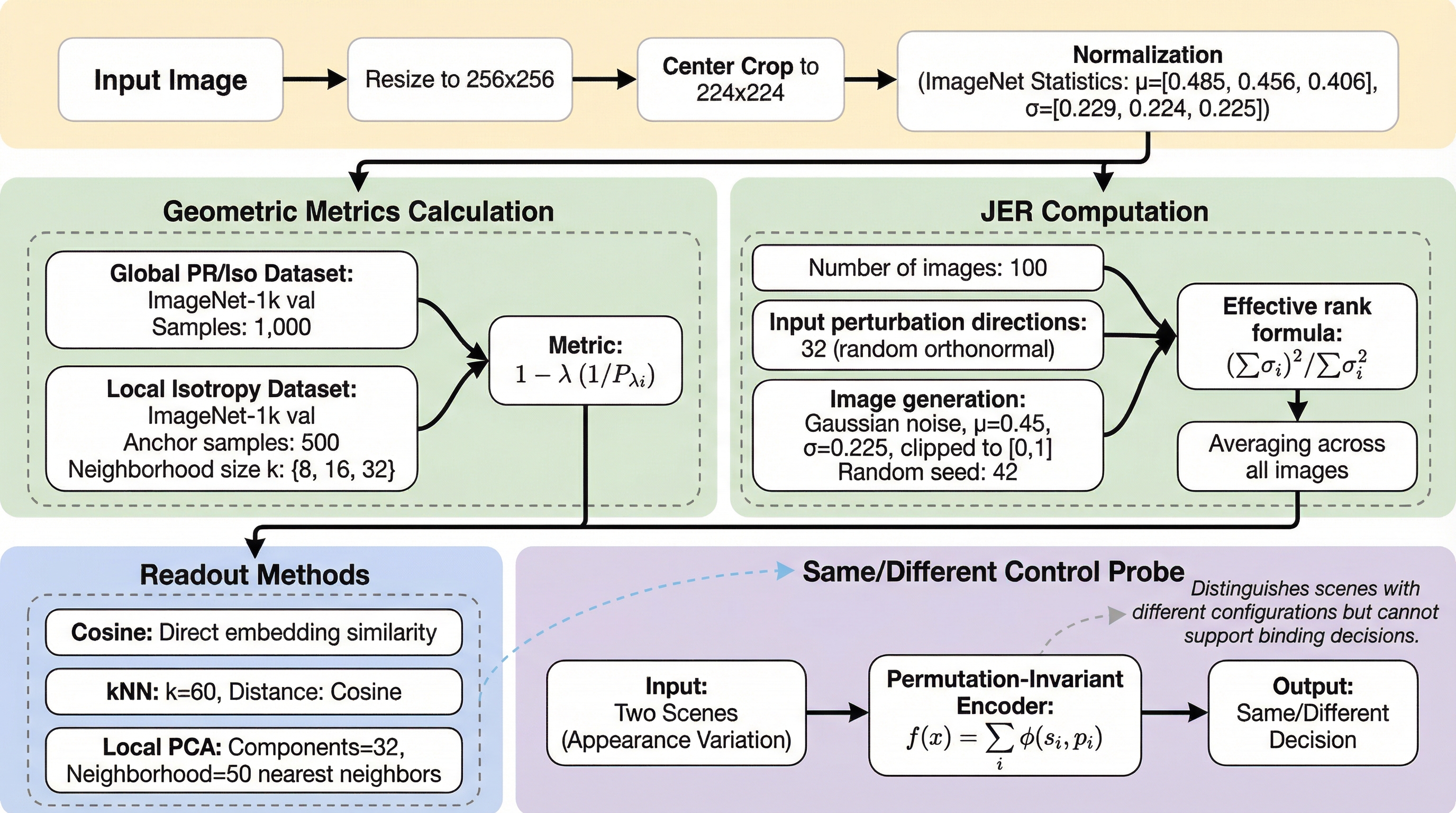
視覚表現学習において、埋め込み分布の均一性や等方性といったグローバルな幾何学的規則性は、要素間の関係性を捉える「構成的結合(Compositional Binding)」能力を予測する指標としては機能せず、統計的にほぼ無相関であることを明らかにした。
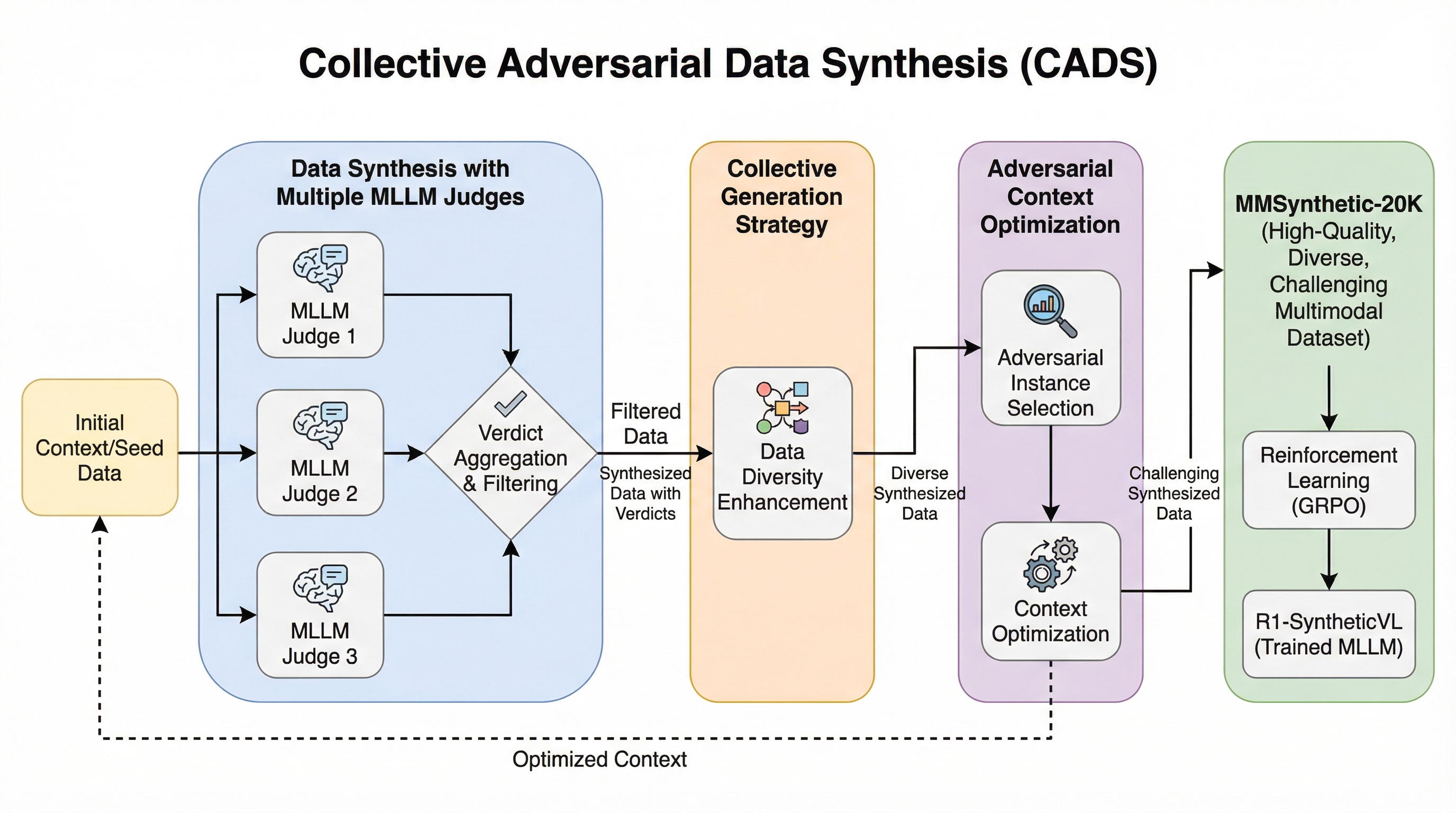
マルチモーダル大規模言語モデル(MLLM)の進化において、高品質な学習データの不足とアノテーションコストの増大が深刻な課題となっており、特に複雑な推論を必要とする実世界のタスクに対応するための思考の連鎖(CoT)を含むデータの入手は極めて困難です。
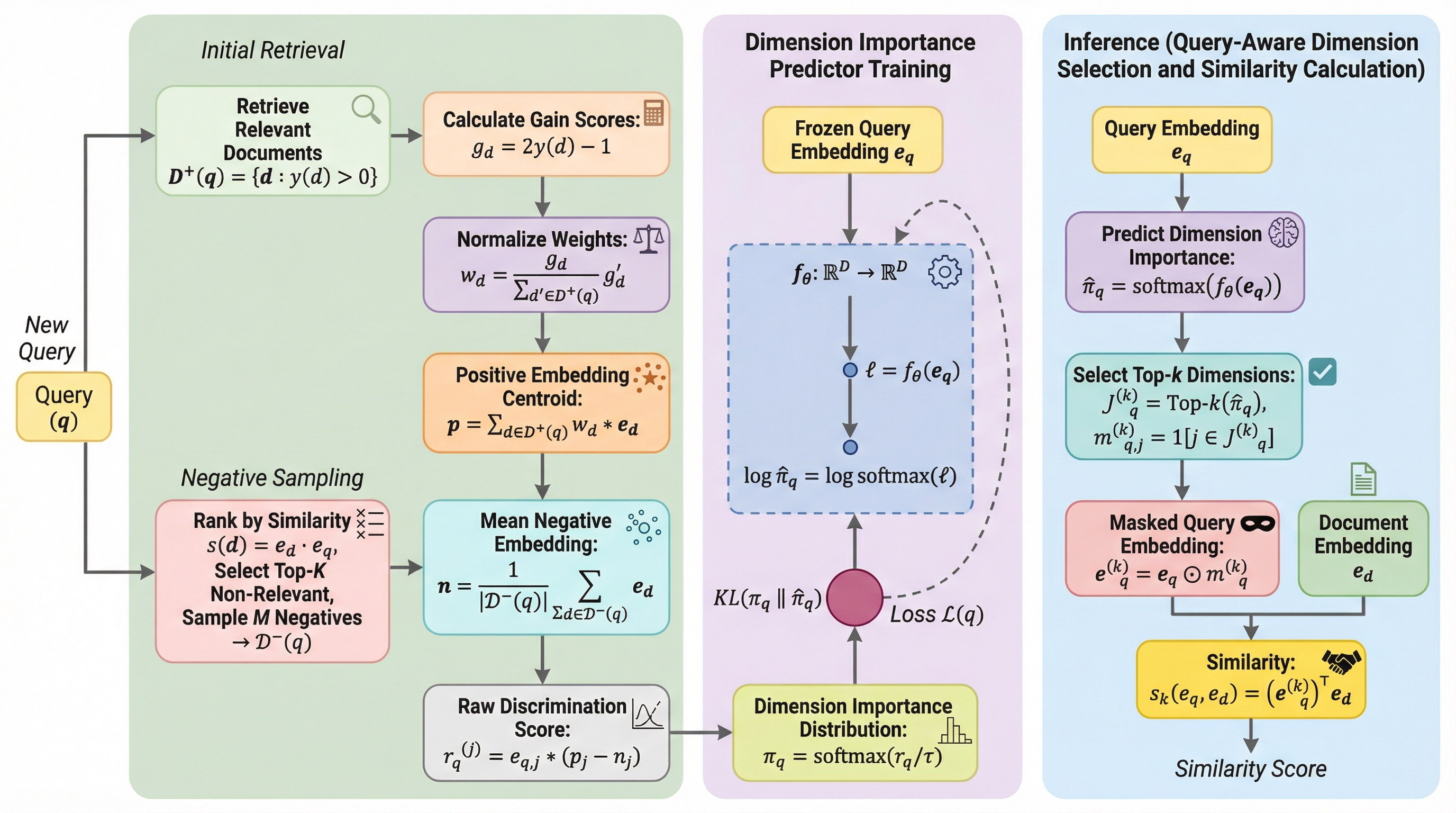
高密度検索における埋め込み表現の冗長性とノイズを排除するため、クエリごとに最適な次元を動的に選択する「クエリ適応型次元選択フレームワーク」が提案され、検索精度の向上と計算効率の両立が実証されました。
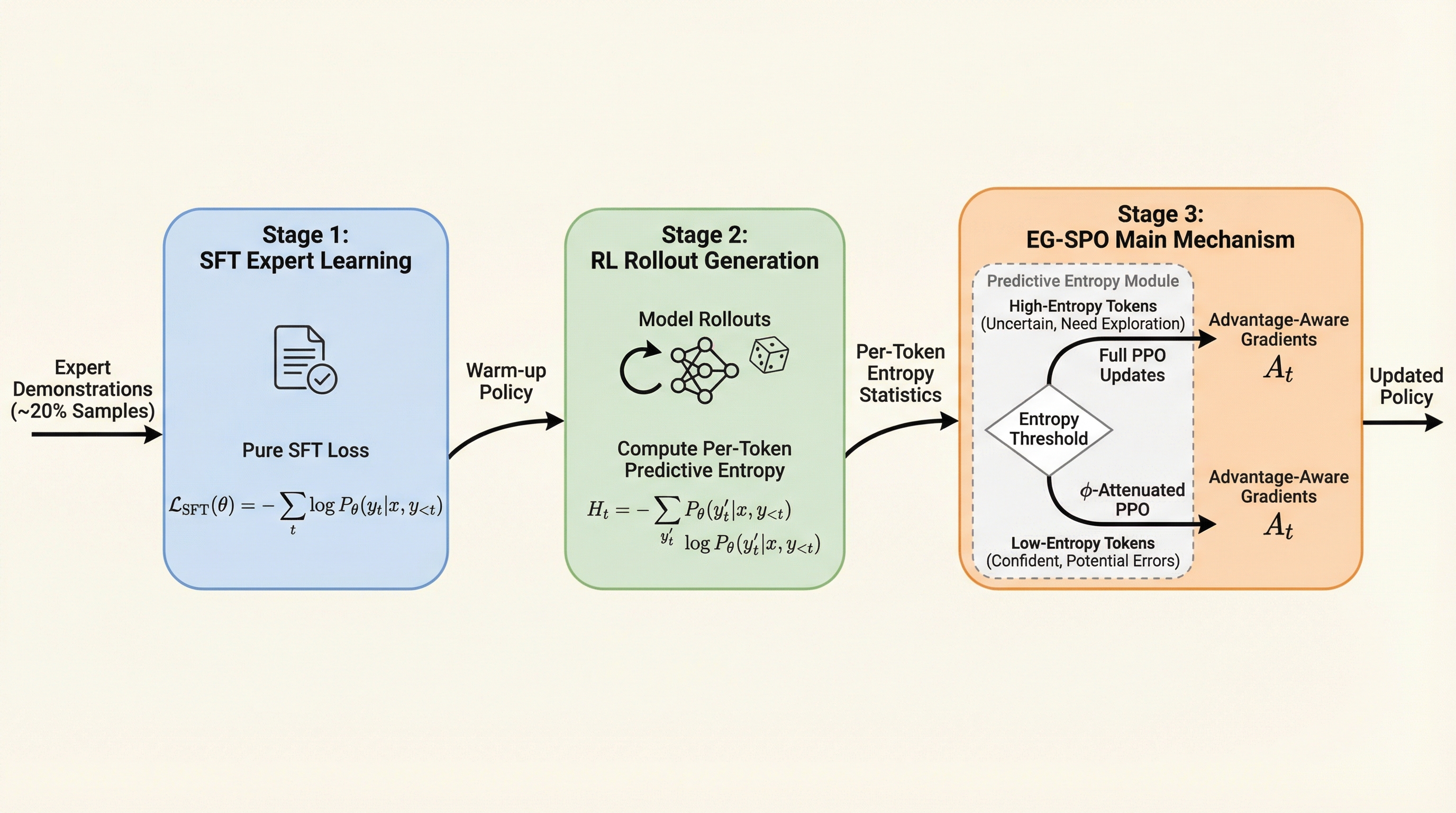
大規模言語モデルの学習において、教師あり微調整(SFT)と強化学習(RL)をトークン単位で動的に組み合わせる新しいフレームワーク「EG-SPO」が提案されました。この手法は予測エントロピーに基づき、不確実なトークンには探索を促すフル更新を、確信度の高いトークンには分散を抑える減衰更新を適用することで、学習の安定性と効率を両立させています。 数学的推論ベンチマークにおいて、既存のハイブリッド学習手法であるCHORD-φを最大3.8%上回る精度向上を達成しつつ、計算コストの増加をわずか3.4%に抑えることに成功しました。特に、低エントロピーのトークンに対してもアドバンテージ関数を保持することで、モデルが誤った回答を自信満々に出力した際にその誤りを強化してしまう「確信力のある誤り」の再強化を効果的に防いでいます。 本手法は、モデルが生成した回答内の全トークンを一律に扱うのではなく、学習信号の大部分を占める少数の重要なトークンに焦点を当てることで、限られた計算資源で最大限の性能を引き出すことを可能にしました。
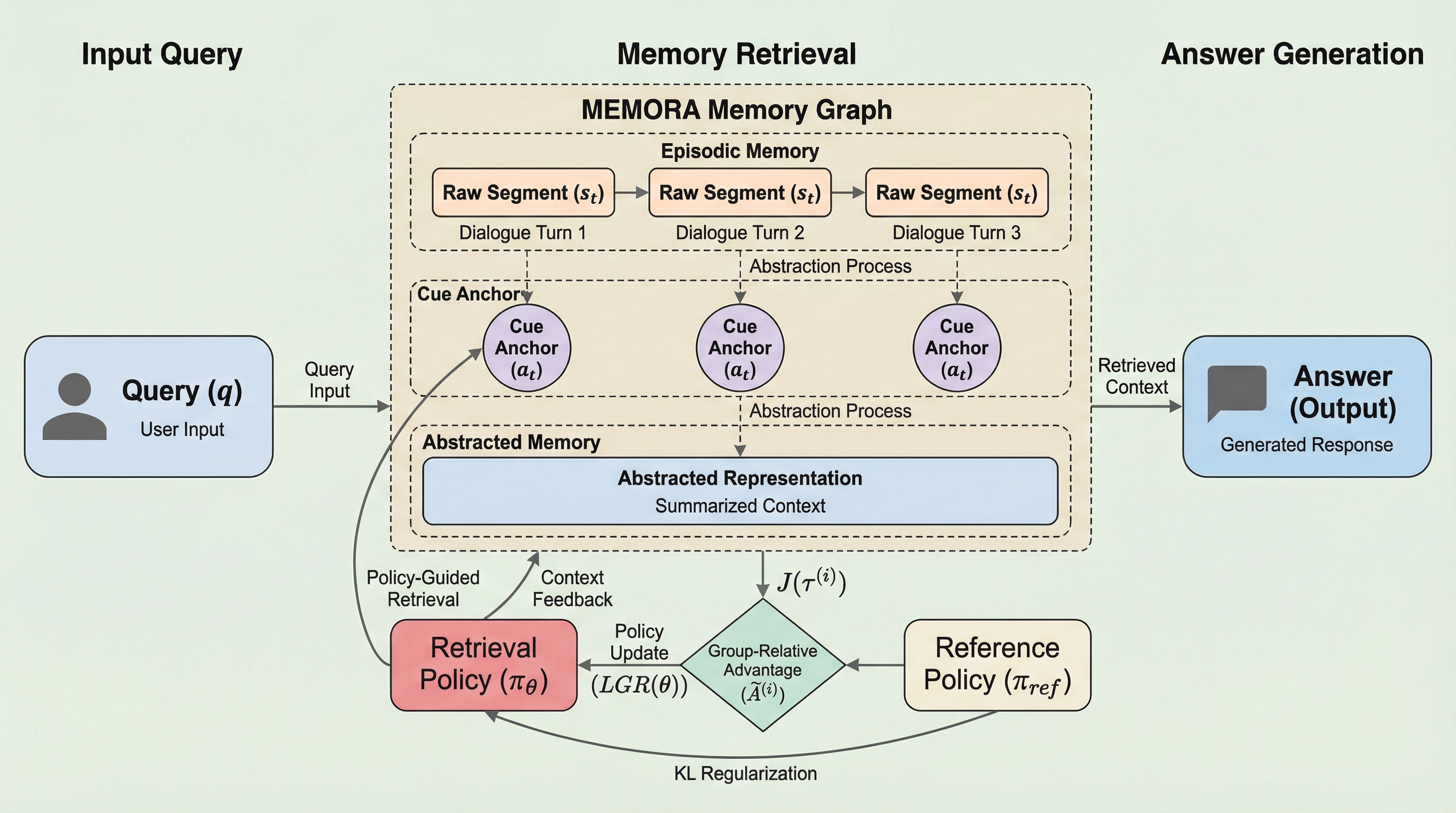
MEMORAは、自律エージェントが膨大な情報を蓄積しながら効率的かつ文脈に応じた検索を行うために開発された、抽象化と具体性のバランスを構造的に両立させる「調和型メモリ表現」である。情報の核となる「主要な抽象化」が具体的な「メモリ値」をインデックス化し、関連する更新を統合することで情報の断片化を防ぎつつ、多角的なアクセス経路となる「キュー・アンカー」によってメモリ間の広範な接続性を実現する。検索を能動的な推論プロセスとして扱うポリシー駆動型メカニズムを導入した結果、従来のRAGや知識グラフを上回る精度を達成し、フルコンテキスト処理と比較してトークン消費量を最大98%削減することに成功した。LoCoMoやLongMemEvalといったベンチマークで最高水準の性能を記録し、長期的な推論能力を大幅に向上させている。
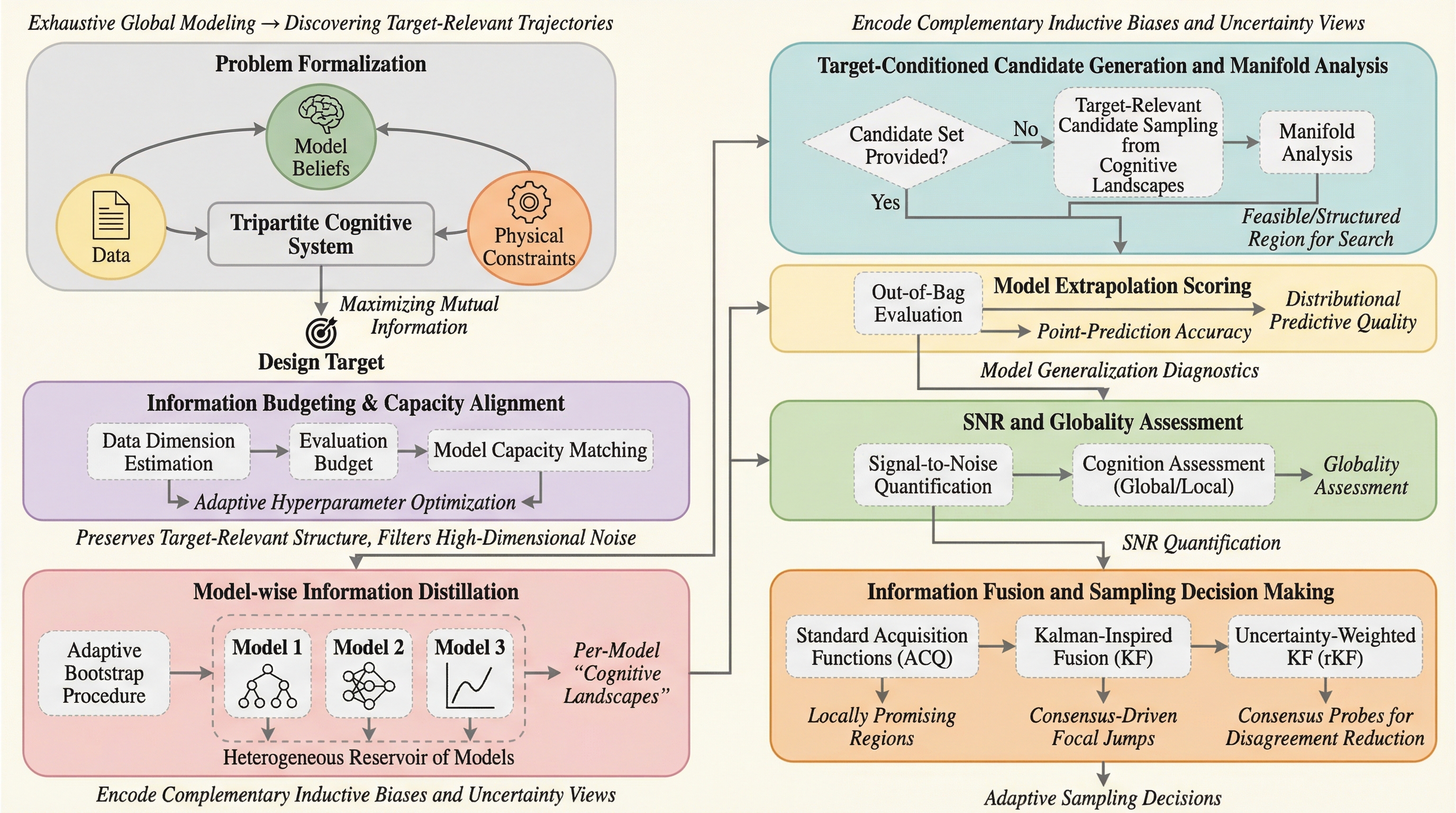
現代の材料科学における高次元かつ極めてデータが不足している環境下で、効率的に目標を達成するための情報理論に基づいた新しい適応的サンプリングの枠組みが提案されました。この手法は、全探索空間を近似するのではなく、目標に関連する「軌道」を特定することに焦点を当て、次元を考慮した情報予算管理や、カルマンフィルタに着想を得たマルチモデル融合を組み合わせています。14種類の材料設計タスクと複雑な数理ベンチマークを用いた検証により、わずか100回程度の評価でトップクラスの性能を持つ領域に到達できる高いサンプル効率と、多様な問題に対する堅牢性が実証されました。
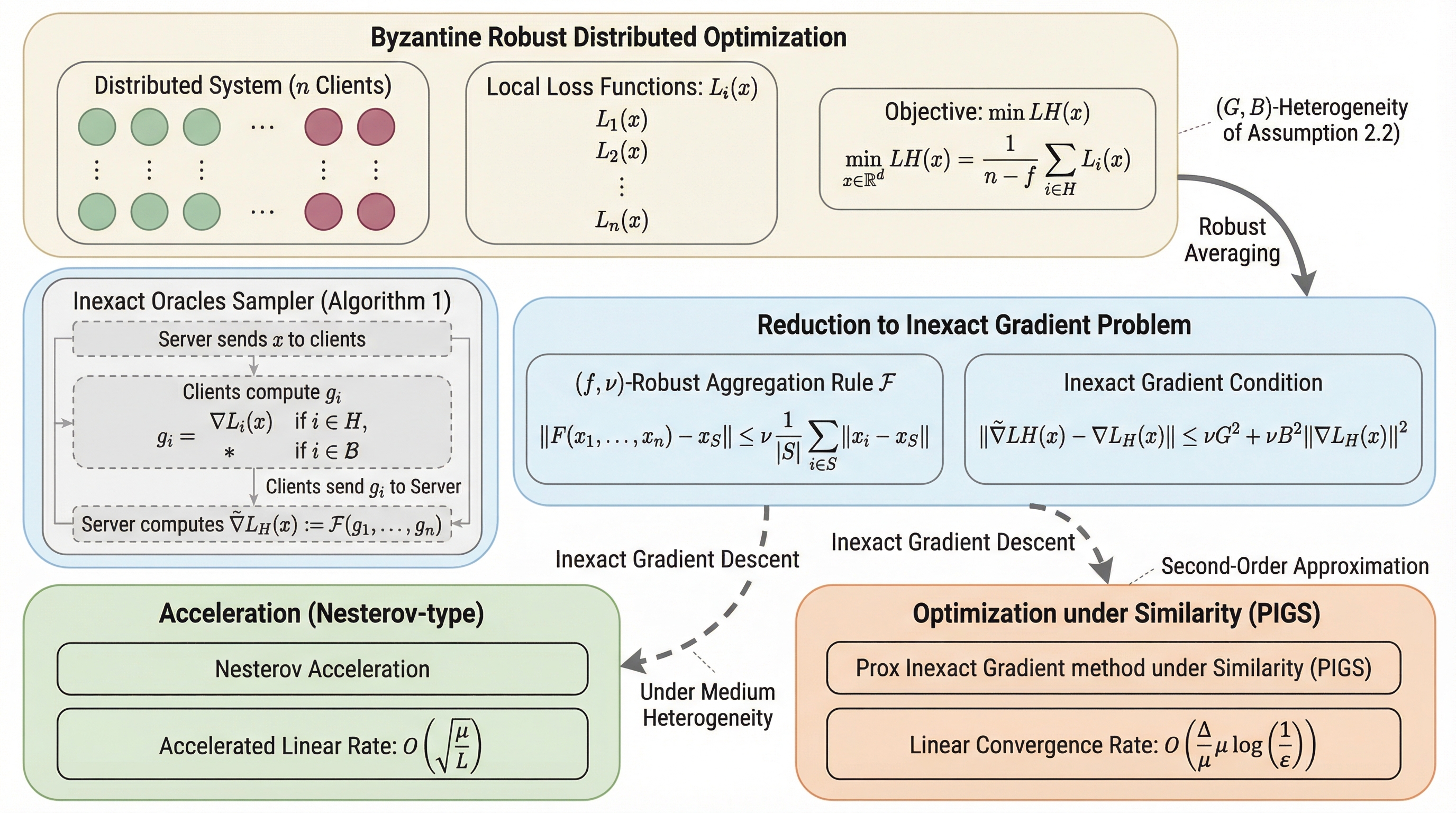
本研究は、分散学習におけるビザンチン故障への対策を「不正確な勾配オラクル」という統一的な理論枠組みに統合し、従来の場当たり的な解析手法を刷新しました。 この枠組みに基づき、通信効率を劇的に改善する「ネステロフ型加速アルゴリズム」と、サーバー側の補助情報を活用して収束を早める「PIGS法」の2つを新たに提案しました。
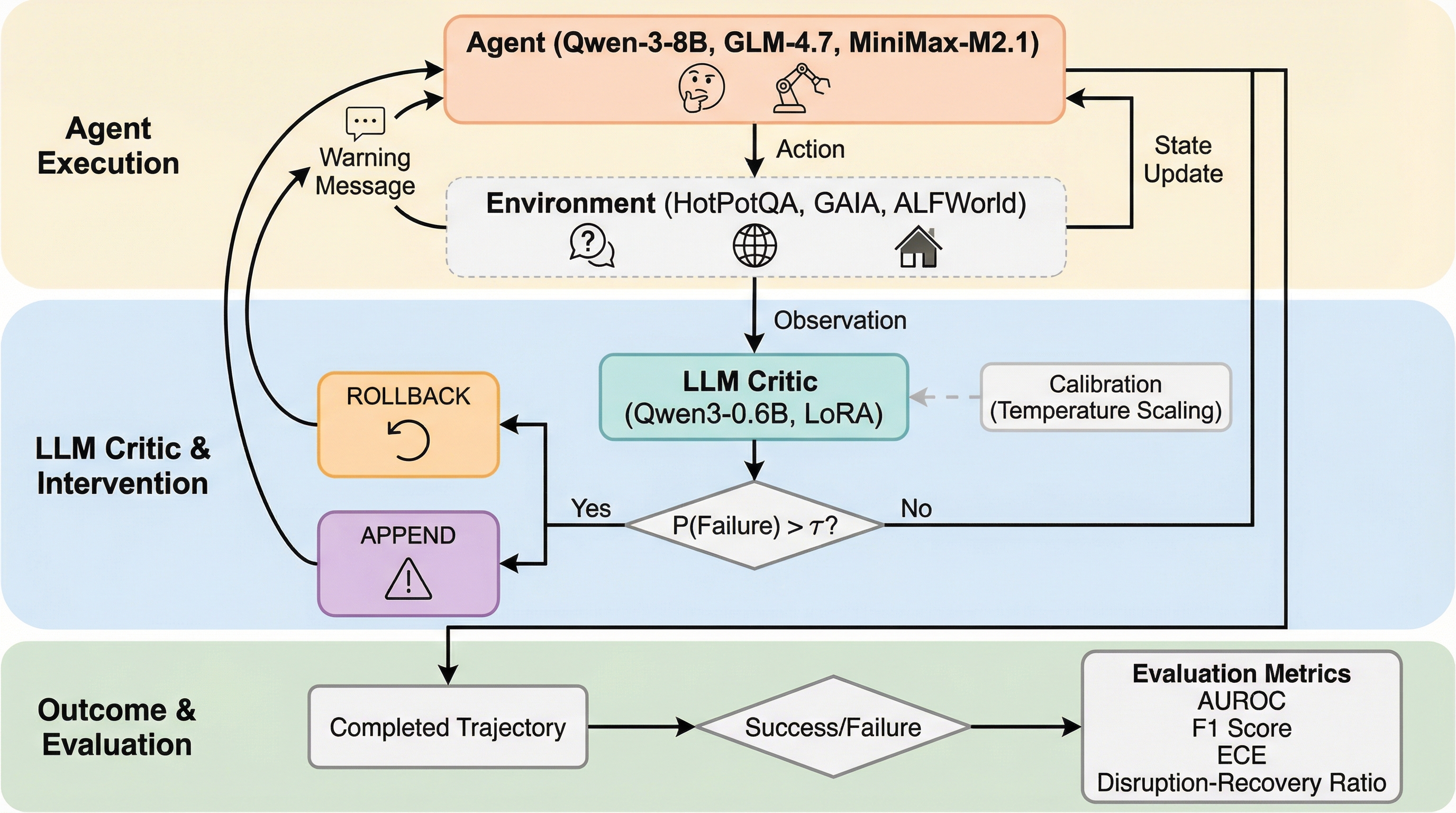
LLMエージェントの失敗を事前に検知する批判モデルは、たとえAUROC 0.94という極めて高い予測精度を持っていても、実際の運用時に介入を行うとエージェントの思考プロセスを破壊し、性能を大幅に低下させるリスクがあることが判明しました。
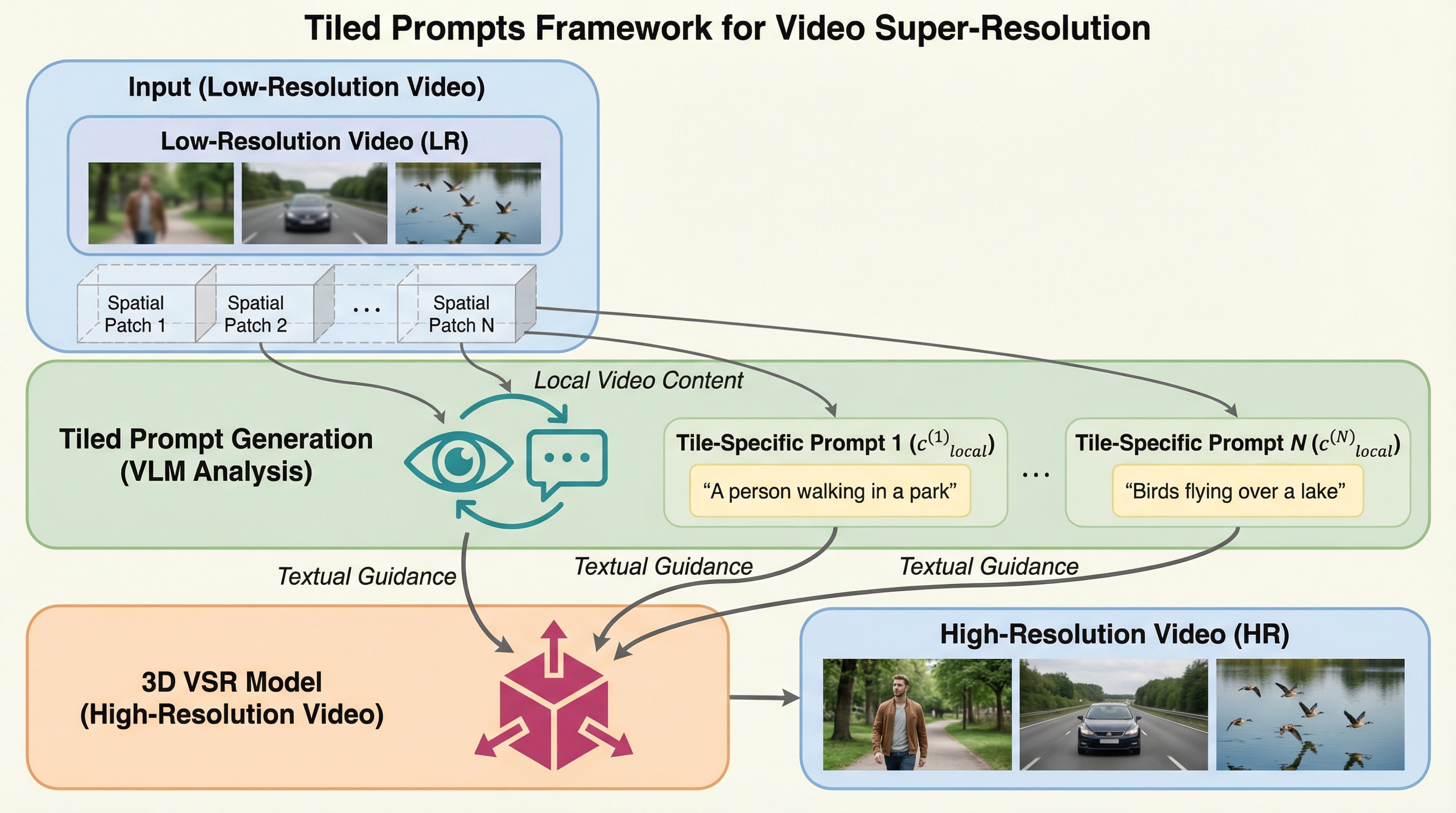
高解像度の画像やビデオの超解像処理において、画像全体を説明する単一のグローバルプロンプトでは、分割された各タイル領域の細部を正確に復元するための情報が不足し、誤った誘導が生じる「プロンプトの不十分さ」という問題が明らかになりました。