選択の学習:高密度検索のためのクエリを考慮した適応的次元選択
高密度検索における埋め込み表現の冗長性とノイズを排除するため、クエリごとに最適な次元を動的に選択する「クエリ適応型次元選択フレームワーク」が提案され、検索精度の向上と計算効率の両立が実証されました。
TL;DR(結論)
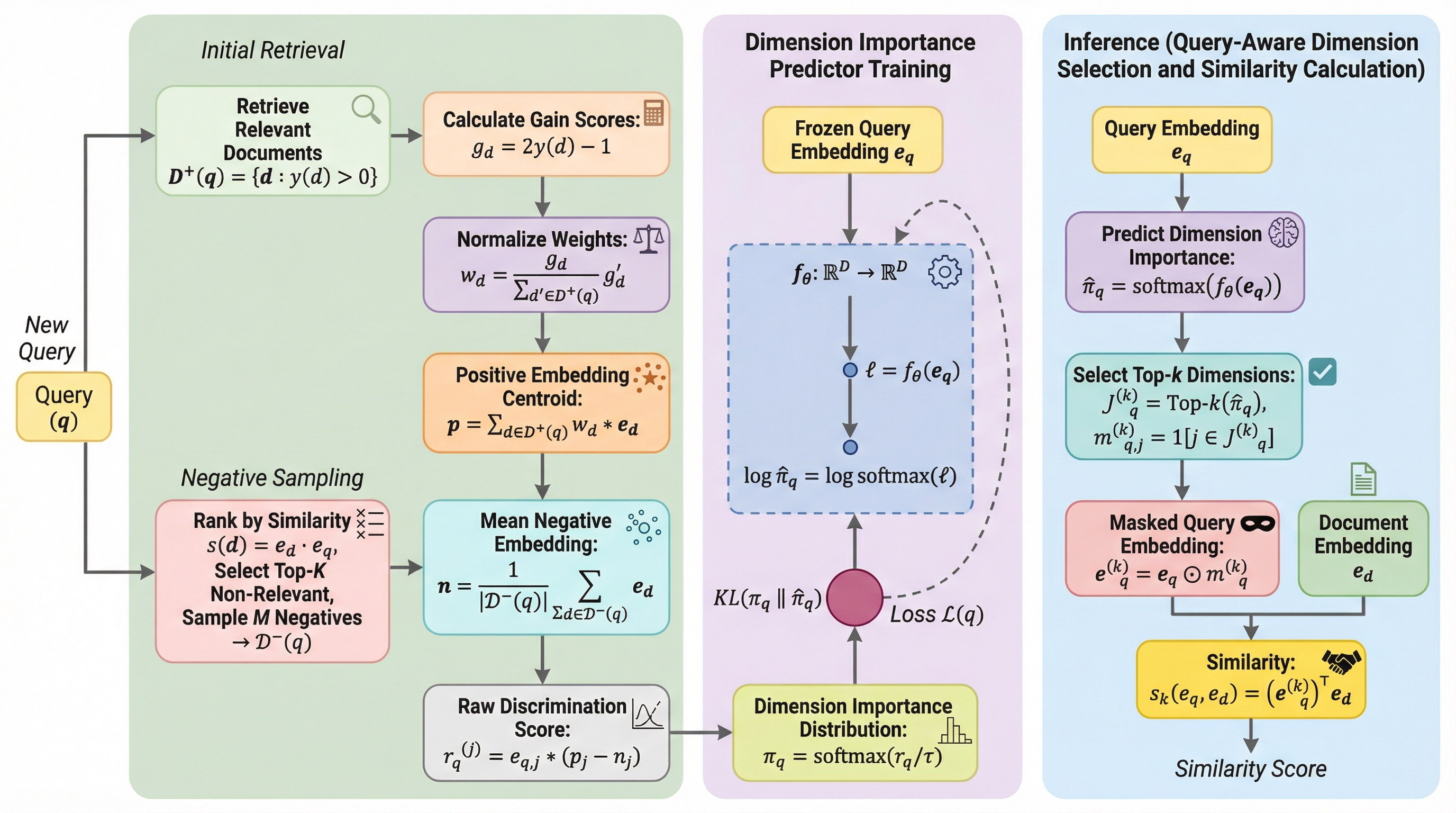
高密度検索における埋め込み表現の冗長性とノイズを排除するため、クエリごとに最適な次元を動的に選択する「クエリ適応型次元選択フレームワーク」が提案され、検索精度の向上と計算効率の両立が実証されました。 教師ありラベルから抽出した「オラクル」な次元重要度分布を軽量な予測器に蒸留することで、推論時に計算負荷の高い擬似適合フィードバックを必要とせず、クエリのベクトルのみから重要な次元を直接特定することが可能になりました。 多様なモデルとデータセットを用いた検証により、全次元を使用する従来手法を上回る精度をわずか20〜40%の次元保持率で達成し、文書側のインデックスを一切変更せずに既存システムへ容易に導入できる実用的な解決策を提示しています。
なぜこの問題か
現代の情報検索システムにおいて、クエリと文書を数千次元の高密度なベクトル空間に写像する「高密度検索」は、従来のキーワード一致に基づく手法を超え、高度な意味的類似性を捉えるための中心的な技術となっています。しかし、これらの高次元な埋め込み表現には、検索の有効性を阻害する大きな課題が潜んでいます。それは、特定のクエリ(情報ニーズ)に対して、すべての次元が一様に貢献しているわけではないという「次元の冗長性」の問題です。実際には、ランキングの精度に寄与するのは全次元のうちの一部に過ぎず、残りの次元は検索結果に影響を与えない中立的なものか、あるいは適合しない文書を誤って上位に引き上げてしまう「ノイズ」として機能している可能性が指摘されています。 これまでの研究では、この冗長性に対処するために「擬似適合フィードバック(PRF)」を利用して、クエリごとに重要な次元を推定する手法が試みられてきました。しかし、これらの手法はラベルなしデータで動作するという利点がある一方で、検索の初期段階で得られたノイズの多い擬似的な信号に依存するため、推定の精度が不安定になりやすいという欠点があります。…
核心:何を提案したのか
本研究が提案する「クエリ適応型次元選択(Query-Aware Adaptive Dimension Selection)」フレームワークは、クエリの埋め込みベクトルそのものから、その検索意図にとってどの次元が重要であるかを直接予測する手法です。このアプローチの核心は、トレーニングデータに含まれる適合性ラベル(どの文書がどのクエリに対して正解かという情報)を利用して、各クエリに対する「理想的な次元重要度(オラクル)」を算出し、その知見を軽量な予測器に「蒸留(ディストリレーション)」するという点にあります。これにより、推論時には正解ラベルや擬似適合フィードバックを一切使わずに、クエリのベクトルを入力するだけで、瞬時に最適な次元のマスクを生成することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related