Tiled Prompts: 画像およびビデオ超解像におけるプロンプトの不十分さの克服
高解像度の画像やビデオの超解像処理において、画像全体を説明する単一のグローバルプロンプトでは、分割された各タイル領域の細部を正確に復元するための情報が不足し、誤った誘導が生じる「プロンプトの不十分さ」という問題が明らかになりました。
TL;DR(結論)
高解像度の画像やビデオの超解像処理において、画像全体を説明する単一のグローバルプロンプトでは、分割された各タイル領域の細部を正確に復元するための情報が不足し、誤った誘導が生じる「プロンプトの不十分さ」という問題が明らかになりました。 本研究が提案する「Tiled Prompts」は、視覚言語モデル(VLM)を活用して各タイル領域ごとに最適化された個別のローカルプロンプトを生成し、領域ごとの意味的な情報を補強することで、文字の再現性や細部の視覚的品質を大幅に向上させる統一的なフレームワークです。 この手法は画像とビデオの両方に適用可能であり、従来の単一プロンプト手法で発生していた情報の欠落(スパース性)や、無関係な情報による誤誘導(ミスガイダンス)を解消し、計算負荷を最小限に抑えつつ、より正確でアーティファクトの少ない高解像度化を実現します。
なぜこの問題か
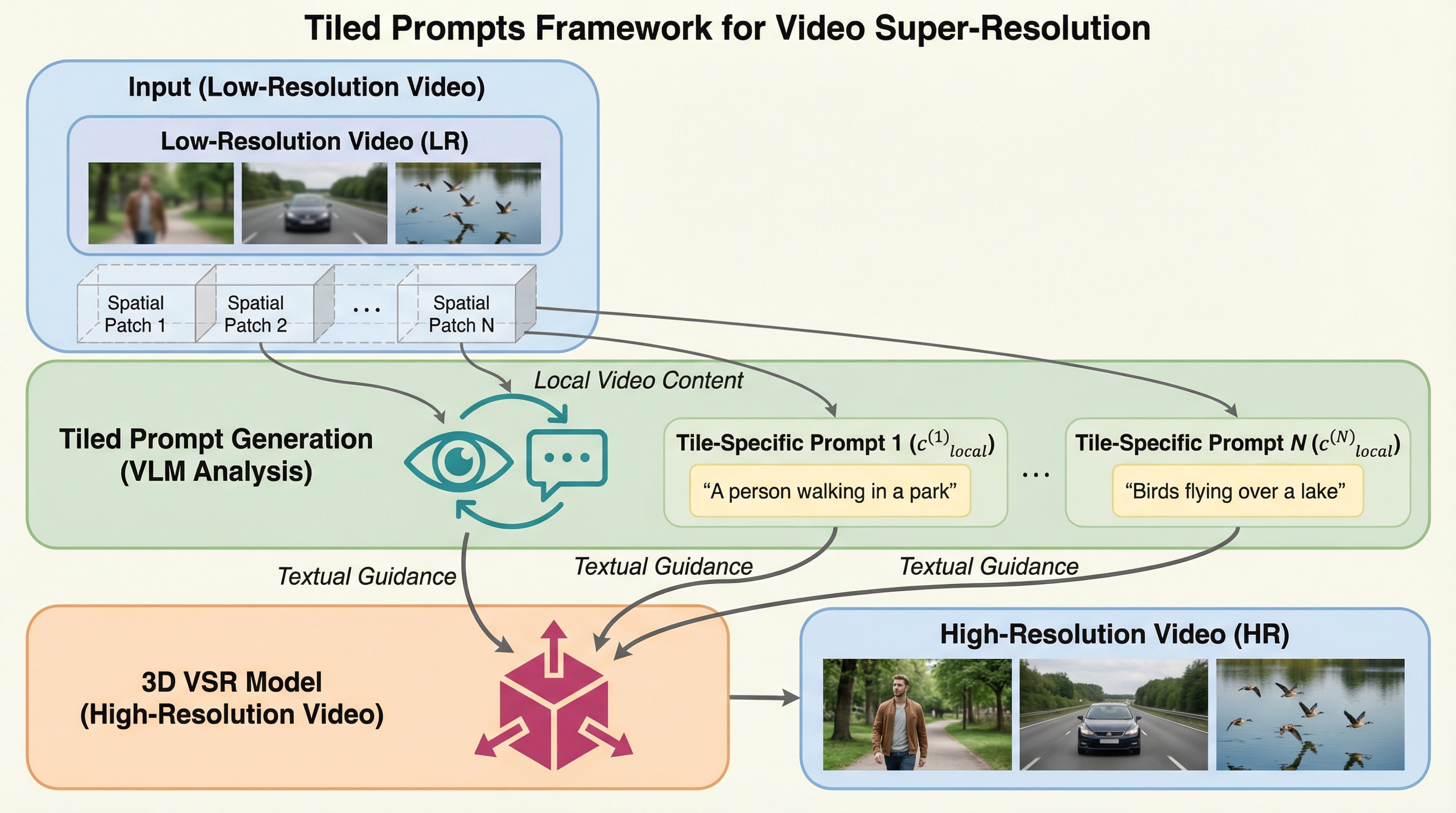
単一画像超解像(SISR)は、低解像度(LR)の入力から高解像度(HR)の表現を回復することを目的としていますが、これは一つの入力に対して複数の正解が存在し得る不良設定問題(ill-posed problem)です。近年の拡散モデルを用いた手法では、テキストプロンプトをセマンティックな事前情報として利用することで、この問題に対処しています。しかし、解像度が4Kなどの極端に高いレベルに達すると、ビデオメモリ(VRAM)の制限から、画像全体を一度に処理するのではなく、小さなタイルに分割して処理する「潜在タイル戦略(latent tiling strategy)」が一般的に用いられます。 このタイリング処理において、画像全体を説明する単一の「グローバルプロンプト」を使用すると、個々のタイル領域に対しては情報が不十分になる「プロンプトの不十分さ(prompt underspecification)」という深刻な問題が発生します。…
核心:何を提案したのか
本研究では、画像およびビデオの超解像におけるプロンプトの不十分さを克服するための統一フレームワークとして「Tiled Prompts」を提案しました。この手法の核心は、画像全体に対して一つのプロンプトを割り当てるのではなく、分割された各タイル領域に対して、その領域の内容を詳細に記述した「タイル固有のプロンプト(c_local)」を個別に生成し、適用することにあります。 具体的には、視覚言語モデル(VLM)をプロンプト抽出器として利用し、各低解像度タイルから直接、その領域に特化した高密度な記述を抽出します。これにより、各タイルの復元プロセスにおいて、その場所にあるべき具体的な物体や文字、テクスチャに関する正確なセマンティック・アンカー(意味的な手がかり)を提供することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related