エントロピーゲート付き選択的方策最適化:大規模言語モデルのハイブリッド学習のためのトークンレベルの勾配割り当て
大規模言語モデルの学習において、教師あり微調整(SFT)と強化学習(RL)をトークン単位で動的に組み合わせる新しいフレームワーク「EG-SPO」が提案されました。この手法は予測エントロピーに基づき、不確実なトークンには探索を促すフル更新を、確信度の高いトークンには分散を抑える減衰更新を適用することで、学習の安定性と効率を両立させています。 数学的推論ベンチマークにおいて、既存のハイブリッド学習手法であるCHORD-φを最大3.8%上回る精度向上を達成しつつ、計算コストの増加をわずか3.4%に抑えることに成功しました。特に、低エントロピーのトークンに対してもアドバンテージ関数を保持することで、モデルが誤った回答を自信満々に出力した際にその誤りを強化してしまう「確信力のある誤り」の再強化を効果的に防いでいます。 本手法は、モデルが生成した回答内の全トークンを一律に扱うのではなく、学習信号の大部分を占める少数の重要なトークンに焦点を当てることで、限られた計算資源で最大限の性能を引き出すことを可能にしました。
TL;DR(結論)
大規模言語モデルの学習において、教師あり微調整(SFT)と強化学習(RL)をトークン単位で動的に組み合わせる新しいフレームワーク「EG-SPO」が提案されました。この手法は予測エントロピーに基づき、不確実なトークンには探索を促すフル更新を、確信度の高いトークンには分散を抑える減衰更新を適用することで、学習の安定性と効率を両立させています。 数学的推論ベンチマークにおいて、既存のハイブリッド学習手法であるCHORD-φを最大3.8%上回る精度向上を達成しつつ、計算コストの増加をわずか3.4%に抑えることに成功しました。特に、低エントロピーのトークンに対してもアドバンテージ関数を保持することで、モデルが誤った回答を自信満々に出力した際にその誤りを強化してしまう「確信力のある誤り」の再強化を効果的に防いでいます。 本手法は、モデルが生成した回答内の全トークンを一律に扱うのではなく、学習信号の大部分を占める少数の重要なトークンに焦点を当てることで、限られた計算資源で最大限の性能を引き出すことを可能にしました。
なぜこの問題か
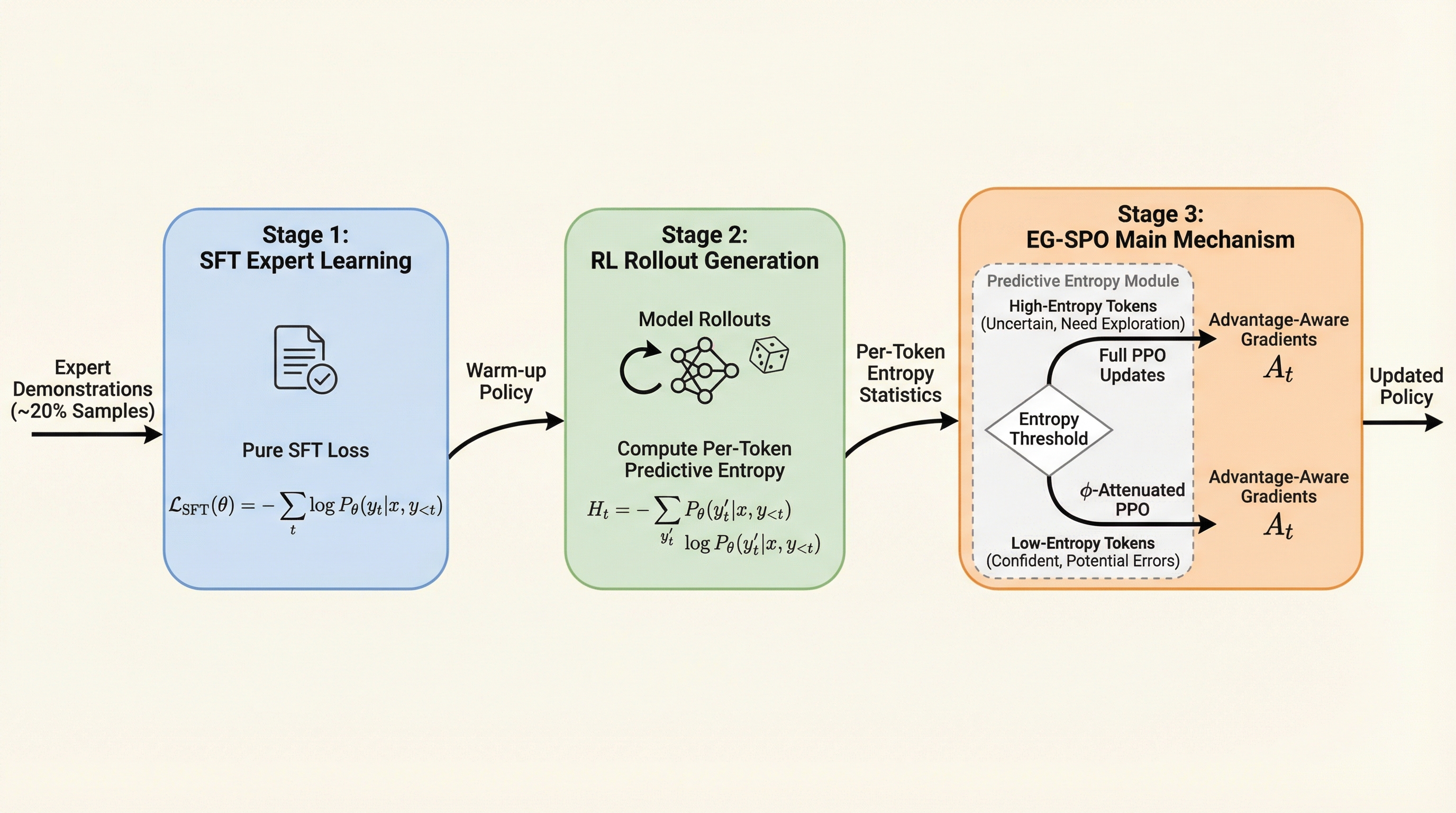
大規模言語モデル(LLM)の最適化において、専門家のデモンストレーションを模倣する教師あり微調整(SFT)と、報酬に基づく探索を行う強化学習(RL)は、それぞれ補完的な役割を担っています。SFTは知識の定着に優れていますが、学習データの分布を超えた探索が困難であるという課題があり、一方でRLは創造的な問題解決を促すものの、学習の不安定さやサンプル効率の悪さが指摘されてきました。近年の研究では、これら二つの手法をサンプル単位で混合するハイブリッド戦略が模索されていますが、既存手法の多くは生成された回答(ロールアウト)内のすべてのトークンを一律に扱っています。 しかし、実際には回答内の特定のトークン(全体の10〜20%程度)が学習信号の大部分を占めていることが先行研究で示唆されており、すべてのトークンを均一に最適化することは非効率であると考えられます。また、トークン単位で学習手法を切り替える際には、文脈の不一致(Trajectory Mismatch)という問題が発生します。…
核心:何を提案したのか
本研究が提案する「Entropy-Gated Selective Policy Optimization(EG-SPO)」は、サンプルレベルの混合学習をトークンレベルの勾配変調へと拡張した、三段階のトレーニングフレームワークです。この手法の核心は、各トークンの「予測エントロピー(不確実性)」をゲートとして利用し、学習の重みを動的に割り当てる点にあります。EG-SPOは、以下の三つのステージで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related