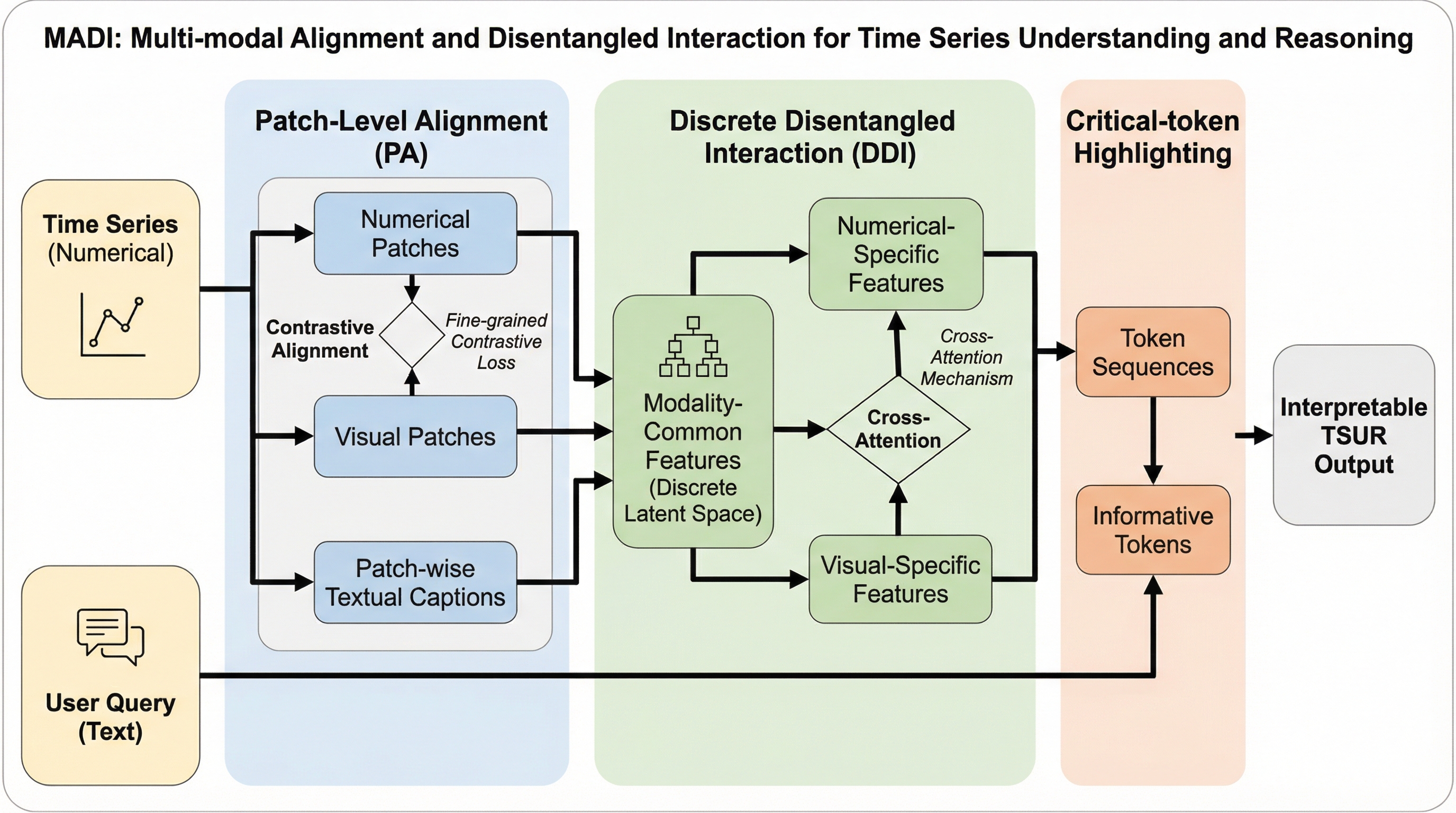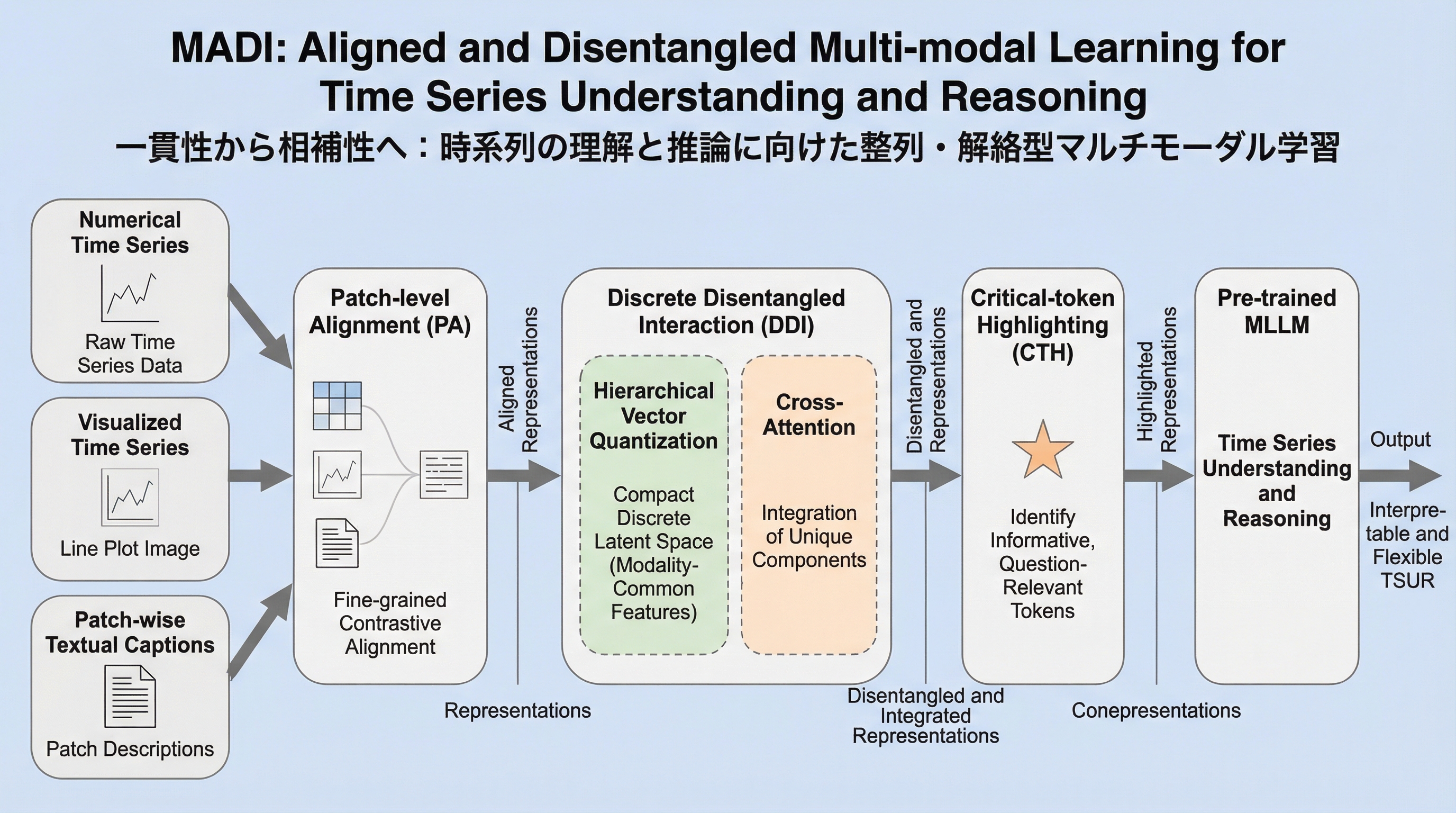
多重表現生成を通じた統一マルチモーダルモデルにおける生成による理解の強化
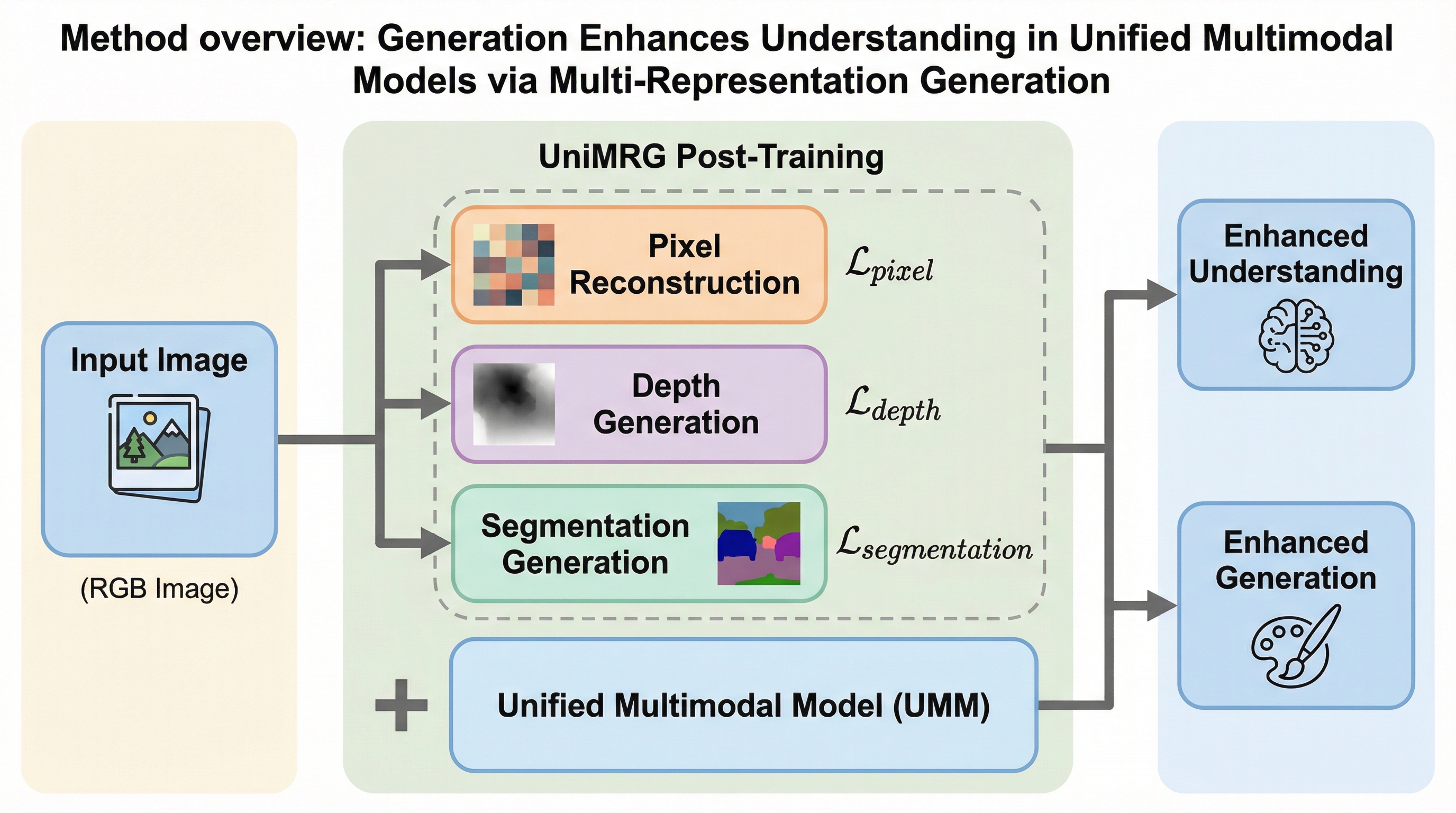
統一マルチモーダルモデル(UMM)において、画像生成タスクを補助的に活用することで視覚的理解能力を飛躍的に向上させる新しい学習手法「UniMRG」が提案されました。 従来のピクセル再構成に加え、幾何学的な奥行き(デプス)や構造的なセグメンテーションといった複数の内部表現を生成させることで、モデルは空間関係や物体の境界をより深く学習します。 実験では、微細な知覚能力の向上やハルシネーションの抑制、空間認識の強化が確認され、理解タスクの精度向上と同時に画像生成の質も高まるという相乗効果が実証されました。