難易度を考慮した強化学習による大規模推論モデルの過剰思考の軽減
大規模推論モデル(LRM)が単純な課題に対しても過剰に長い思考プロセスを生成してしまう「オーバーシンキング」問題を解決するため、タスクの難易度を自己認識して推論の深さを動的に調整する強化学習フレームワーク「DiPO」が提案されました。
TL;DR(結論)
大規模推論モデル(LRM)が単純な課題に対しても過剰に長い思考プロセスを生成してしまう「オーバーシンキング」問題を解決するため、タスクの難易度を自己認識して推論の深さを動的に調整する強化学習フレームワーク「DiPO」が提案されました。 この手法は、モデル自身の出力長を難易度の指標として活用し、正解率を維持しながら不要な冗長性を排除する難易度認識型報酬関数を導入することで、手動のアノテーションに頼らずに効率的な思考の圧縮を実現しています。 実験の結果、数学的推論や広範なドメインのタスクにおいて、正解精度を損なうことなくトークン数を大幅に削減することに成功し、モデルがタスクの複雑さに応じて計算リソースを最適に配分できる能力を持つことが証明されました。
なぜこの問題か
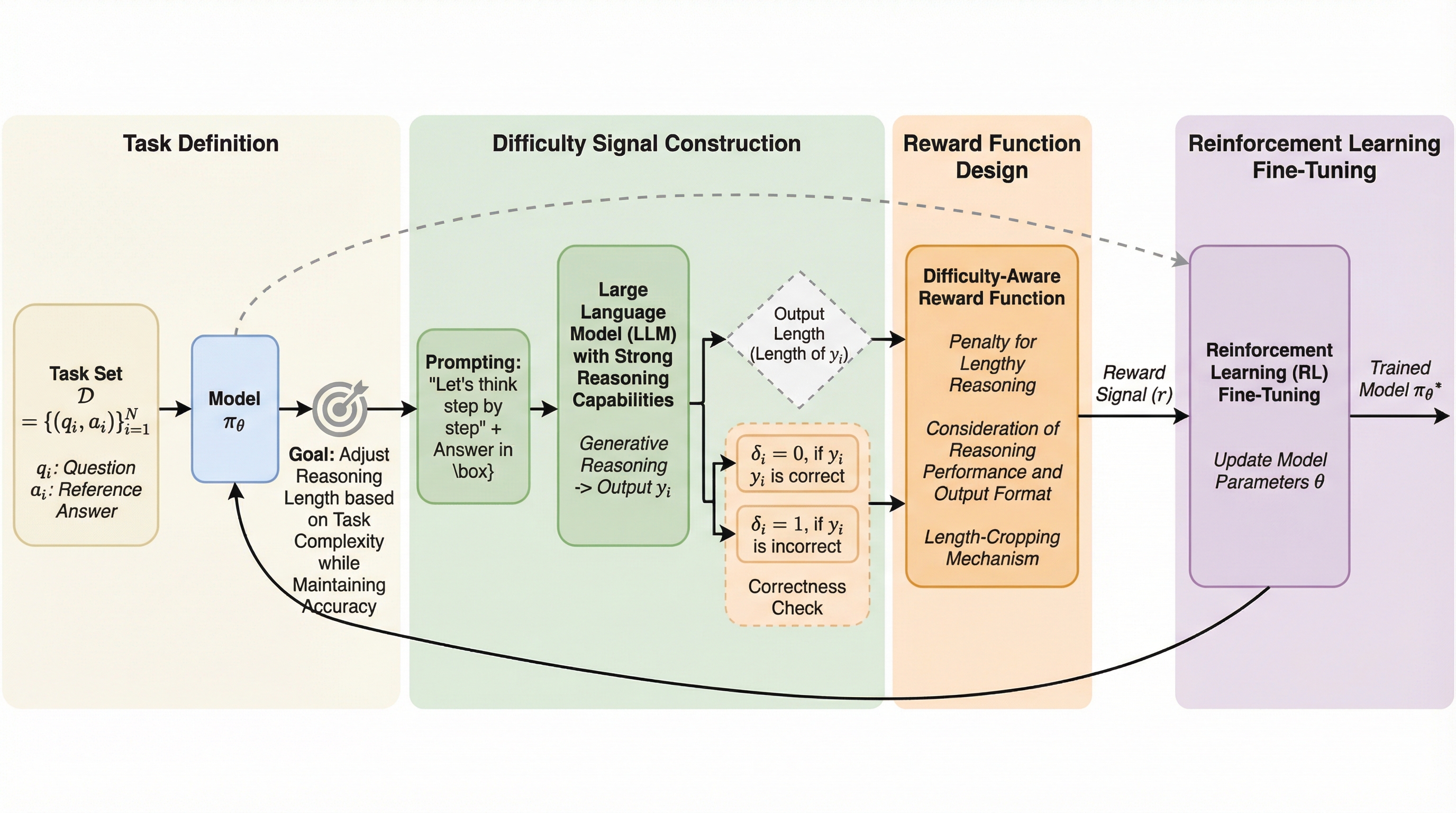
大規模推論モデル(LRM)は、人間の深い思考行動を模倣する明示的な思考の連鎖(Chain-of-Thought)を展開することで、複雑なタスクにおいて優れた性能を発揮します。しかし、この深い思考モードは、単純なタスクを処理する際にも不必要に長い推論を引き起こし、計算リソースの浪費や推論の非効率性を招くという副作用があります。この現象は「オーバーシンキング」と呼ばれ、特に迅速な応答や簡潔な回答が求められるシナリオにおいて顕著な課題となっています。例えば、「3.8と3.11のどちらが大きいか」という極めて単純な比較問題に対し、従来のLRMであるQwen3-4Bは853トークンもの冗長な思考プロセスを生成したのに対し、標準的な大規模言語モデルであるGPT-4oはわずか13トークンで回答しています。 研究チームは、このオーバーシンキングの根本的な原因が、事後学習(ポストトレーニング)段階で採用される報酬関数の設計にあると分析しています。従来の学習目標は、一定のトークン制限内で正解を導き出すことに特化しており、生成にかかるコストや効率性が軽視されていました。…
核心:何を提案したのか
本論文では、大規模推論モデルのオーバーシンキング問題を系統的に緩和するための強化学習ベースの学習フレームワーク「Difficulty-aware Policy Optimization(DiPO)」を提案しています。DiPOの核心的なアイデアは、モデルが推論プロセスの中でタスクの難易度を自発的にモデル化し、それを強化学習の枠組みに統合することで、事後学習によって導入された生成の偏りを修正することにあります。このフレームワークは、モデルがタスクの複雑さを評価し、それに応じて不必要に長い推論ステップを合理的に圧縮することを促します。 具体的には、モデル自身の自己推論に基づいた難易度モデリング手法を導入しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related