SAGE:生成的推薦のためのシーケンスレベルの適応的勾配進化
既存の生成型推薦システムが抱える専用語彙への依存と、固定的な勾配制限によるコールドスタート項目の抑制および多様性の欠如という課題を解決するため、大規模言語モデルの語彙を直接再利用しつつ、シーケンスレベルで最適化を行う新たなフレームワークであるSAGEを提案した。
TL;DR(結論)
既存の生成型推薦システムが抱える専用語彙への依存と、固定的な勾配制限によるコールドスタート項目の抑制および多様性の欠如という課題を解決するため、大規模言語モデルの語彙を直接再利用しつつ、シーケンスレベルで最適化を行う新たなフレームワークであるSAGEを提案した。 SAGEは幾何平均を用いた重要度比率によってトークン単位のノイズを排除する信号デカップリングと、有望な新規項目への超線形な更新を可能にするブースト因子、および多様性の低い推薦を抑制するエントロピー考慮型罰則からなる非対称な動的勾配制御を導入している。 Amazonのデータセットを用いた検証の結果、SAGEは従来の最適化手法であるGBPOの数値的安定性を維持しながら、新規項目の露出を劇的に改善し、情報のタコツボ化を防いで推薦リストの多様性と正確性を大幅に向上させることに成功した。
なぜこの問題か
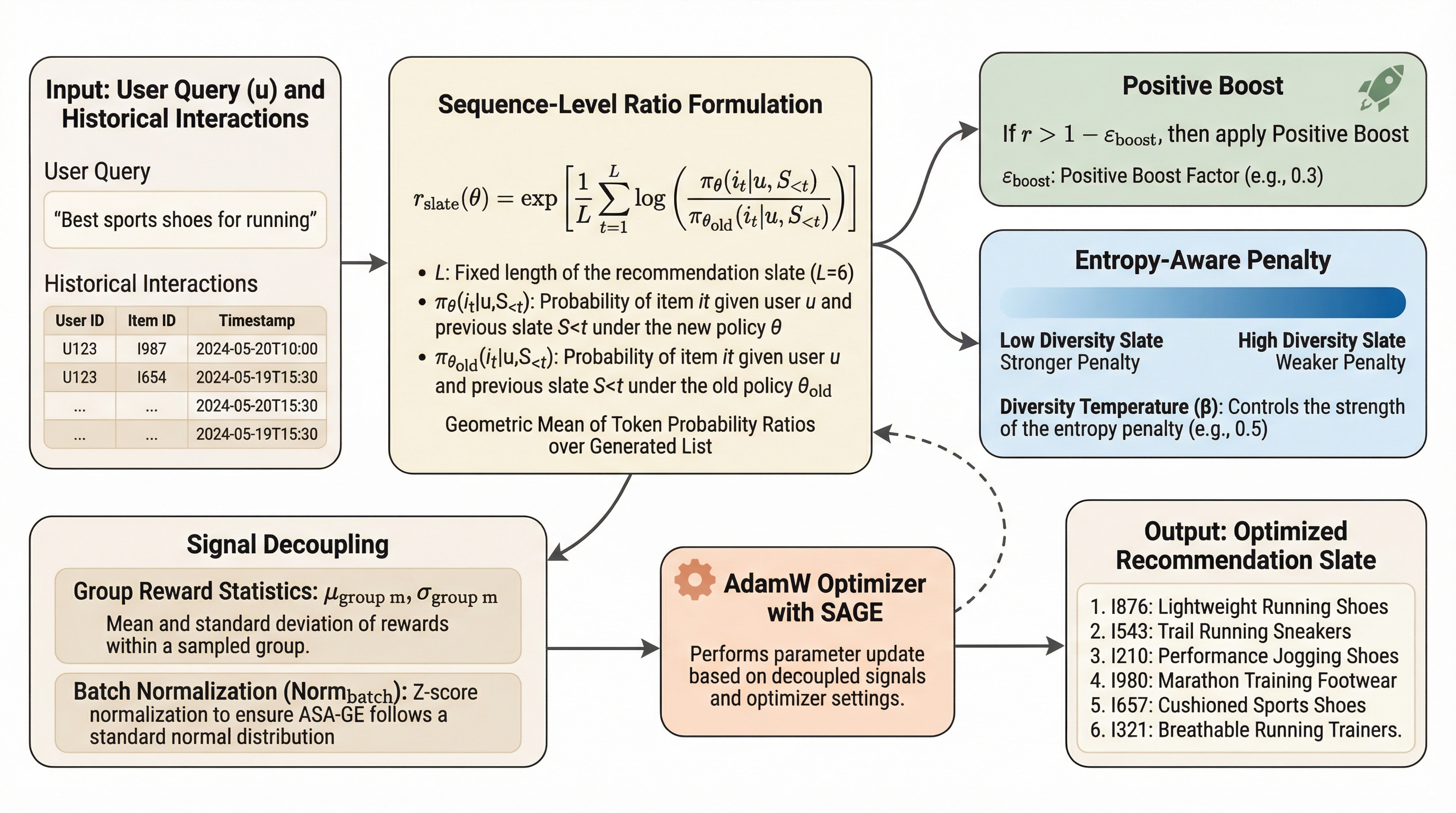
現代の推薦システムにおいて、大規模言語モデル(LLM)の活用は、その高度な意味理解能力と推論能力から大きな注目を集めているが、実用化には大きな障壁が存在する。既存の生成型推薦手法であるOneRecなどは、動画や商品を特定のトークン列であるSemantic IDに変換するための専用語彙集(ボキャブラリ)に依存しており、これが数億規模の項目が日々追加される産業レベルの運用において膨大なコストを強いている。また、異なる項目が同じトークン列にマッピングされる「意味的衝突」が発生しやすく、その衝突率は30%を超えることもあるため、モデルが項目を識別できず重大な情報損失を招いている。さらに、既存の最適化戦略であるGBPO(Gradient Bounded Policy Optimization)には「対称的な保守性」という構造的な問題がある。GBPOは勾配に静的な境界を設けることで学習の安定を図っているが、これが仇となり、露出の少ないコールドスタート項目に対して必要な更新の勢いを抑制してしまう。実際に、GBPOの導入によってコールドスタート項目の視聴回数が44.7%も減少したという報告があり、新規項目の発掘を致命的に妨げている。…
核心:何を提案したのか
本論文では、リスト形式の生成型推薦に特化した統一最適化フレームワークである「SAGE(Sequence-level Adaptive Gradient Evolution)」を提案している。SAGEの最大の特徴は、専用のトークン化語彙を必要とせず、テキストベースでLLMを推薦タスクに直接適応させる点にある。これにより、既存のLLMが持つ意味理解能力を最大限に活用しつつ、メンテナンスコストを大幅に削減することが可能になった。SAGEは主に2つの革新的な技術を導入している。第一に「シーケンスレベルの信号デカップリング」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related