SAGE:生成的推薦のためのシーケンスレベルの適応的勾配進化
既存の生成型推薦システムであるOneRecなどは、専用の語彙構築に依存しており、これが高い維持コストや拡張性の欠如、さらには30%を超えるセマンティック衝突を引き起こしていた。また、従来の最適化戦略であるGBPOは静的な勾配境界を持つ「対称的な保守性」という問題を抱えており、コールドスタート項目の露出を44.
TL;DR(結論)
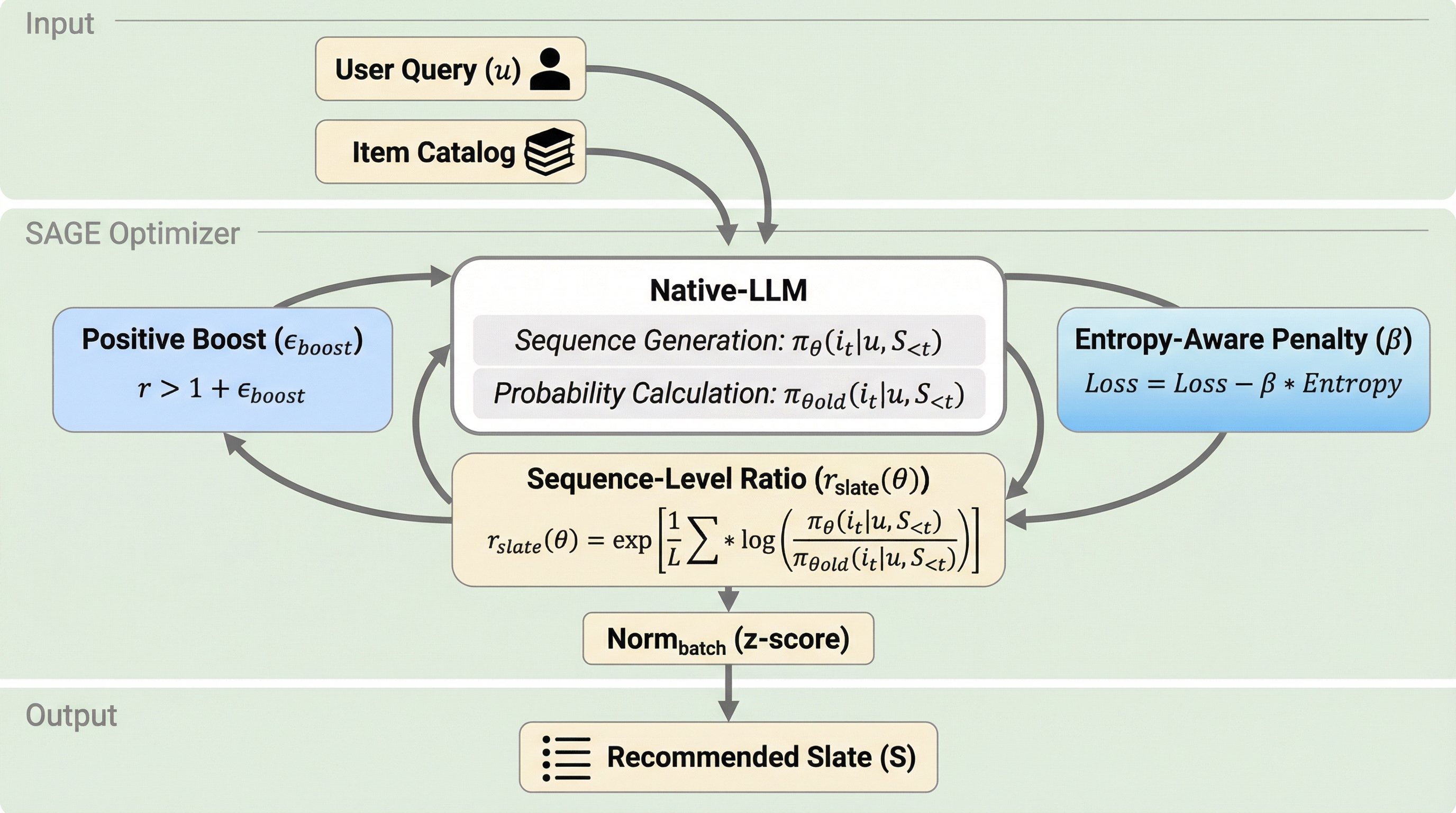
既存の生成型推薦システムであるOneRecなどは、専用の語彙構築に依存しており、これが高い維持コストや拡張性の欠如、さらには30%を超えるセマンティック衝突を引き起こしていた。また、従来の最適化戦略であるGBPOは静的な勾配境界を持つ「対称的な保守性」という問題を抱えており、コールドスタート項目の露出を44.7%減少させ、推薦の多様性を損なう要因となっていた。本研究で提案されたSAGEは、オープンソースのLLMアーキテクチャを直接再利用しつつ、シーケンスレベルの信号デカップリングと非対称な動的勾配制御を導入することで、数値的安定性を維持しながら新規項目の活性化と多様性の確保を両立させている。
なぜこの問題か
デジタル時代において、推薦システムは膨大な情報の中からユーザーが求めるものを探し出すための不可欠なツールとなっている。しかし、従来の協調フィルタリングや行列分解といった手法は、歴史的な相互作用データに依存しすぎており、外部の知識を活用できないという欠点がある。これにより、ユーザーが特定の情報にのみ囲まれる「フィルターバブル」現象が引き起こされることが課題となっていた。また、産業界の展開においては、モデルの最適化を担当するチームと戦略の調整を担当するチームが分断されていることが多く、ビジネス要件の変化に迅速に対応することが困難であった。 近年の大規模言語モデル(LLM)の進歩は、推薦システムに革新的な機会をもたらした。LLMは優れたセマンティック理解と知識推論能力を持ち、限られたデータで新しいタスクを学習できる。しかし、OneRecのような既存の生成型推薦システムでは、ビデオなどの項目をセマンティックIDに変換するための専用の語彙を構築する必要があった。この設計にはいくつかの深刻な問題がある。第一に、複数の異なるビデオが同じトークンシーケンスにマッピングされる「セマンティック衝突」が発生し、その割合は30%を超えることもある。…
核心:何を提案したのか
本研究では、リスト形式の生成型推薦に特化した統一最適化フレームワークである「SAGE(Sequence-level Adaptive Gradient Evolution)」を提案した。SAGEの最大の特徴は、専用の語彙を構築することなく、オープンソースのLLMアーキテクチャをそのまま効率的に再利用できる点にある。これにより、従来のIDベースの推薦システムが抱えていた拡張性の問題や維持コストの問題を解消している。 SAGEには、主に2つの重要な技術革新が含まれている。第一に「シーケンスレベルの信号デカップリング」である。これは、幾何平均重要度比とデカップリングされた多目的アドバンテージ推論を組み合わせることで、トークンレベルの分散を排除し、クリック数や視聴時間といった複数の目的をバランスよく最適化する際に発生する「報酬崩壊」問題を解決するものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related