ConceptMoE:暗黙的な計算割り当てのための適応的なトークンからコンセプトへの圧縮
大規模言語モデルが全てのトークンに一律の計算資源を割り当てる非効率性を解消するため、意味的に類似した連続トークンを「コンセプト」として動的に統合し、計算を最適配分するConceptMoEを提案した。
TL;DR(結論)
大規模言語モデルが全てのトークンに一律の計算資源を割り当てる非効率性を解消するため、意味的に類似した連続トークンを「コンセプト」として動的に統合し、計算を最適配分するConceptMoEを提案した。 学習可能なチャンクモジュールがトークン間の類似度に基づき境界を特定し、圧縮によって浮いた計算資源をMoEの活性化パラメータ等に再配分することで、総パラメータ数と計算量を維持したまま言語・視覚言語タスクの性能を向上させている。 この手法は、長文理解で+2.3ポイント、継続学習で+5.5ポイントの改善を達成し、推論時においてもKVキャッシュの削減や、長いシーケンスにおける最大175%のプレフィル速度向上および117%のデコード速度向上を実現している。
なぜこの問題か
現在の大規模言語モデル(LLM)は、入力された全てのトークンに対して一律の計算量を割り当てるトークンレベルの処理を行っている。しかし、シーケンス内の全てのトークンが等しい意味的重みを持っているわけではない。文脈から容易に予測可能なトークンが存在する一方で、深い推論を必要とする極めて重要な概念を表すトークンも存在する。このような一律のアプローチは、日常的な予測に対して過剰な計算資源を浪費する一方で、意味的に密度の高い内容に対して十分な資源を割けない可能性がある。この課題に対し、固定されたトークンレベルの処理を超えて、適応的なコンセプトレベルの計算へと移行できるかという問いが生まれる。 意味的内容を豊かにしつつトークン数を削減する伝統的な手法として、語彙サイズの拡大が挙げられる。先行研究では、語彙を増やすことでテキストをより情報密度の高いトークンに圧縮し、モデルの性能を向上させることが示されている。しかし、語彙を100倍に拡大しても圧縮率は1.3倍程度に留まり、訓練や推論における計算コストの増大を考えると、さらなるスケーリングは現実的ではない。別の手法として、モデル内部で動的にトークンを統合する試みもある。…
核心:何を提案したのか
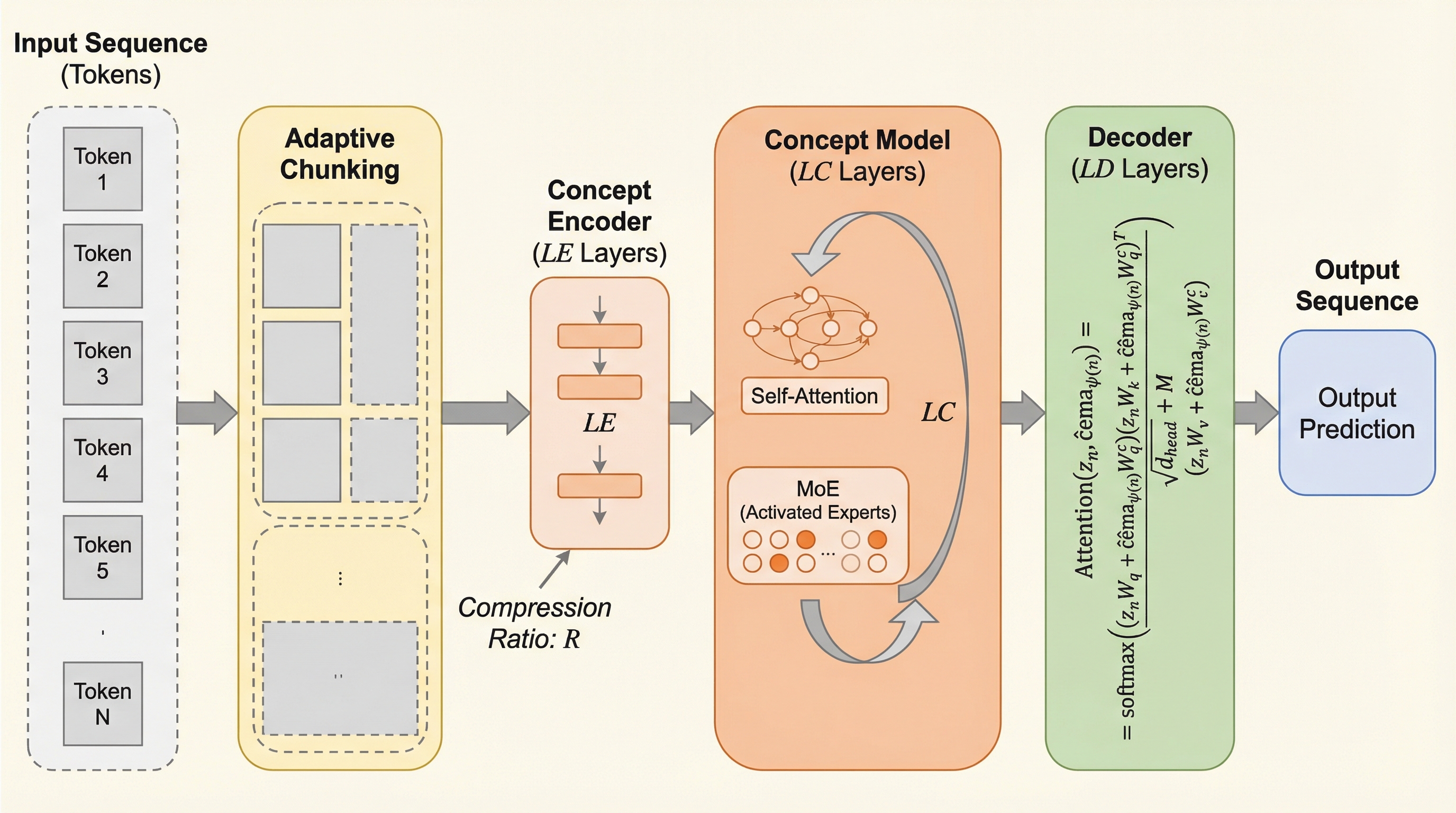
本研究が提案する「ConceptMoE」は、学習可能な適応的チャンキングを通じて、LLMの処理をトークンレベルからコンセプトレベルへと進化させるアーキテクチャである。その核心となる洞察は、意味的類似性が高い連続するトークンを統一されたコンセプト表現に統合し、意味的に異なるトークンはきめ細かな粒度を維持するというものである。これにより、予測可能なトークンシーケンスは効率的に統合処理され、複雑なトークンは詳細な計算を維持するという、暗黙的なトークンレベルの計算割り当てが自然に行われる。 ConceptMoEの重要な特徴は、混合専門家(MoE)アーキテクチャを活用することで、厳密に制御された評価を可能にした点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related