多重表現生成を通じた統一マルチモーダルモデルにおける生成による理解の強化
統一マルチモーダルモデル(UMM)において、画像生成タスクを補助的に活用することで視覚的理解能力を飛躍的に向上させる新しい学習手法「UniMRG」が提案されました。 従来のピクセル再構成に加え、幾何学的な奥行き(デプス)や構造的なセグメンテーションといった複数の内部表現を生成させることで、モデルは空間関係や物体の境界をより深く学習します。 実験では、微細な知覚能力の向上やハルシネーションの抑制、空間認識の強化が確認され、理解タスクの精度向上と同時に画像生成の質も高まるという相乗効果が実証されました。
TL;DR(結論)
統一マルチモーダルモデル(UMM)において、画像生成タスクを補助的に活用することで視覚的理解能力を飛躍的に向上させる新しい学習手法「UniMRG」が提案されました。 従来のピクセル再構成に加え、幾何学的な奥行き(デプス)や構造的なセグメンテーションといった複数の内部表現を生成させることで、モデルは空間関係や物体の境界をより深く学習します。 実験では、微細な知覚能力の向上やハルシネーションの抑制、空間認識の強化が確認され、理解タスクの精度向上と同時に画像生成の質も高まるという相乗効果が実証されました。
なぜこの問題か
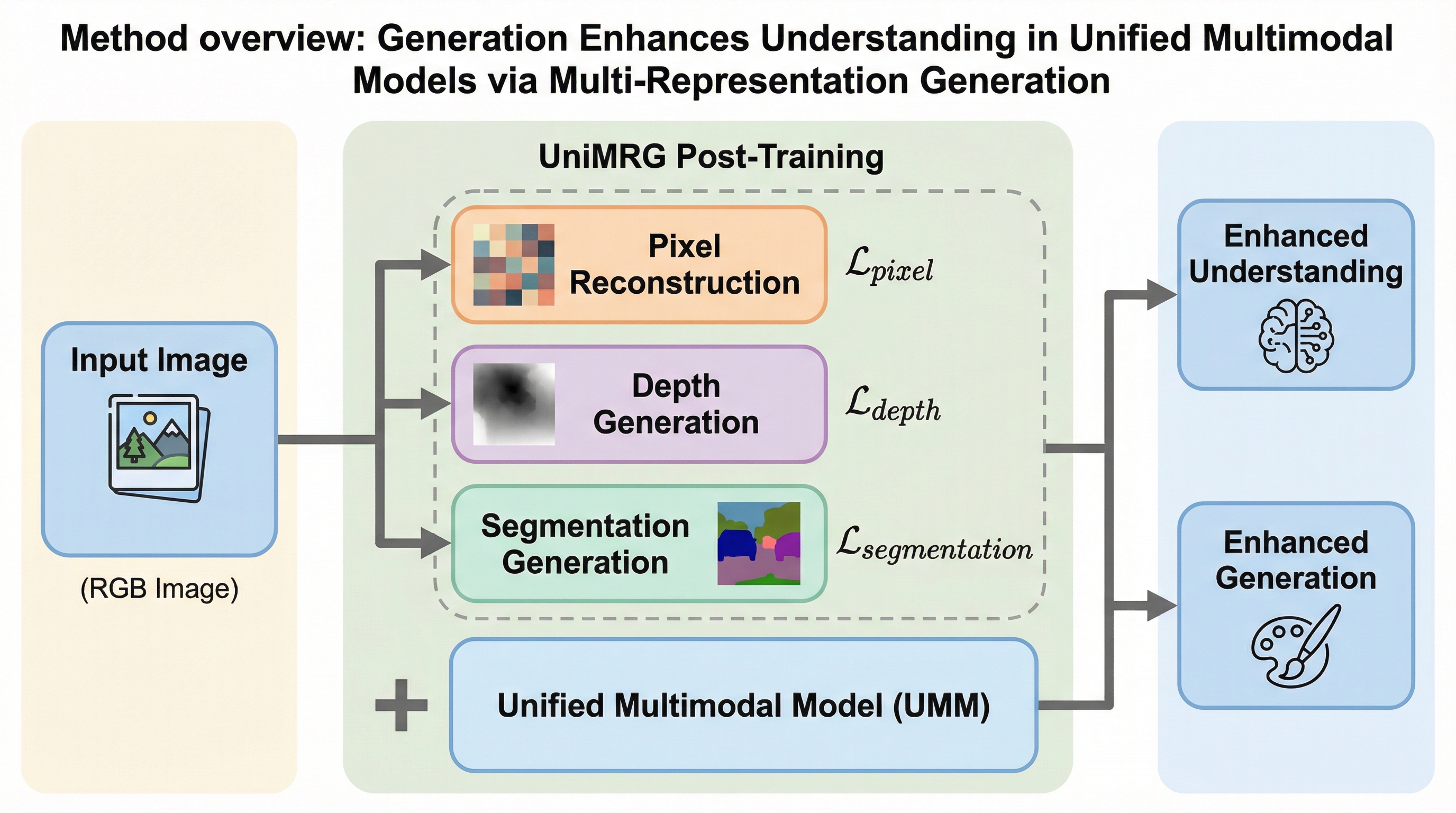
統一マルチモーダルモデル(UMM)は、単一のニューラルネットワークアーキテクチャ内で、視覚的な情報の理解(質問応答やキャプション生成)と、視覚的な情報の生成(テキストからの画像生成や編集)の両方を統合することを目指した、マルチモーダルAI分野における非常に重要な進展です。これらのモデルは、従来の単一タスクに特化したモデルと比較して、高い柔軟性と効率性を備えています。理想的なUMMの姿は、理解能力と生成能力が互いに補完し合い、一方が向上すればもう一方も強化されるという「相互強化のサイクル」を構築することにあります。しかし、これまでの研究の多くは、モデルが持つ高い理解能力を利用して生成能力を向上させるという方向に偏っており、その逆方向である「生成能力を利用して理解能力を向上させる」というアプローチは、これまでほとんど未開拓の状態でした。 物理学者のリチャード・ファインマンが遺した「自分で作り出せないものは、理解できていない」という言葉は、AIの学習においても重要な示唆を与えます。視覚的な情報を正確に生成できる能力は、その対象の構造や性質を深く理解していることの証左となり得ます。…
核心:何を提案したのか
本研究では、補助的な生成タスクを学習プロセスに組み込むことで、統一マルチモーダルモデル(UMM)の理解能力を飛躍的に向上させる、シンプルかつ効果的な事後学習(ポストトレーニング)手法である「UniMRG(Unified Multi-Representation Generation)」を提案しました。この手法の最大の特徴は、特定のモデルアーキテクチャに依存しない「アーキテクチャ・アグノスティック」な設計である点にあります。UniMRGは、標準的な視覚理解の学習目標に加えて、入力画像に関する複数の「本質的な表現(Intrinsic Representations)」を生成するようにモデルを訓練します。 具体的に対象とする表現は、ピクセル(再構成)、デプス(幾何学)、セグメンテーション(構造)の3種類です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related