ConceptMoE:適応的なトークン圧縮による暗黙的な計算資源の割り当て
ConceptMoEは、意味的に類似した連続するトークンを動的に結合して「概念(コンセプト)」表現へと圧縮し、大規模言語モデルにおける計算資源の割り当てをトークン単位から概念単位へと進化させる新しいアーキテクチャである。
TL;DR(結論)
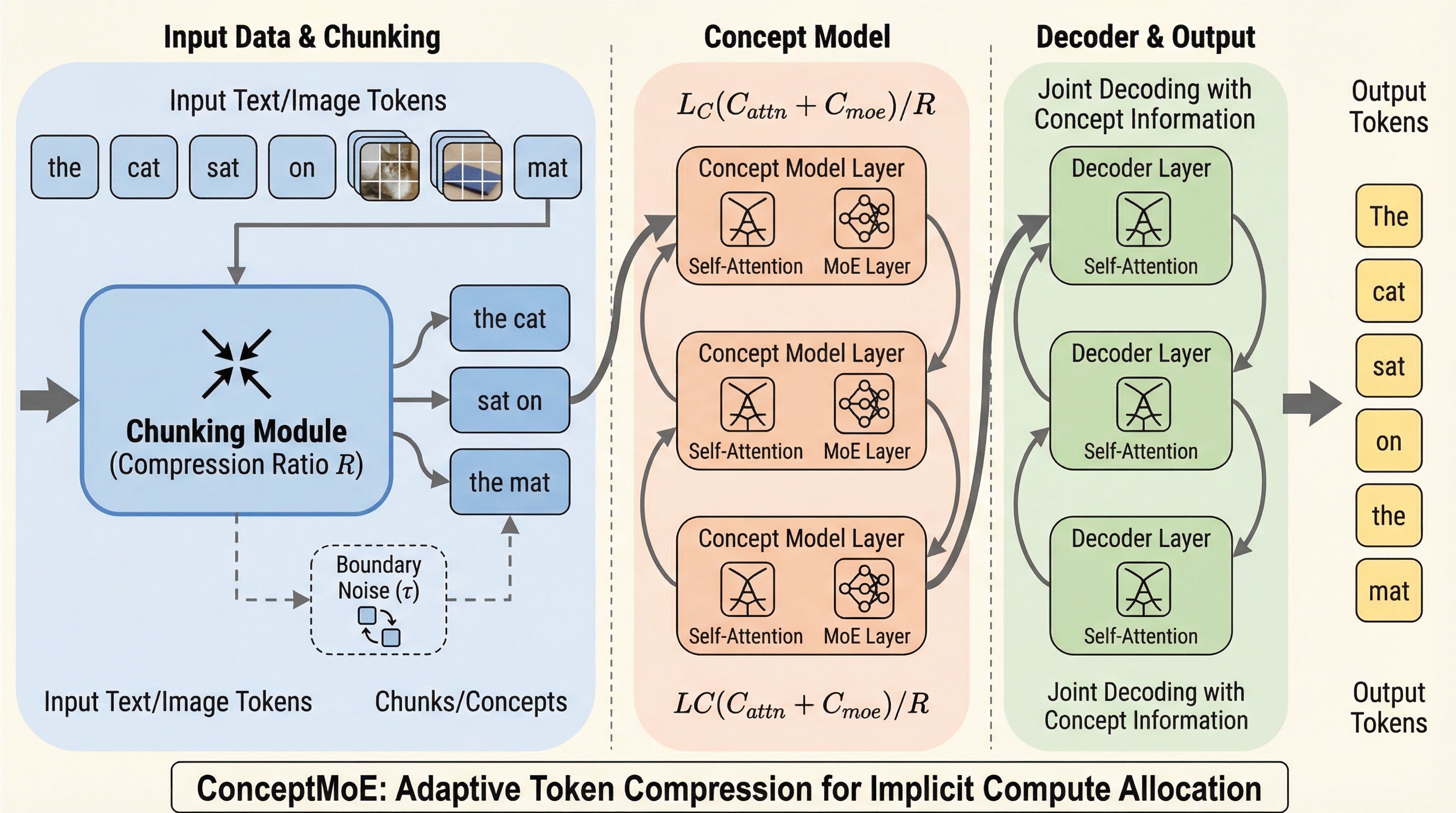
ConceptMoEは、意味的に類似した連続するトークンを動的に結合して「概念(コンセプト)」表現へと圧縮し、大規模言語モデルにおける計算資源の割り当てをトークン単位から概念単位へと進化させる新しいアーキテクチャである。 学習可能なチャンクモジュールがトークン間の類似度に基づき最適な境界を特定し、予測が容易な部分は効率的に圧縮し、複雑な推論を要する部分に計算を集中させることで、標準的なMoEと比較して言語理解や長文脈処理の性能を大幅に向上させた。 計算量をベースラインと一致させた条件下でも、アテンション計算量を最大で圧縮率の2乗分、KVキャッシュを圧縮率分削減することに成功し、長文脈の推論において最大175%のプリフィル速度向上と117%のデコーディング速度向上を達成している。
なぜこの問題か
現在の大規模言語モデル(LLM)は、入力されるすべてのトークンに対して一律の計算資源を割り当てて処理を行っている。しかし、実際にはすべてのトークンが等しい意味的重みを持っているわけではない。文脈から容易に予測可能なトークンが存在する一方で、深い推論や理解を必要とする重要な概念を象徴するトークンも存在しており、画一的な処理は計算資源の浪費を招いている。意味的な密度が低いルーチン的な予測に多大な計算を費やす一方で、意味が密集したコンテンツに対して十分な資源が割かれていない可能性がある。この問題を解決するために、固定されたトークン単位の処理から、適応的な概念単位の計算へと移行することが求められている。 従来、トークンあたりの情報密度を高める手法としては語彙サイズの拡大が検討されてきた。語彙を増やすことでテキストをより少ないトークン数に圧縮できるが、その効果には限界がある。先行研究によれば、語彙を100倍に増やしても圧縮率は1.3倍程度にとどまり、学習や推論における計算コストの増大が実用上の障壁となっている。…
核心:何を提案したのか
本研究では、LLMの処理をトークンレベルから概念レベルへと引き上げる「ConceptMoE」を提案している。この手法の核心は、学習可能な適応的チャンク化を通じて、意味的に類似した連続するトークンを統一された「概念(コンセプト)」表現へと統合することにある。意味的な類似性が高いトークン群は一つの概念としてまとめられ、一方で意味的に独立したトークンは詳細な粒度を維持する。これにより、予測可能なトークン列は効率的に処理され、複雑なトークンには詳細な計算が維持されるという、暗黙的な計算資源の割り当てが実現される。 ConceptMoEの最大の特徴は、混合専門家(MoE)アーキテクチャを活用することで、公平かつ制御された評価を可能にしている点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related