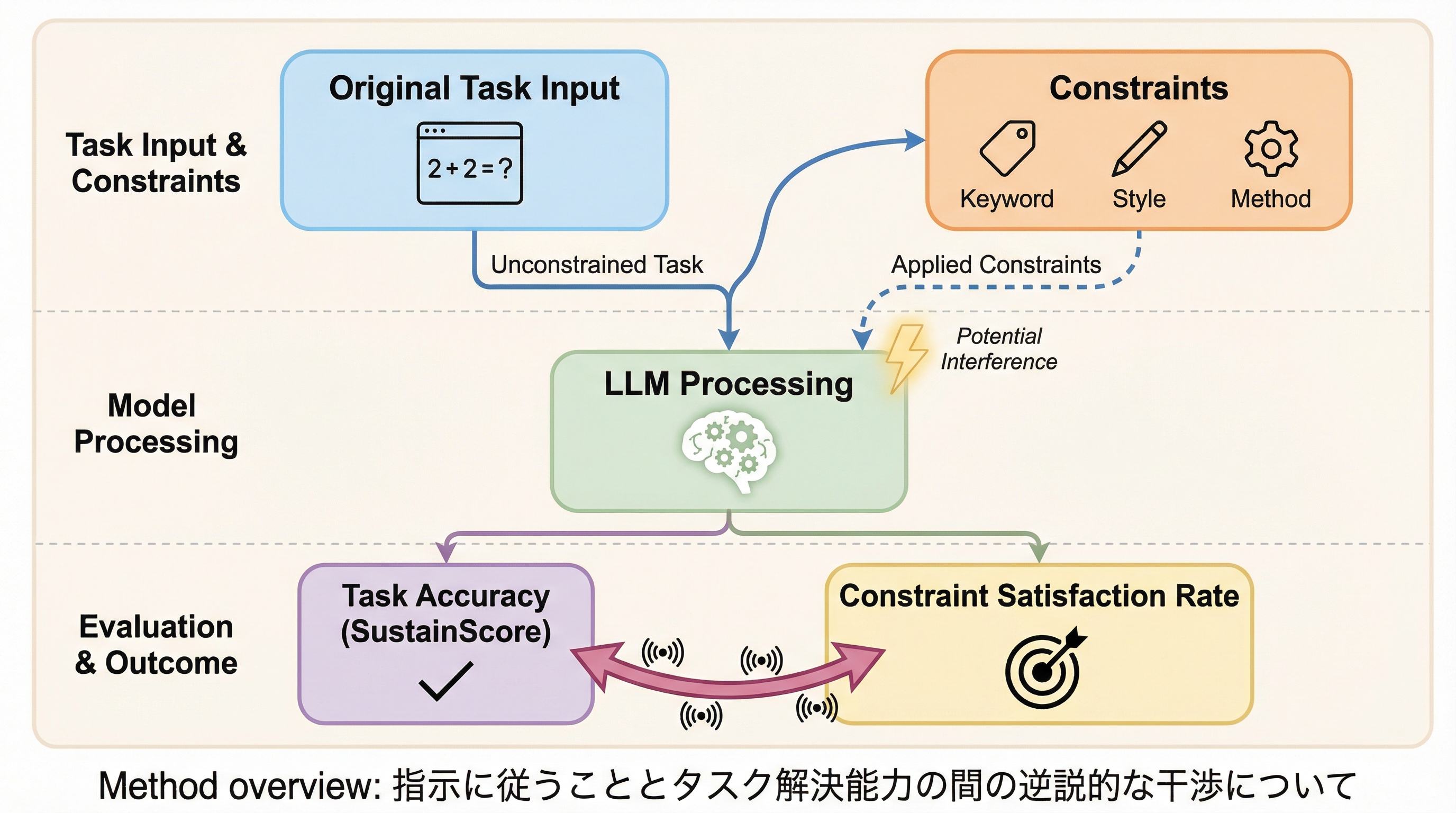
指示に従うこととタスク解決能力の間の逆説的な干渉について
大規模言語モデル(LLM)において、ユーザーの指示や制約を遵守しようとする能力(指示追従)が、モデルが本来持っているはずのタスク解決能力をかえって阻害してしまう「逆説的な干渉」という現象が本研究によって明らかになりました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)において、ユーザーの指示や制約を遵守しようとする能力(指示追従)が、モデルが本来持っているはずのタスク解決能力をかえって阻害してしまう「逆説的な干渉」という現象が本研究によって明らかになりました。
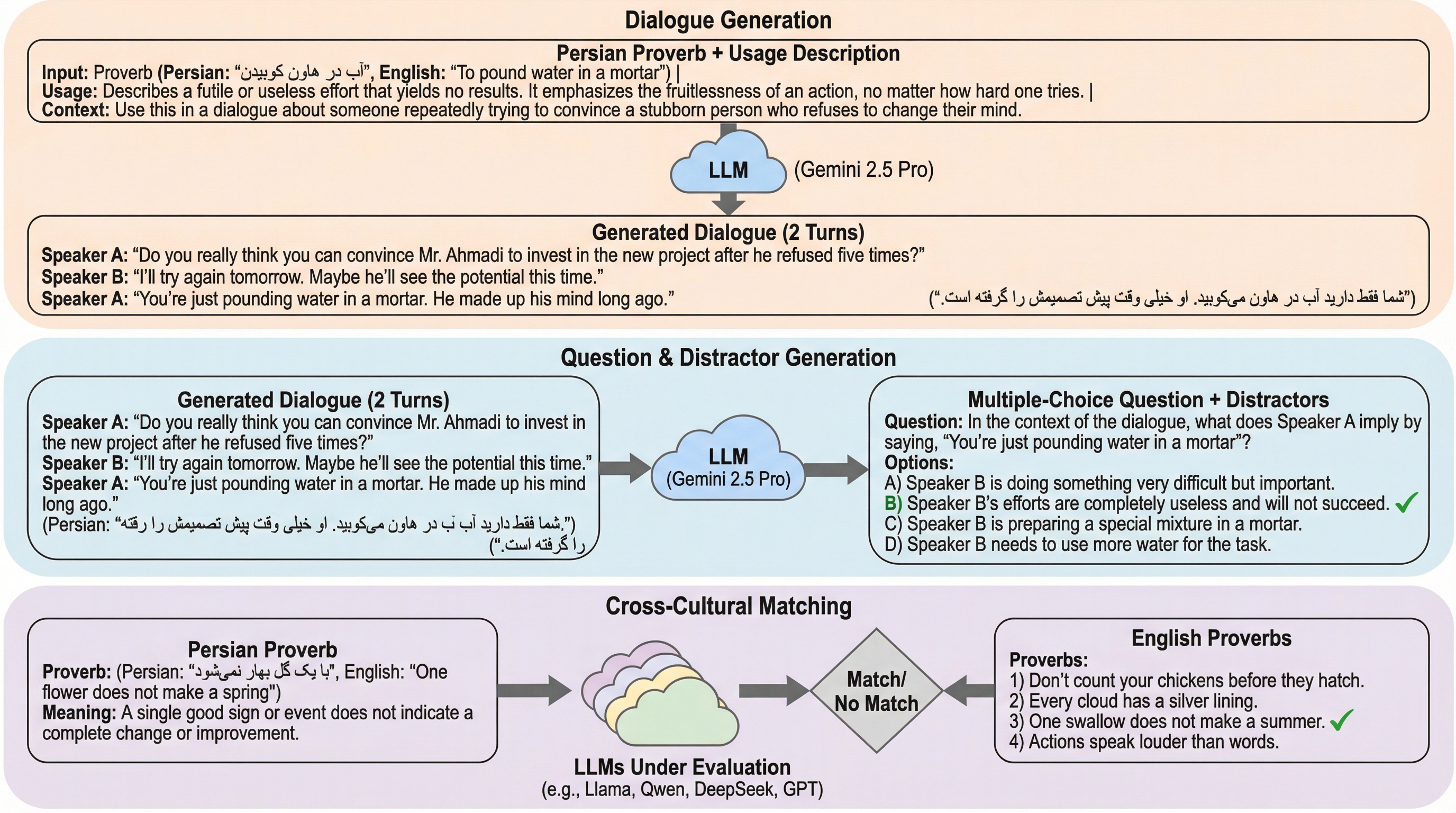
多言語大規模言語モデル(LLM)が日常会話に不可欠となる中、ペルシャ語のような低リソース言語における「ことわざ」の理解力を測定するため、1,000件の文脈理解問題と700件の異文化間対応問題を含む新しいベンチマーク「MasalBench」が開発されました。
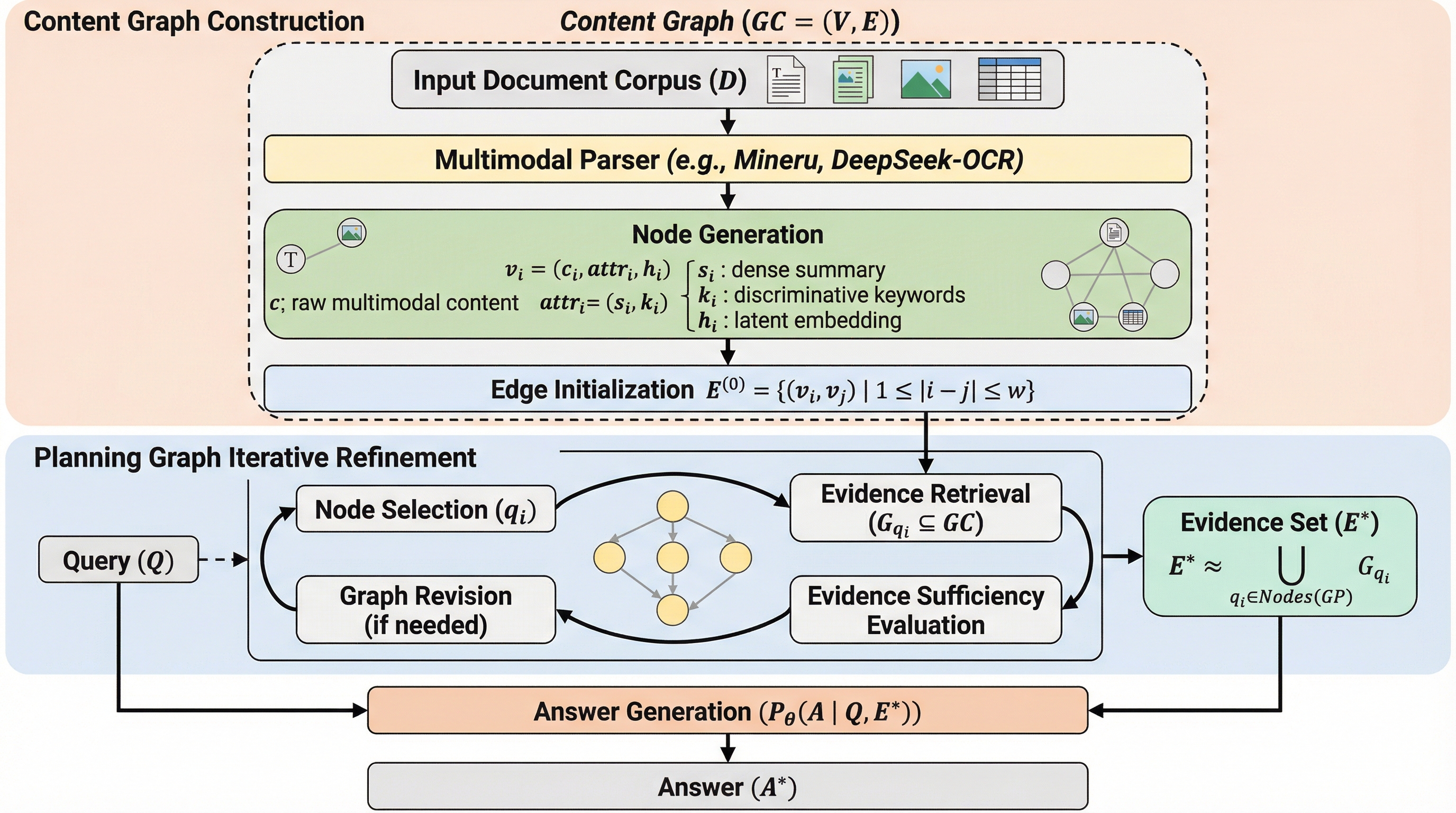
$G^2$-Readerは、テキスト、表、図が複雑に混在する長大なマルチモーダル文書から正確な回答を導き出すために、文書構造を保持する「コンテンツグラフ」と推論を管理する「プランニンググラフ」を組み合わせた革新的な二重グラフシステムである。
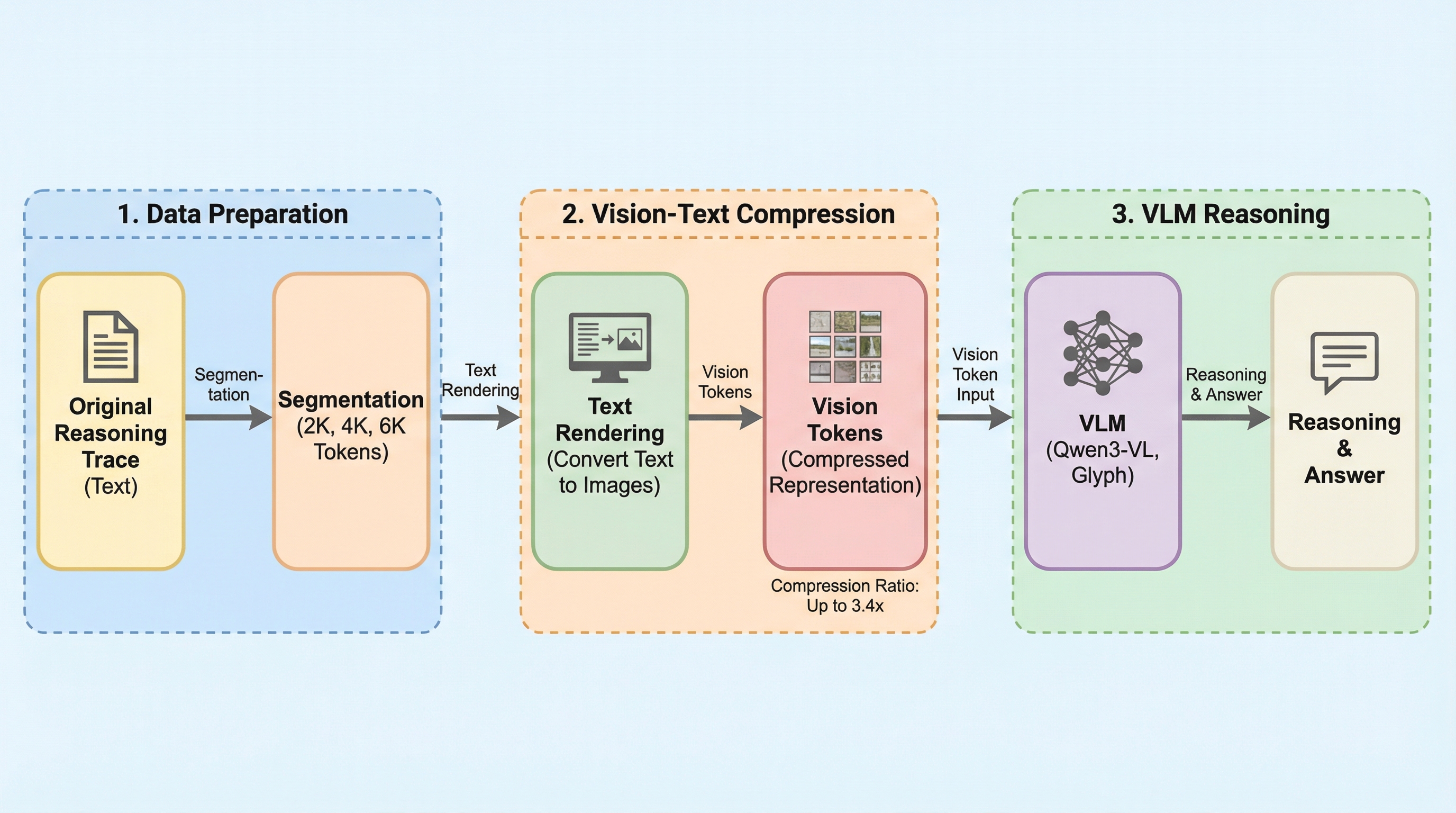
VTC-R1は、大規模言語モデルの長文脈推論における計算コスト増大を解決するため、中間的な推論過程を画像化して圧縮する新しい効率化パラダイムである。従来のテキストベースの処理に代わり、推論ステップを軽量なレンダリングによってコンパクトな画像へと変換し、それを「光学メモリ」として視覚言語モデルに繰り返し入力することで、詳細な情報を保持したままトークン数を大幅に削減する。数学的推論ベンチマークにおいて、標準的な手法を凌駕する精度を達成しつつ、エンドツーエンドの遅延を最大2.7倍高速化し、テキストトークンを約3.4倍の効率で圧縮することに成功した。この手法は追加の学習段階や外部の強力なモデルを必要とせず、モデルフリーで軽量な設計となっており、複雑な推論タスクにおける実用的なスケーラビリティを提供する。
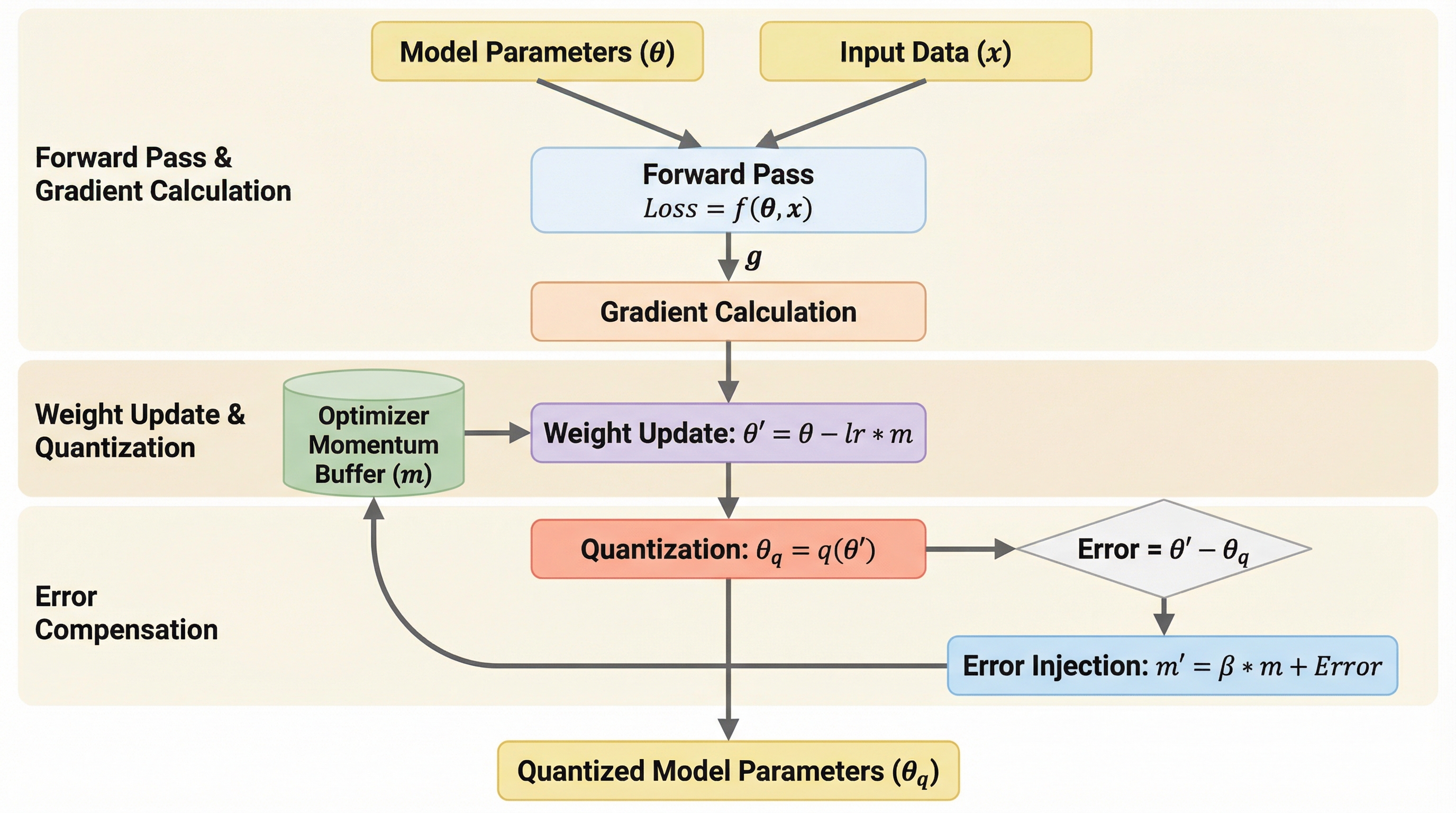
大規模言語モデル(LLM)の学習において、メモリ消費の大きな要因となっていた高精度なマスターウェイトを完全に排除し、量子化されたパラメータのみで学習を可能にする「Error-Compensating Optimizer(ECO)」が提案されました。
OpenAIのo1やDeepSeek-R1に代表される推論型モデルが、情報不足の状況でも強引に推論を進めてしまう「盲目的な自己思考」という課題に対し、本研究は能動的に質問を行うPIRフレームワークを提案しました。
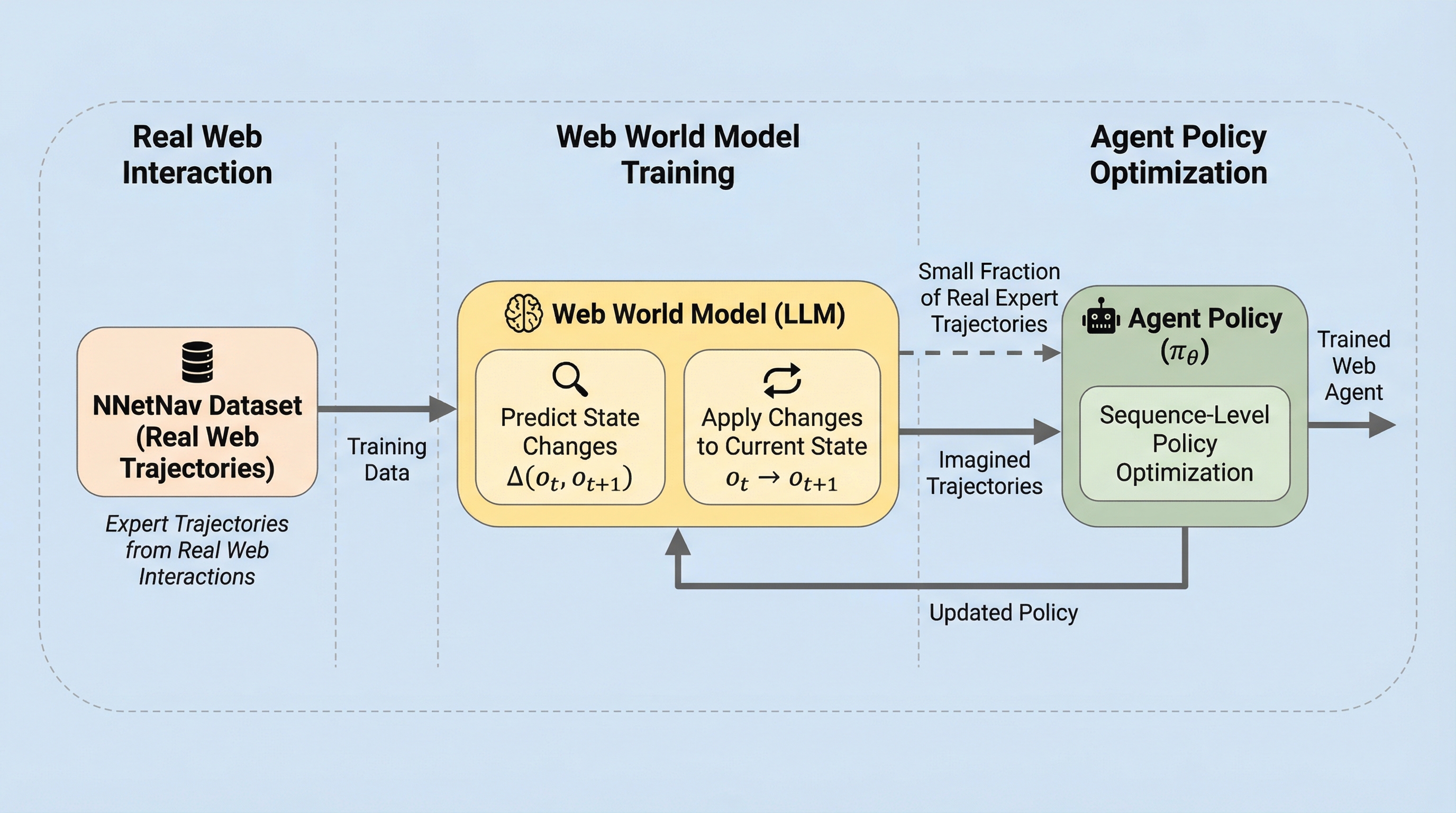
従来のウェブエージェントの強化学習は、実際のインターネット上での試行錯誤を必要としていましたが、これには高額なコストや予期せぬ購入といったリスク、そして動作の非効率性という大きな課題がありました。
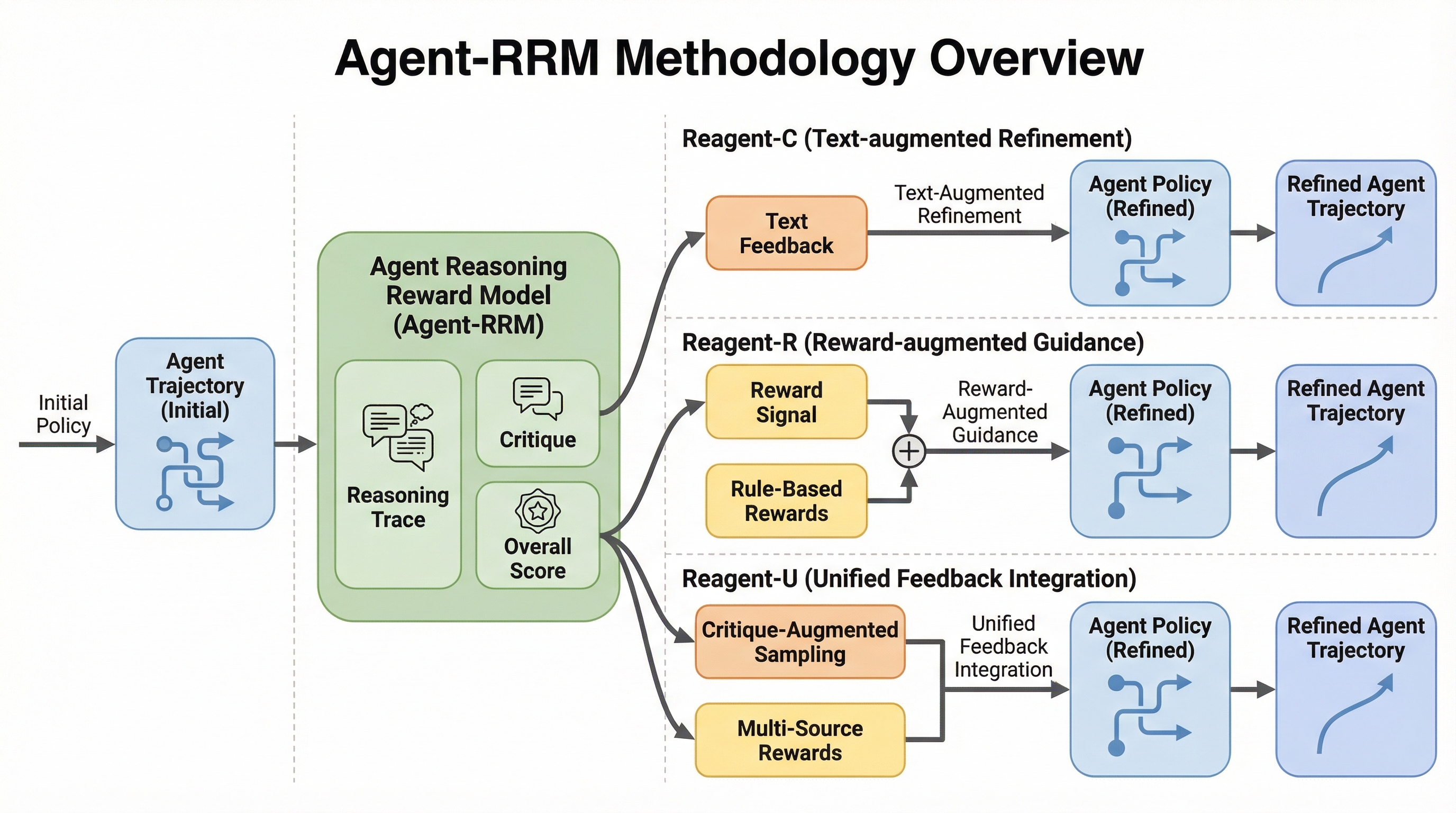
従来のエージェント学習が最終結果の正誤のみに依存する稀薄な報酬に頼っていたのに対し、本研究は推論の過程を詳細に評価する「Agent-RRM」を提案しました。 このモデルは、推論の論理性を分析するトレース、具体的な欠陥を指摘する批判、全体的な品質スコアという3つの構造化されたフィードバックを生成し、エージェントに多角的な学習信号を提供します。 12種類のベンチマークを用いた検証の結果、提案手法の「Reagent-U」はGAIAで43.7%、WebWalkerQAで46.2%という高い性能を達成し、複雑なタスクにおける推論報酬モデルの有効性が証明されました。
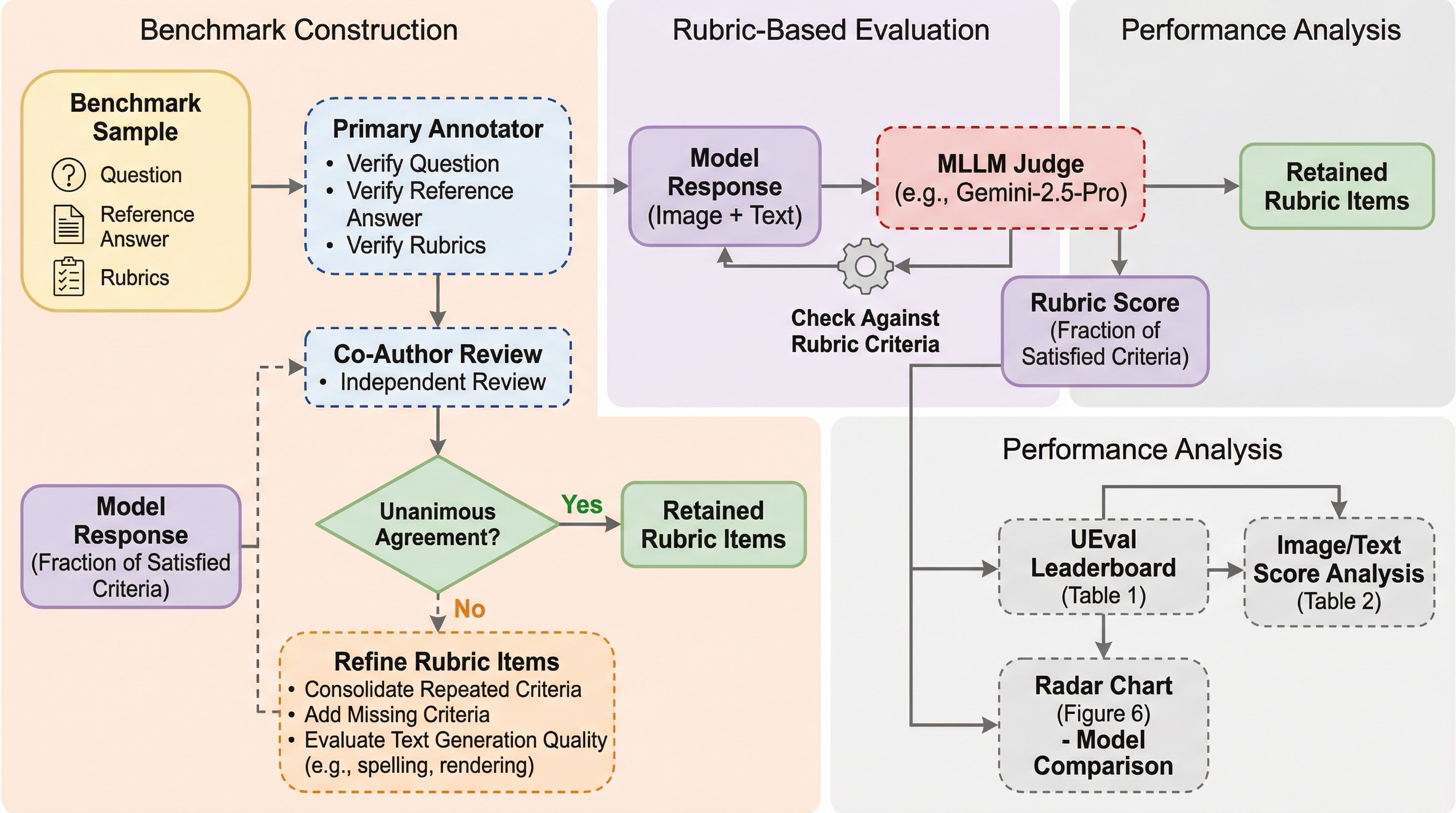
本研究は、テキストの問いかけに対して画像とテキストの両方で回答する「統合マルチモーダル生成」を評価するための新しいベンチマーク「UEval」を提案しました。専門家が厳選した1,000件の質問と、それに対する10,417件の検証済み評価基準(ルーブリック)を用いることで、従来の画像理解や画像生成のみの評価では捉えきれなかった、複雑な推論を伴うマルチモーダルな応答能力を詳細に測定することが可能になります。検証の結果、最新のGPT-5-Thinkingでも100点満点中66.4点に留まり、オープンソースモデルの最高値は49.1点であるなど、現在の統合モデルにとって非常に難易度が高い課題であることが明らかになるとともに、推論プロセスが生成品質の向上に寄与することが示されました。
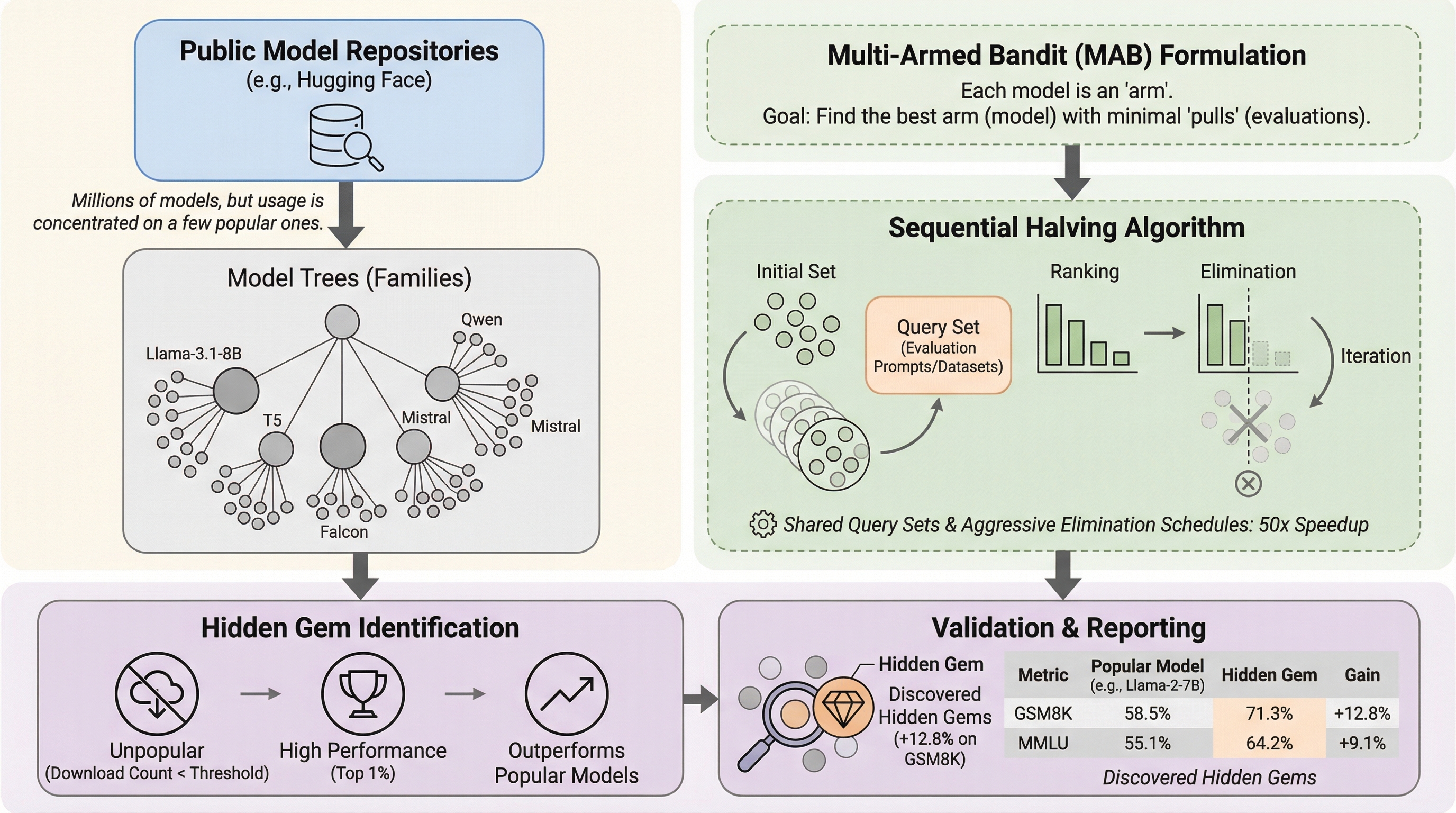
Hugging Face等の公開リポジトリには数百万のモデルがホストされているが、利用実態は極めて一部の公式モデルに集中しており、優れた性能を持ちながらも月間ダウンロード数が極少数の「隠れた名作(Hidden Gems)」が膨大に埋もれている実態を、2,000以上のモデル評価を通じて明らかにした。 Llama-3.