MasalBench:LLMにおけるペルシャ語ことわざの文脈的・異文化的理解のためのベンチマーク
多言語大規模言語モデル(LLM)が日常会話に不可欠となる中、ペルシャ語のような低リソース言語における「ことわざ」の理解力を測定するため、1,000件の文脈理解問題と700件の異文化間対応問題を含む新しいベンチマーク「MasalBench」が開発されました。
TL;DR(結論)
多言語大規模言語モデル(LLM)が日常会話に不可欠となる中、ペルシャ語のような低リソース言語における「ことわざ」の理解力を測定するため、1,000件の文脈理解問題と700件の異文化間対応問題を含む新しいベンチマーク「MasalBench」が開発されました。 検証の結果、最新のLLMは文脈内でのペルシャ語ことわざの特定において0.90以上の高い精度を示しましたが、ペルシャ語のことわざを同等の意味を持つ英語のことわざと結びつける異文化間の類推タスクでは、最高精度が0.793に留まるなど性能が大幅に低下することが判明しました。 この研究は、現在のモデルが言語内の文脈推論には優れているものの、異なる文化圏の概念を抽象化して結びつける能力には限界があることを示しており、低リソース言語における文化的知識と類推推論の評価のための重要な枠組みを提供しています。
なぜこの問題か
近年、多言語大規模言語モデル(LLM)は、製品のアドバイスから一般的な質問への回答、ビジネス業務の支援に至るまで、私たちの日常生活において切り離せない存在となっています。これらのモデルがユーザーと効果的にコミュニケーションを取るためには、単なる翻訳能力だけでなく、会話における言語の規則やニュアンスを習得することが極めて重要です。特に「ことわざ」は、共通の真理を比喩的に伝える伝統的な表現であり、自然な会話において重要な役割を果たしています。英語のような高リソース言語においては、豊富なトレーニングデータと既存のベンチマークの存在により、LLMは比喩的な言語表現を高い精度で理解できることが先行研究で示されています。しかし、ペルシャ語のような低リソース言語においては、ことわざに関するデータが不足しており、モデルの習熟度が十分に検証されていませんでした。 ペルシャ語は歴史的にも現代においてもことわざの使用が非常に豊富な言語であり、イランの話し手は日常生活や専門的な場面でも、意識することなく頻繁にことわざを使用します。…
核心:何を提案したのか
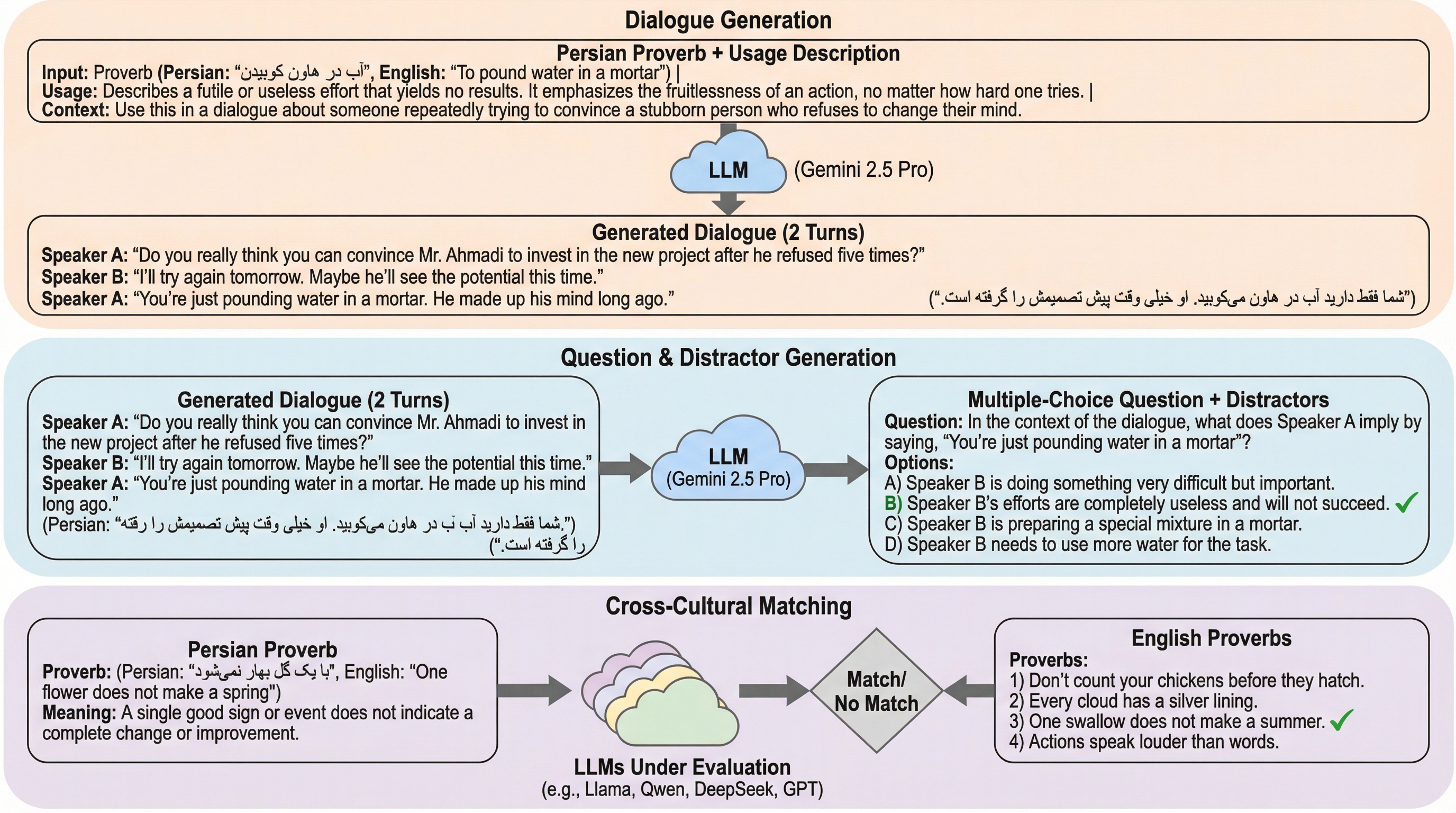
本研究では、LLMによるペルシャ語ことわざの文脈的および異文化的な理解を評価するための包括的なベンチマーク「MasalBench」を提案しました。このベンチマークは、大きく分けて「文脈的理解」と「異文化的理解」の2つのレベルで構成されています。文脈的理解のレベルでは、1,000問の多肢選択式問題が用意されています。これらの問題は対話形式で構成されており、特定の状況下でことわざがどのような意図で使用されたかを問うものです。各問題には、正解に加えて、モデルを惑わすための3つの異なるタイプの誤答(ディストラクター)が慎重に設計されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related