VTC-R1: 長文脈推論を効率化する視覚・テキスト圧縮技術
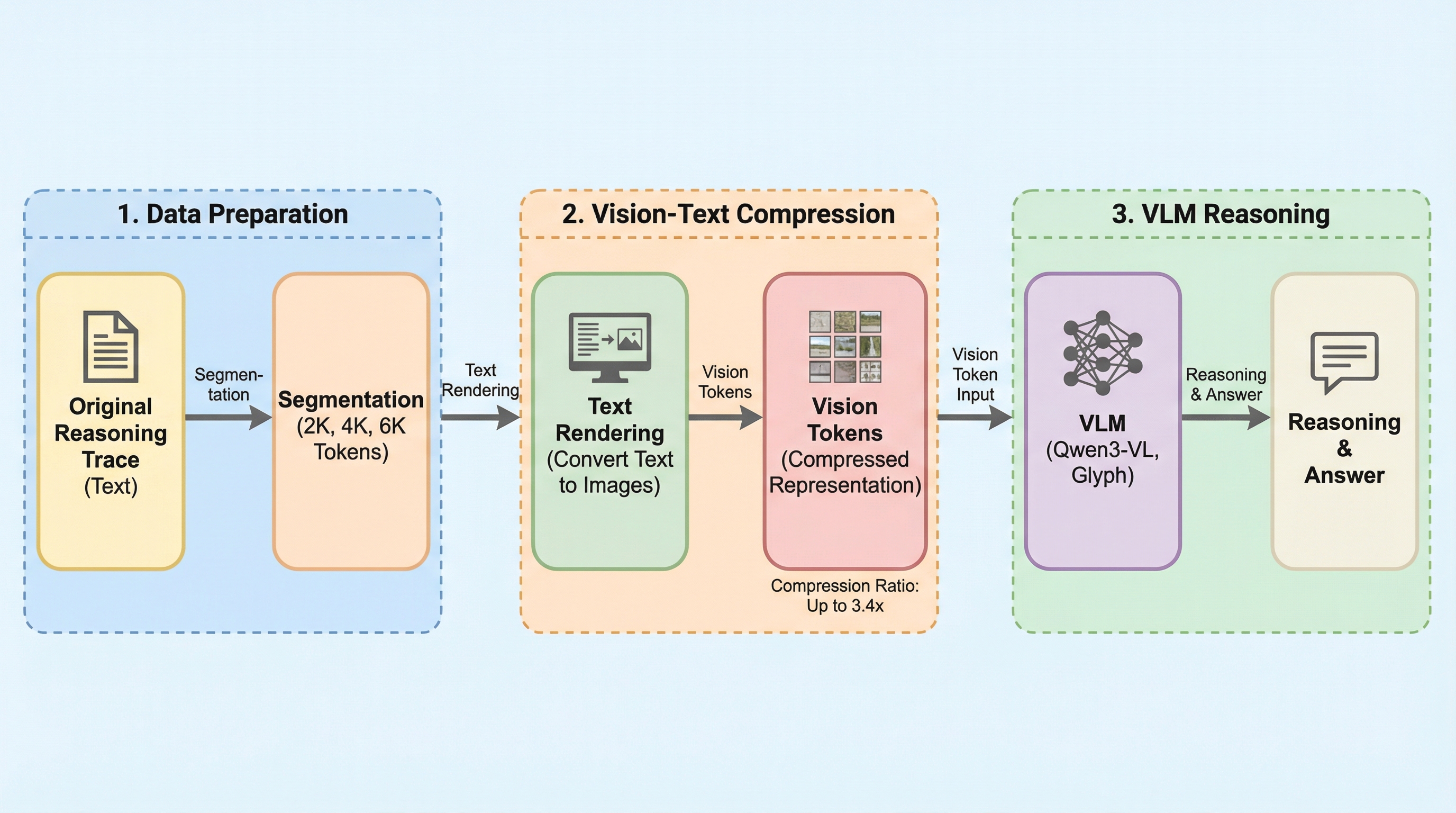
VTC-R1は、大規模言語モデルの長文脈推論における計算コスト増大を解決するため、中間的な推論過程を画像化して圧縮する新しい効率化パラダイムである。従来のテキストベースの処理に代わり、推論ステップを軽量なレンダリングによってコンパクトな画像へと変換し、それを「光学メモリ」として視覚言語モデルに繰り返し入力することで、詳細な情報を保持したままトークン数を大幅に削減する。数学的推論ベンチマークにおいて、標準的な手法を凌駕する精度を達成しつつ、エンドツーエンドの遅延を最大2.7倍高速化し、テキストトークンを約3.4倍の効率で圧縮することに成功した。この手法は追加の学習段階や外部の強力なモデルを必要とせず、モデルフリーで軽量な設計となっており、複雑な推論タスクにおける実用的なスケーラビリティを提供する。
TL;DR(結論)
VTC-R1は、大規模言語モデルの長文脈推論における計算コスト増大を解決するため、中間的な推論過程を画像化して圧縮する新しい効率化パラダイムである。従来のテキストベースの処理に代わり、推論ステップを軽量なレンダリングによってコンパクトな画像へと変換し、それを「光学メモリ」として視覚言語モデルに繰り返し入力することで、詳細な情報を保持したままトークン数を大幅に削減する。数学的推論ベンチマークにおいて、標準的な手法を凌駕する精度を達成しつつ、エンドツーエンドの遅延を最大2.7倍高速化し、テキストトークンを約3.4倍の効率で圧縮することに成功した。この手法は追加の学習段階や外部の強力なモデルを必要とせず、モデルフリーで軽量な設計となっており、複雑な推論タスクにおける実用的なスケーラビリティを提供する。
なぜこの問題か
大規模言語モデル(LLM)における推論能力は、数学の問題解決やコード生成といった複雑なタスクを遂行するための基盤となっている。特にOpenAI o1やDeepSeek-R1に代表される最新のモデルは、強化学習を通じて長文脈の思考連鎖(Chain of Thought)を生成することで、困難な現実世界の課題に対して高い性能を発揮している。しかし、このような長文脈推論には深刻な効率性のボトルネックが存在する。トランスフォーマー・アーキテクチャの計算複雑性はシーケンス長の二乗に比例して増大するため、文脈が長くなるにつれて計算コストとメモリ消費が急激に増加する。この現象は推論速度の低下やトレーニング効率の悪化を招き、大規模な実用展開を困難にする主要な要因となっている。 この問題に対処するため、既存の研究ではいくつかの効率化手法が提案されてきた。一つは、標準的な学習以外に追加のトレーニングやサンプリング段階を必要とする手法である。例えば、異なる推論長に特化したモデルを多段階で学習させる手法や、オフラインの強化学習を用いて複数の推論軌跡をサンプリングする手法が存在するが、これらは展開前のオーバーヘッドを大幅に増加させる欠点がある。…
核心:何を提案したのか
本論文では、視覚・テキスト圧縮を推論プロセスに反復的に統合する新しい効率的推論パラダイム「VTC-R1」を提案する。VTC-R1の核心は、長大なテキストによる推論の軌跡をそのまま処理するのではなく、中間的な推論セグメントをコンパクトな画像へとレンダリングし、それを視覚言語モデル(VLM)に「光学メモリ」として提供する点にある。この手法は、詳細な情報を削減するのではなく、軽量なレンダリングを通じてテキストを視覚的な表現に変換することで、より少ない視覚トークンで豊かな意味情報をエンコードすることを可能にする。 VTC-R1は、追加の学習段階や外部の圧縮用モデルを必要としない軽量かつモデルフリーな設計となっている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related