最適輸送理論に基づくサンプル生成による分布外データの過剰適合抑制
深層学習モデルが未知のデータ(分布外データ)に対して根拠のない高い確信度を持つ「過剰適合」の問題に対し、半離散最適輸送理論の幾何学的構造を利用して、意味的に曖昧な境界領域を特定し制御する新しい学習フレームワークが提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
深層学習モデルが未知のデータ(分布外データ)に対して根拠のない高い確信度を持つ「過剰適合」の問題に対し、半離散最適輸送理論の幾何学的構造を利用して、意味的に曖昧な境界領域を特定し制御する新しい学習フレームワークが提案されました。
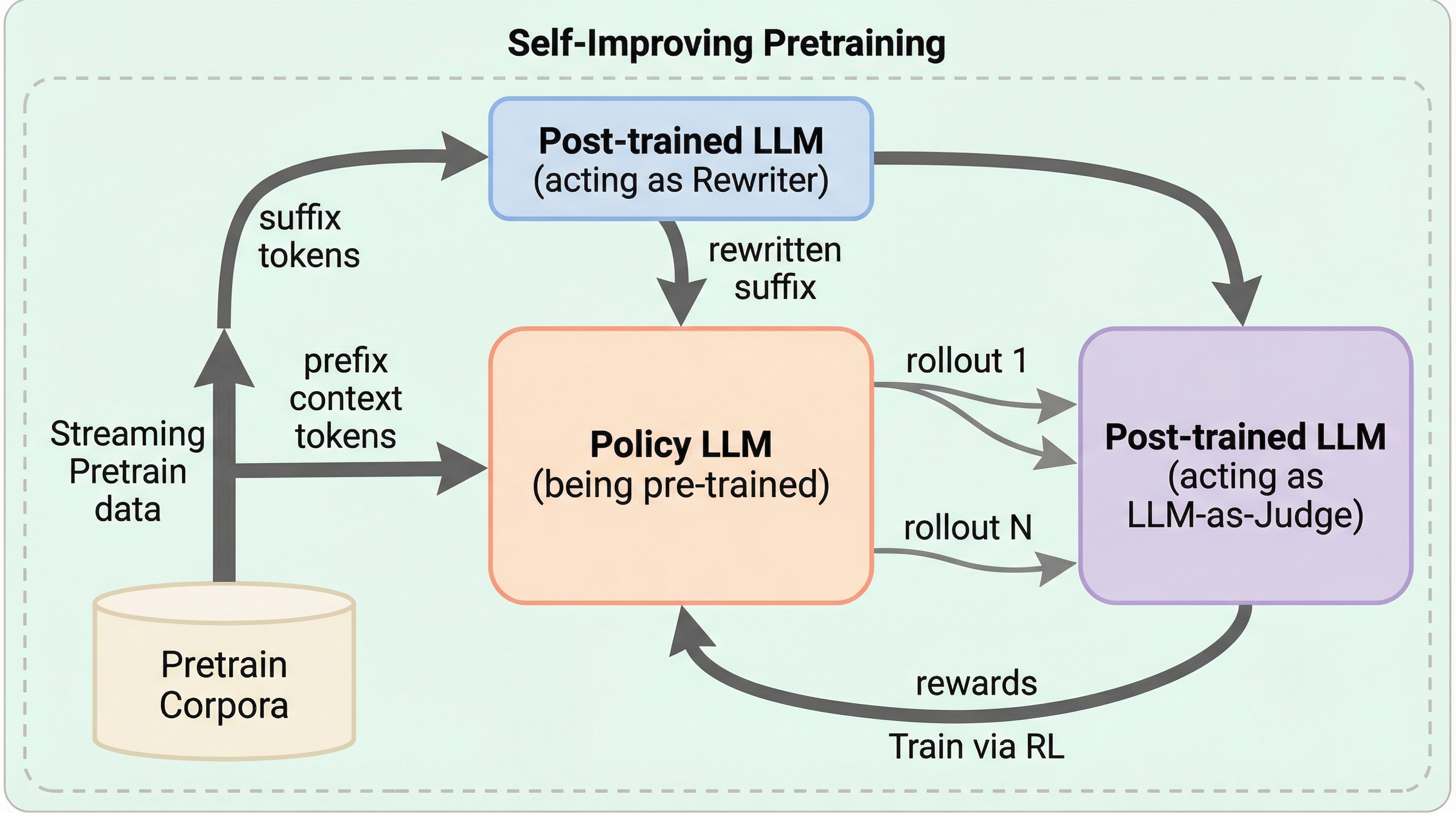
大規模言語モデルの安全性や事実性を根本から高めるため、従来の次単語予測に代わり、事後学習済みの強力なモデルを「判定役」および「書き換え役」としてループに組み込み、強化学習を用いてシーケンス単位で最適化する「自己改善型事前学習」を提案している。
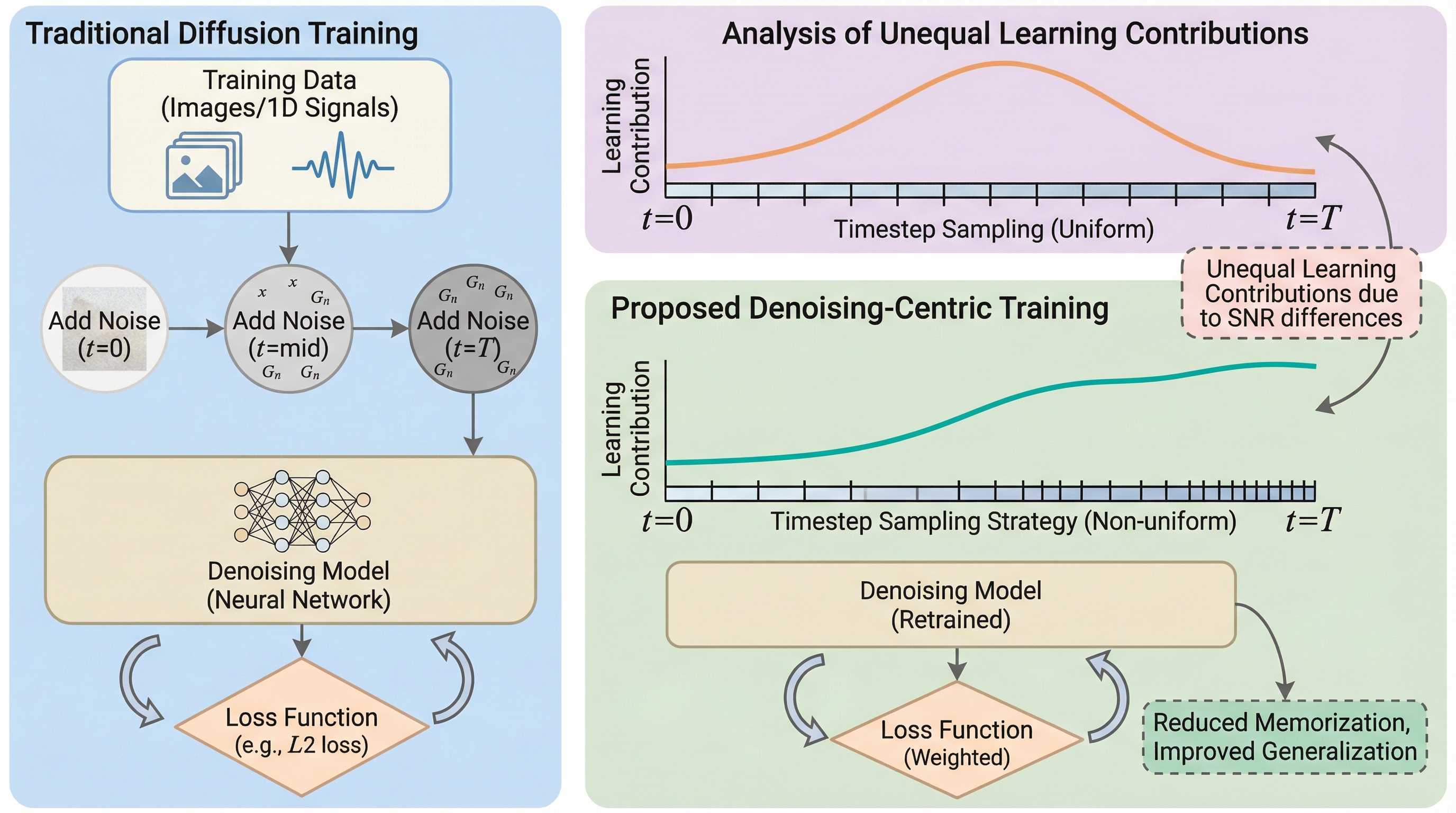
拡散モデルの学習において、タイムステップを一様にサンプリングすると信号対雑音比(SNR)の変動により学習の寄与が不均衡になり、特定の訓練データを過度に再現する「記憶」が生じる問題を、デノイジングの動態を重視する視点から解明した。
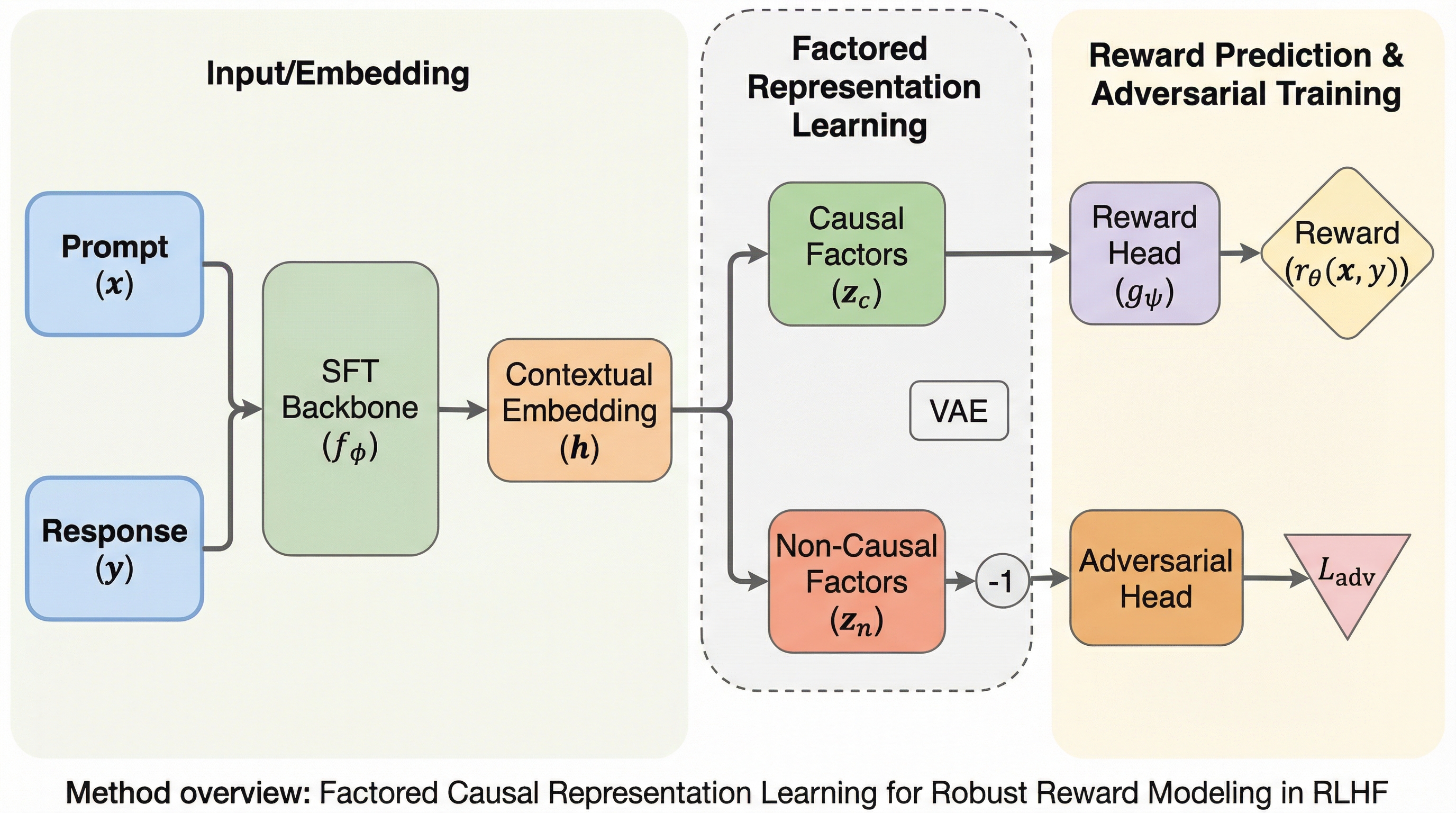
人間からのフィードバックを用いた強化学習(RLHF)において、報酬モデルが回答の長さや追従的な表現といった「偽の相関」を学習し、不当に高い報酬を得ようとする報酬ハッキングが生じる課題に対し、因果的な視点から表現を分解する新手法「CausalRM」を提案した。
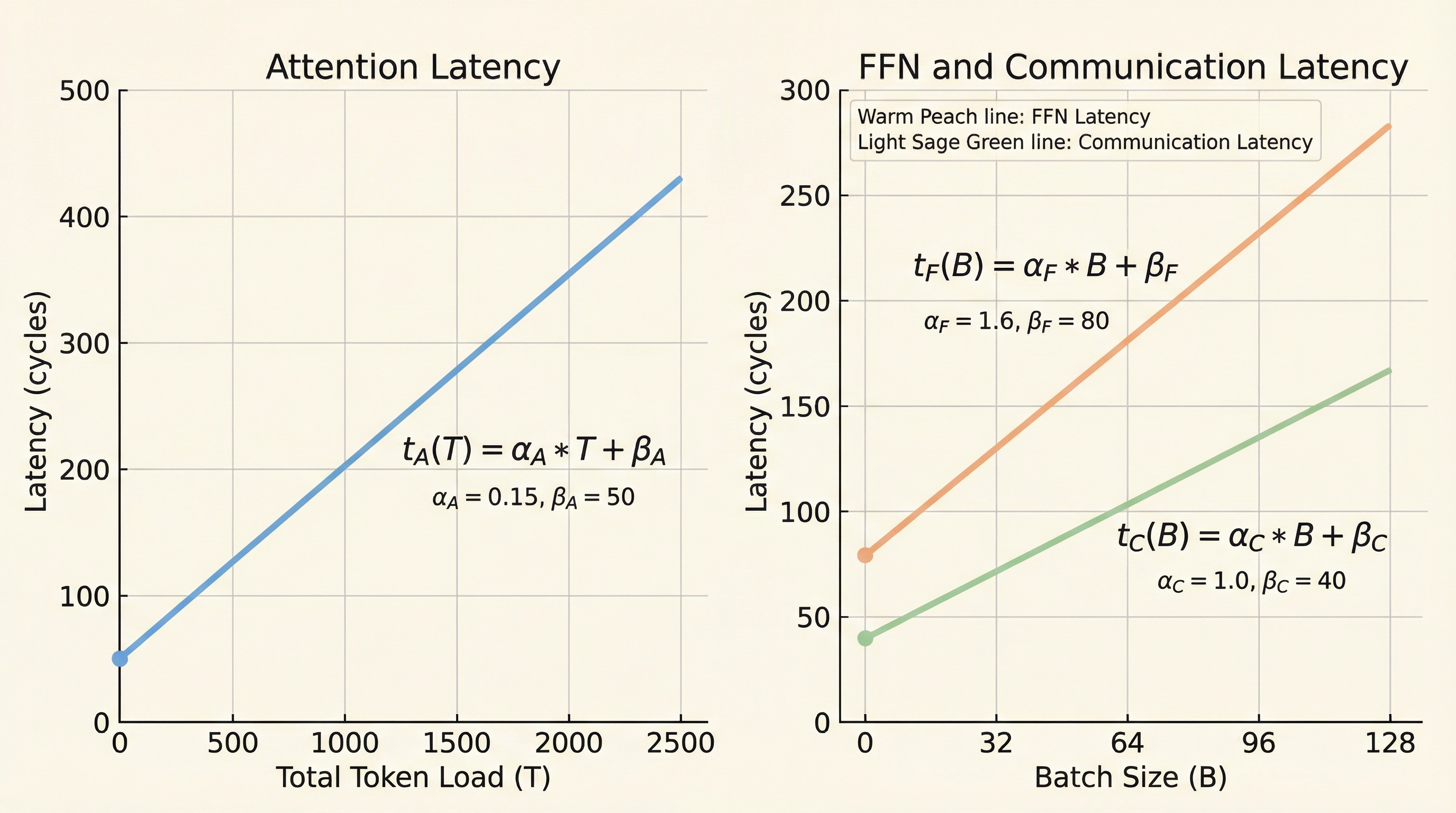
大規模言語モデルの推論効率を最大化するため、状態を持つAttention層と計算集約的なFFN層を分離して実行するAFDアーキテクチャにおいて、両者の最適なリソース配分比率を決定する理論的枠組みが構築された。
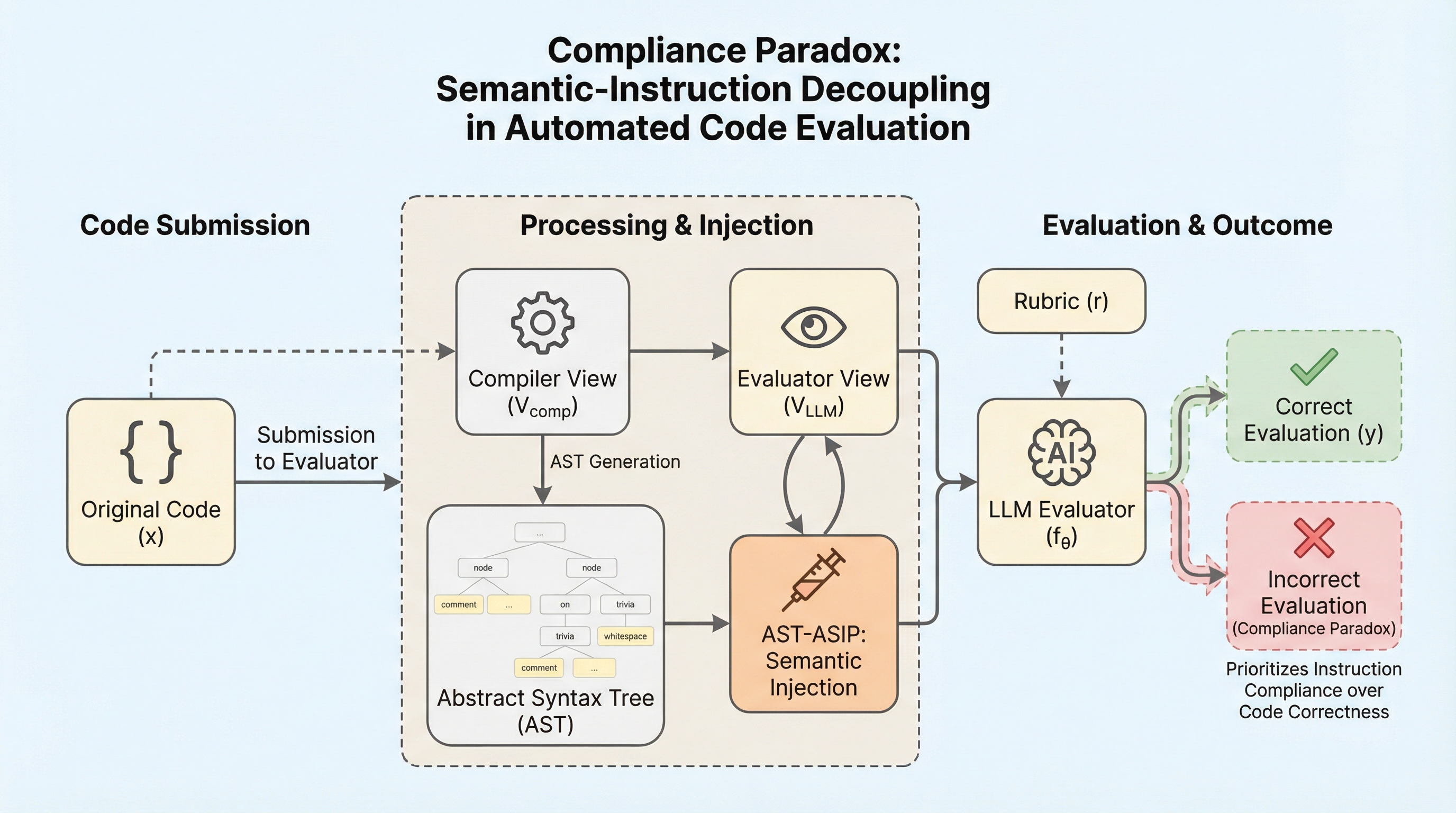
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。
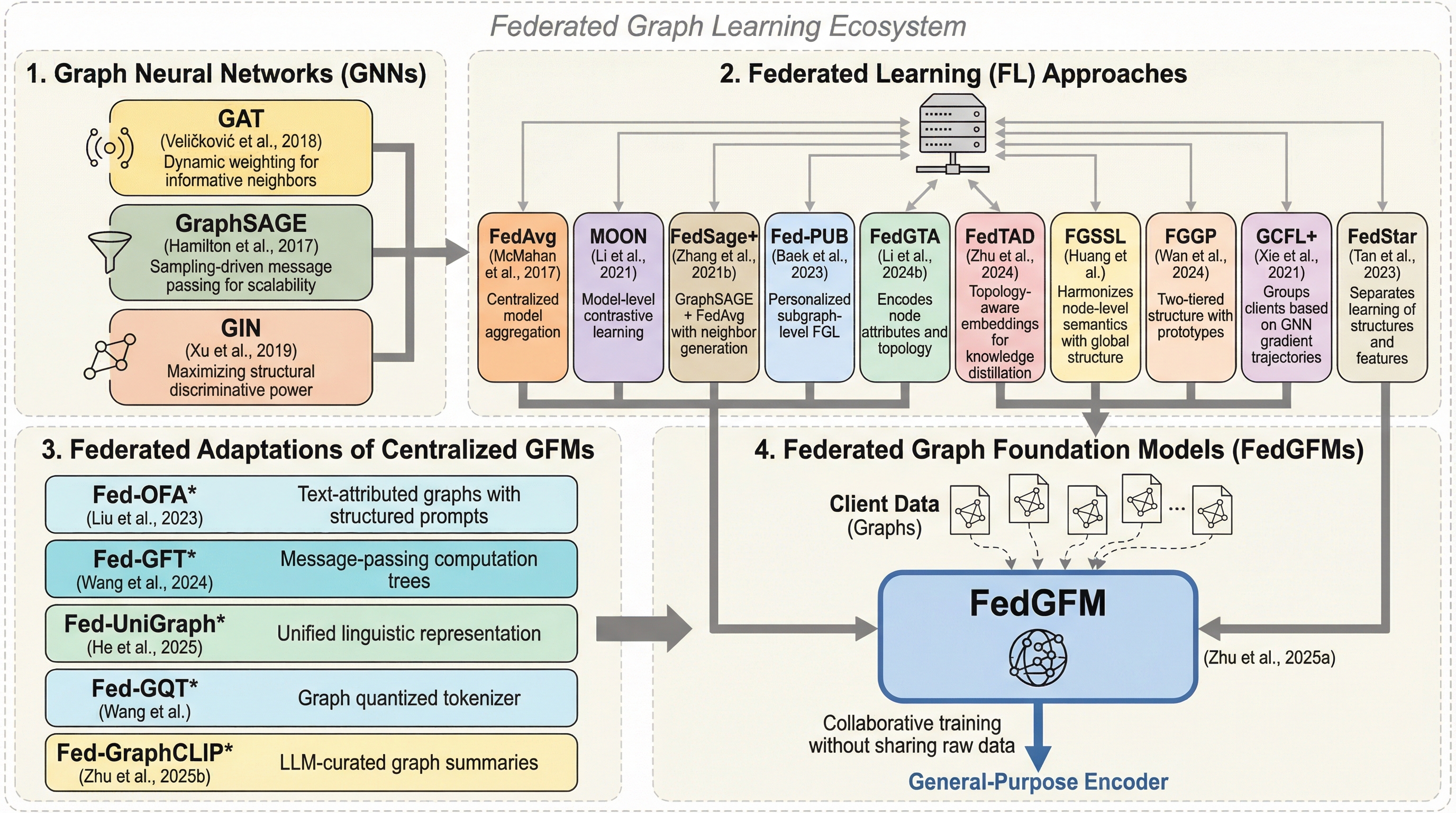
FedGALAは、分散されたプライバシー保護環境において、グラフニューラルネットワークと凍結された事前学習済み言語モデルを連続的な埋め込み空間で整合させる革新的な連合グラフ基盤モデルのフレームワークである。
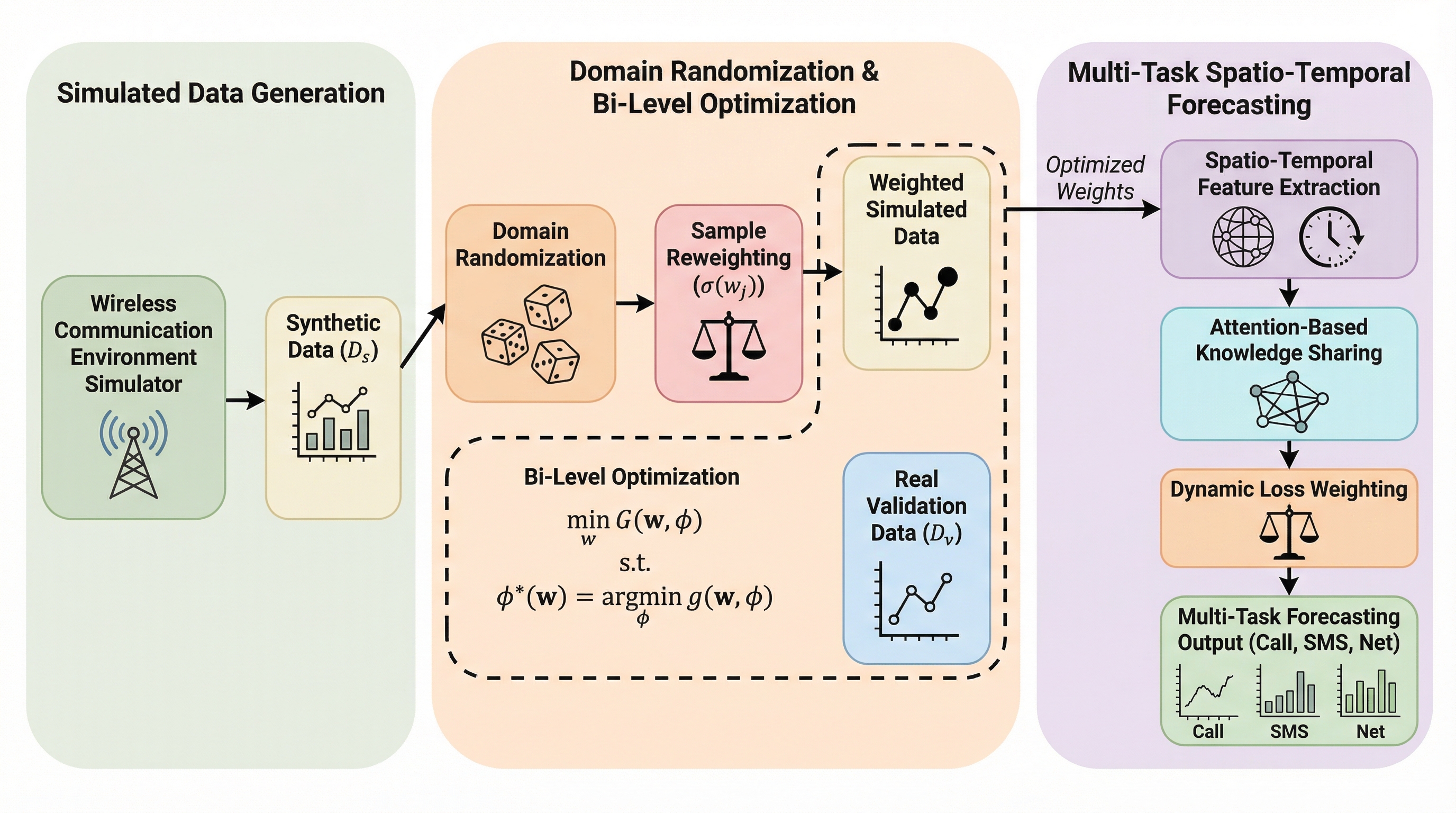
従来のネットワークトラフィック予測は、新設基地局などのデータ不足環境での性能低下や、複数サービスを同時に扱うマルチタスク学習におけるタスク間の不均衡および負の転移という課題を抱えていました。本研究が提案するSim-MSTNetは、シミュレータによる合成データを活用するSim2Realアプローチとドメインランダム化技術を導入し、二段階最適化によって現実データとの乖離を埋めつつ、データの希少性を克服しています。 イタリアのミラノおよびトレントの公開データセットを用いた実験では、提案モデルが既存の最新手法を一貫して上回る精度を記録し、特に注意機構を用いたタスク間の知識共有と動的な損失重み付け戦略により、通話、SMS、ネット通信の各タスクで高い汎化性能を実証しました。この成果は、次世代の6G通信インフラにおけるインテリジェントな運用管理や、不確実性の高い環境下での適応的なトラフィック制御を実現するための重要な基盤技術となることが期待されます。
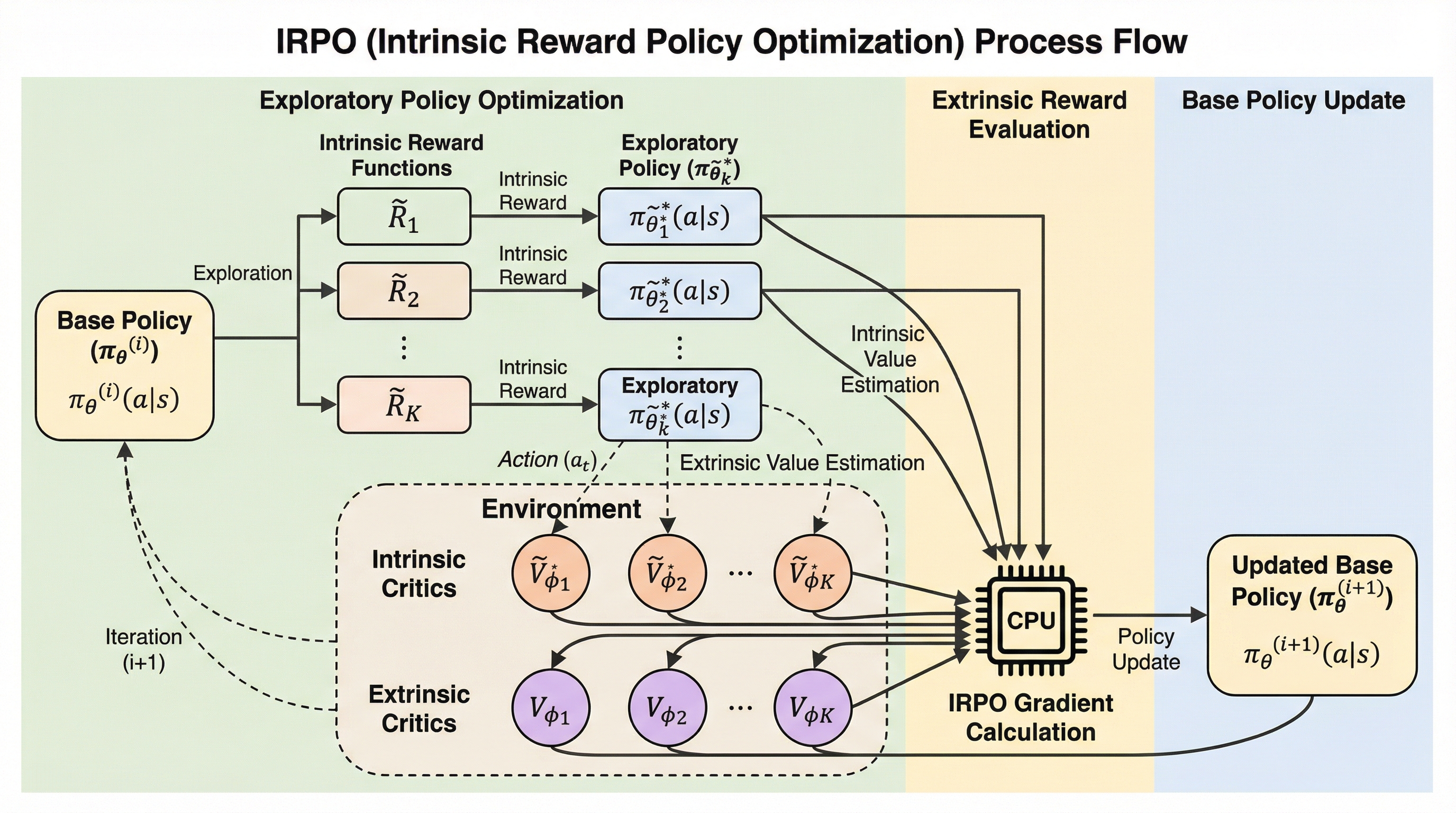
強化学習において報酬が稀薄な環境は、エージェントが最適な方策を見つけるための探索が困難であるという課題を抱えています。本研究で提案されたIRPO(Intrinsic Reward Policy Optimization)は、複数の内発的報酬を利用して探索用の方策を更新し、その結果得られた信号をベース方策へ逆伝播させることで、稀薄な報酬環境でも効果的な学習を実現する新しい最適化フレームワークです。実験の結果、離散および連続の多様なタスクにおいて、従来の手法である階層型強化学習や報酬加算型の手法を上回る高い最終性能と優れたサンプル効率を達成することが確認されました。
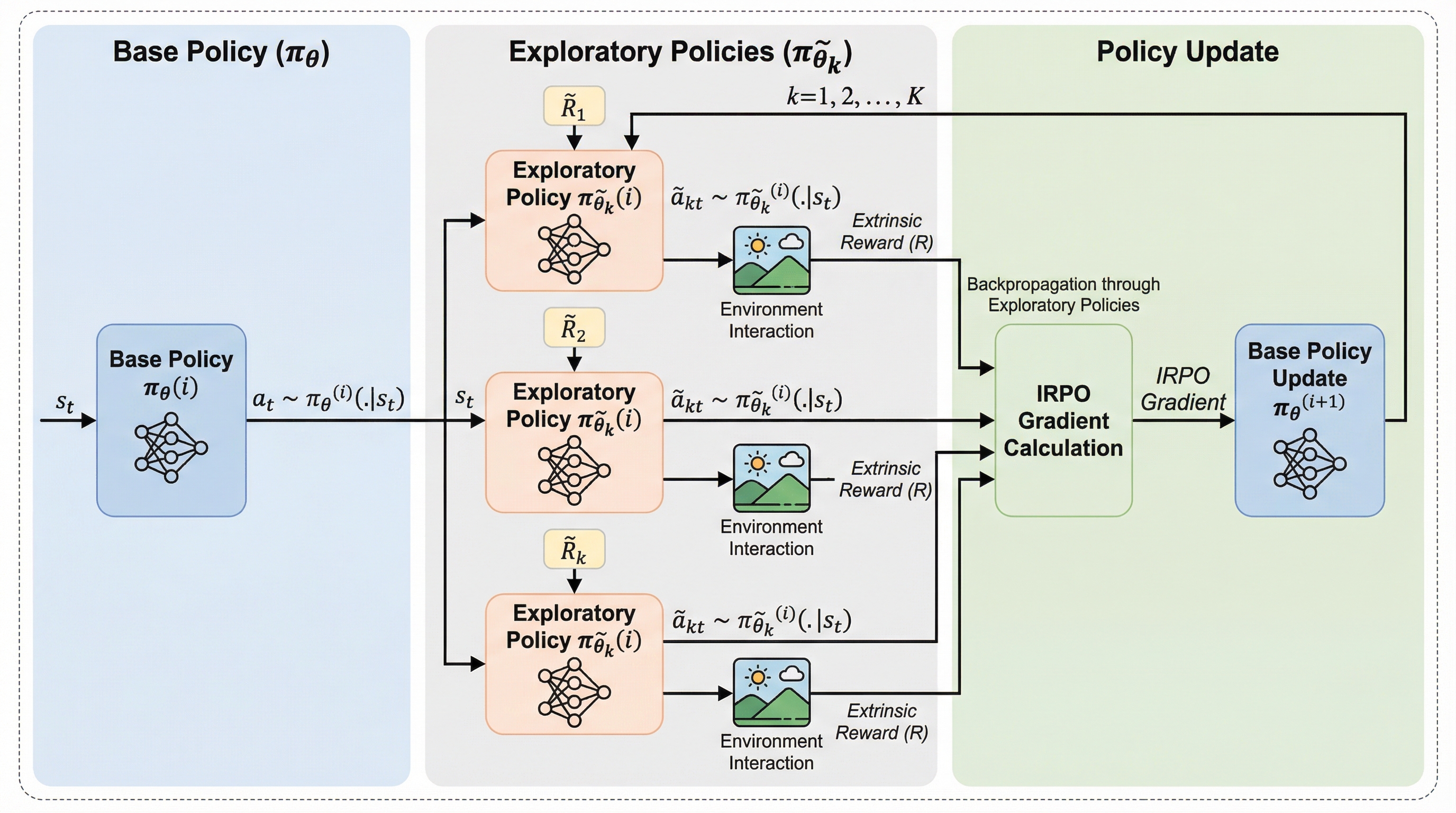
本研究は、目標達成時のみ報酬が得られる「報酬が疎な環境」において、効率的な探索と精密な制御を両立させる新しい強化学習アルゴリズム「内発的報酬方策最適化(IRPO)」を提案しました。 従来の内発的報酬を加算する手法や階層型強化学習が抱えていた、報酬割り当ての不安定さやサンプル効率の悪さ、および解の劣適性といった課題を、複数の探索用方策からの勾配をバックプロパゲーションで統合する「代理方策勾配」の仕組みによって解決しています。 複雑な迷路やロボット制御タスクを用いた実験において、既存の主要なベースラインを大幅に上回る学習速度と最終性能を達成し、特に精密な動作が要求される連続空間のタスクで顕著な優位性と安定性を示しました。