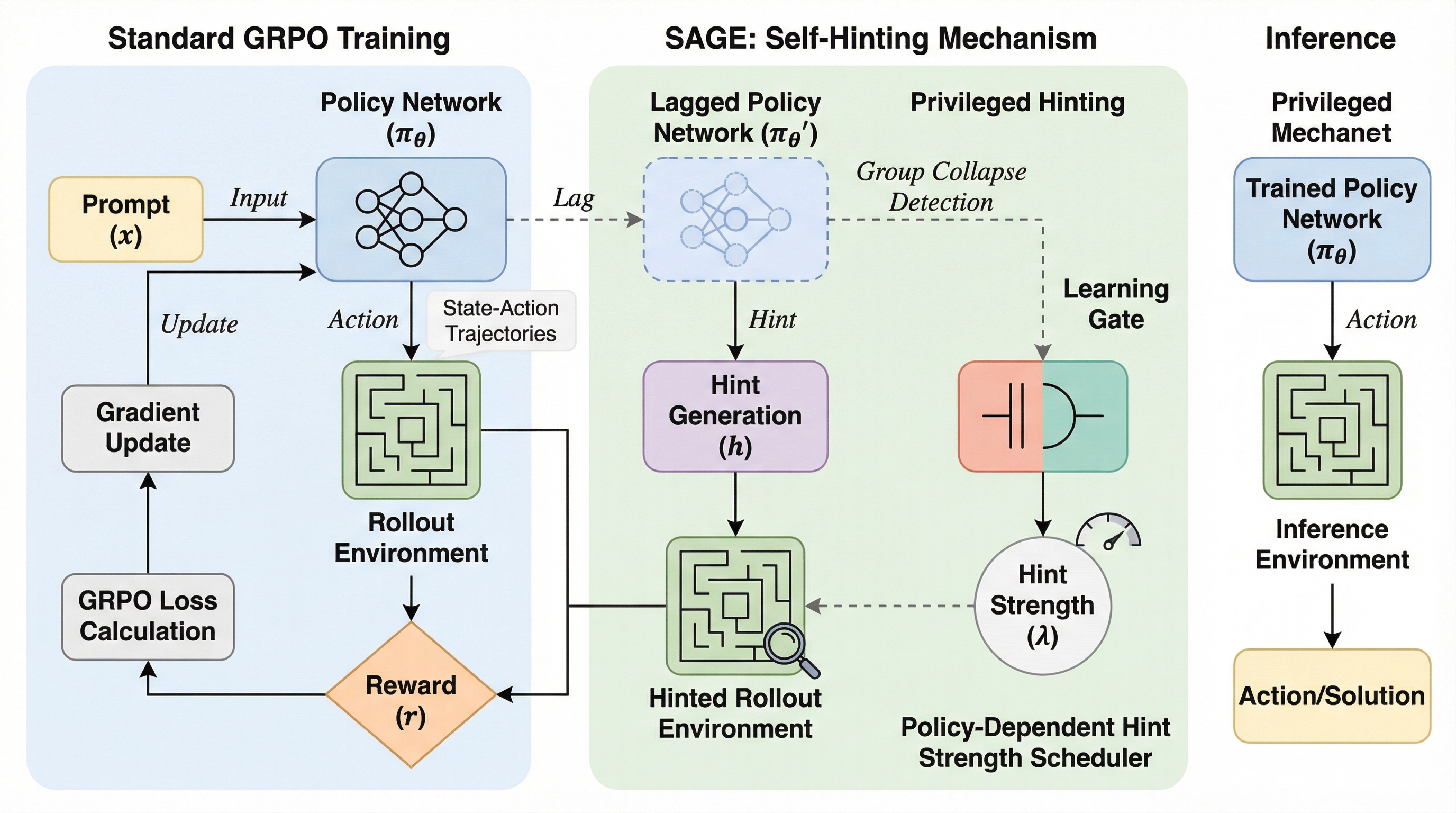
自己ヒント言語モデルが強化学習を強化する
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。
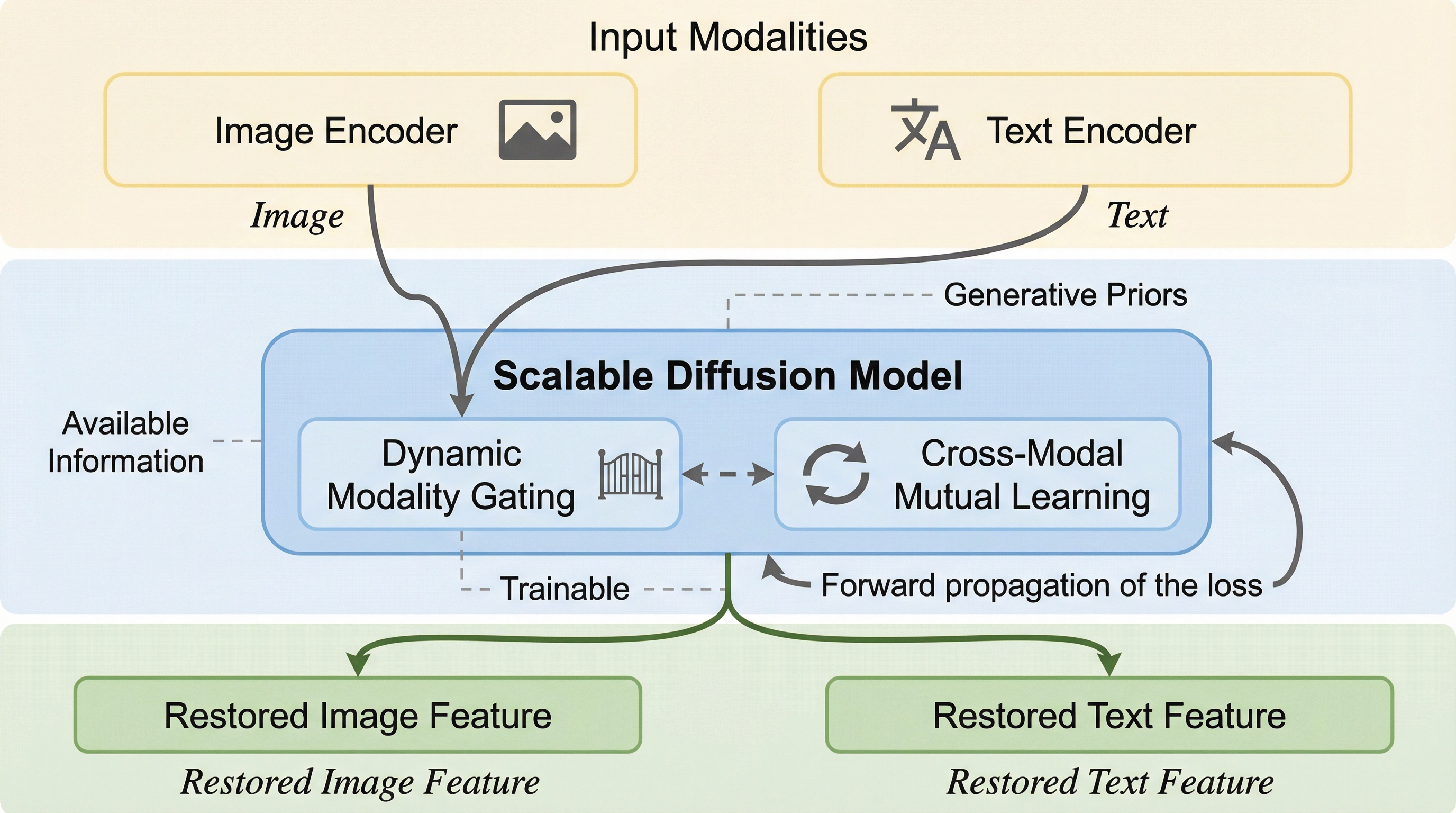
視覚と言語を統合する基盤モデル(VLM)は、推論時に画像やテキストのいずれかが欠損すると性能が著しく低下するという深刻な課題を抱えています。本研究はこの問題に対し、拡散モデルの強力な生成能力を活用して欠損した特徴を中間段階で復元する、既存のネットワークを凍結したままプラグインとして挿入可能な新しい学習戦略を提案しました。 提案手法には、利用可能な情報から意味的に一貫した特徴生成を導く「動的モダリティ・ゲーティング」と、画像とテキストの双方向で意味空間を整列させる「クロスモーダル相互学習」という二つの革新的な機構が導入されています。これにより、ノイズを抑制しながら失われた情報を高精度に補完し、単一モダリティ入力とマルチモーダル表現の間のギャップを効果的に埋めることが可能になりました。 4つの主要なベンチマークを用いたゼロショット評価において、既存のプロンプトベースや補完ベースの手法を全ての欠損シナリオで凌駕し、最高性能を達成しました。多様な欠損率や未知のデータセットに対しても高い堅牢性と汎用性を示すことが確認され、実世界のような不完全なデータ環境下での信頼性を飛躍的に高める、基盤モデルのための強力かつスケーラブルな拡張手法を確立しました。
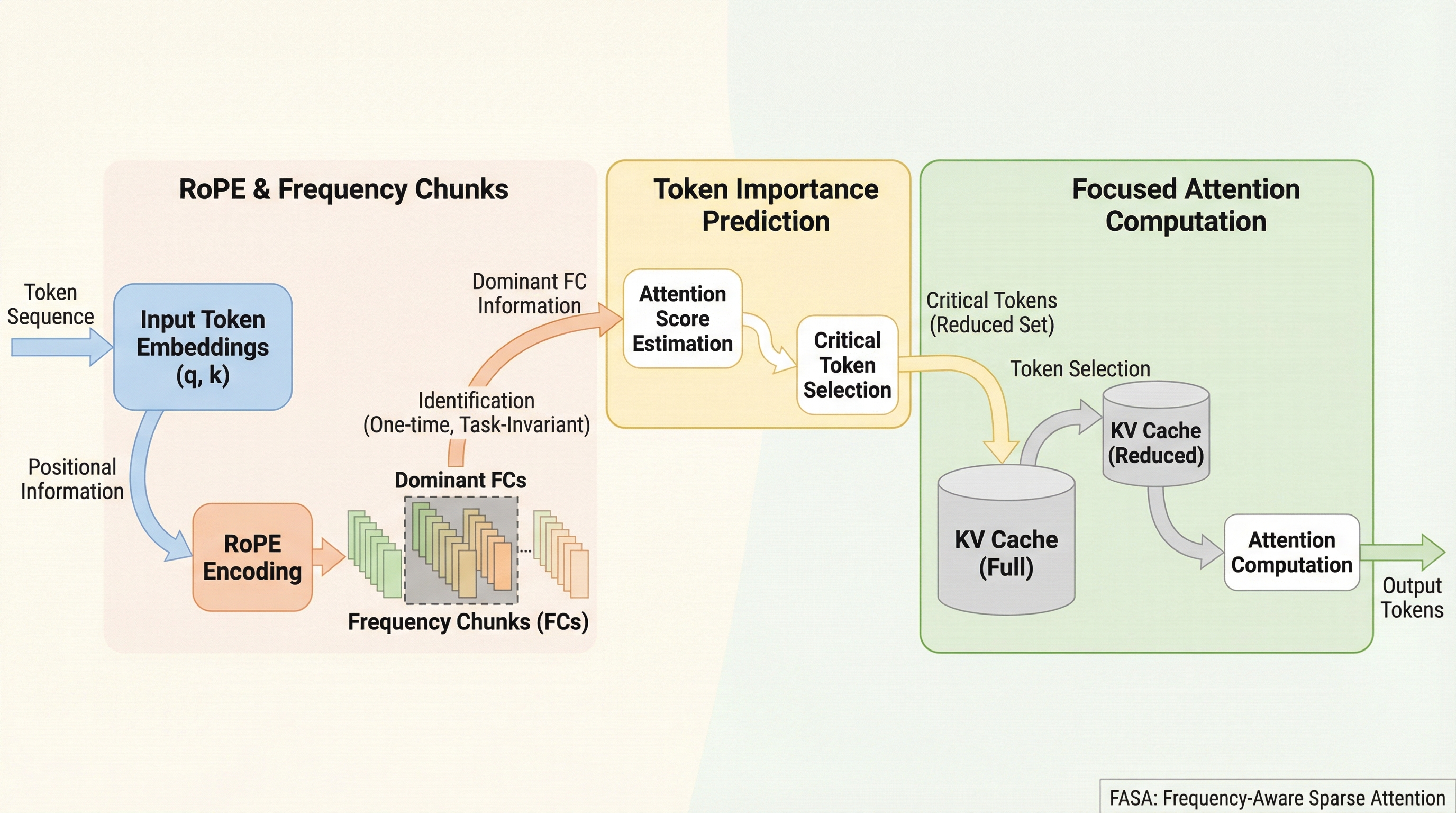
大規模言語モデルの長文処理におけるKVキャッシュのメモリ増大問題を解決するため、RoPE(回転位置エンコーディング)の周波数成分に存在する機能的な疎性を利用し、重要なトークンを動的に予測する学習不要のフレームワーク「FASA」が提案されました。
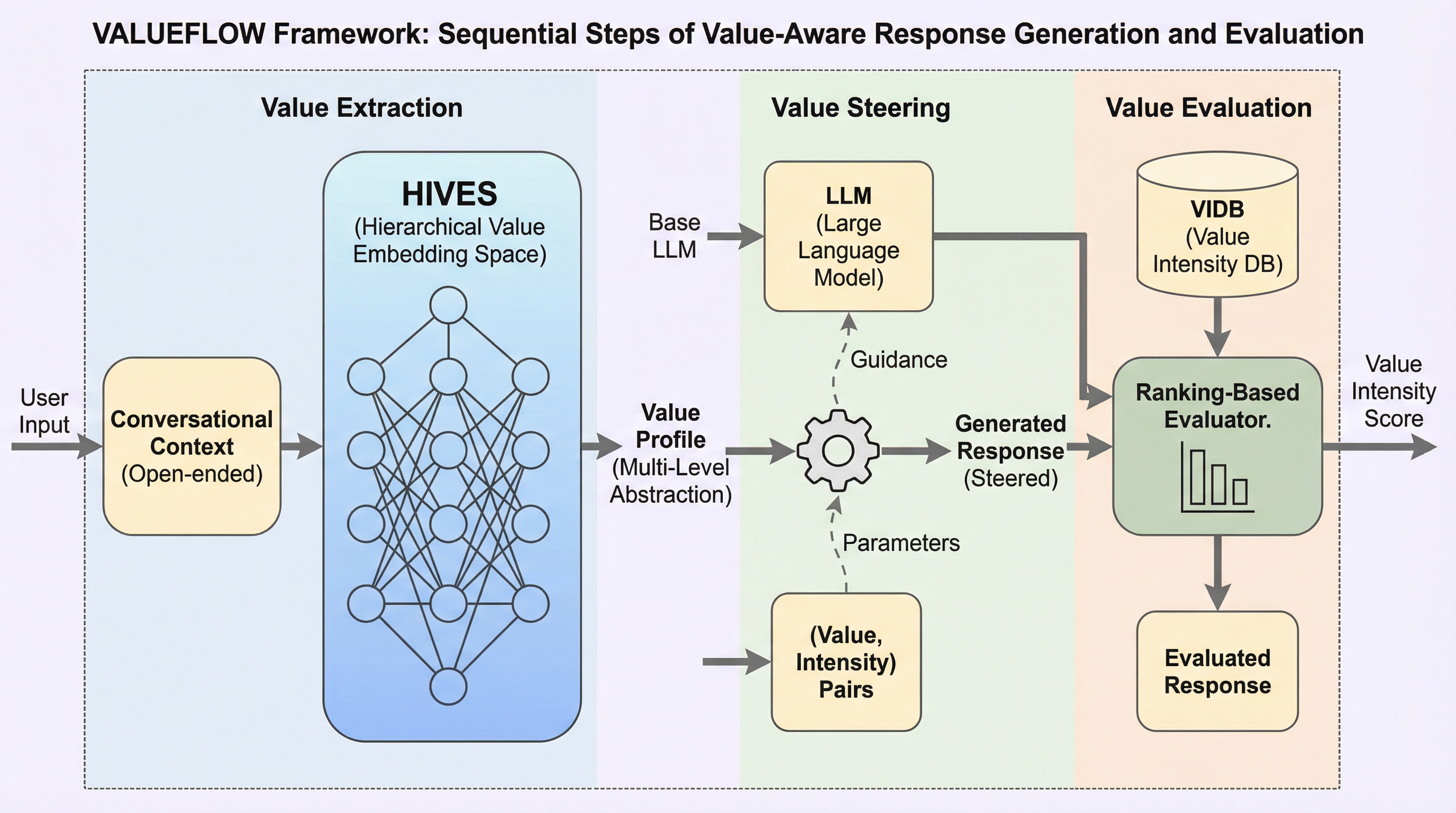
大規模言語モデルを多様な人間の価値観に適合させるため、抽出・評価・制御を統合した初の包括的フレームワークである「VALUEFLOW」が開発され、価値の階層構造を捉える埋め込み空間、大規模な強度データベース、および安定したアンカーベースの評価器が導入されました。
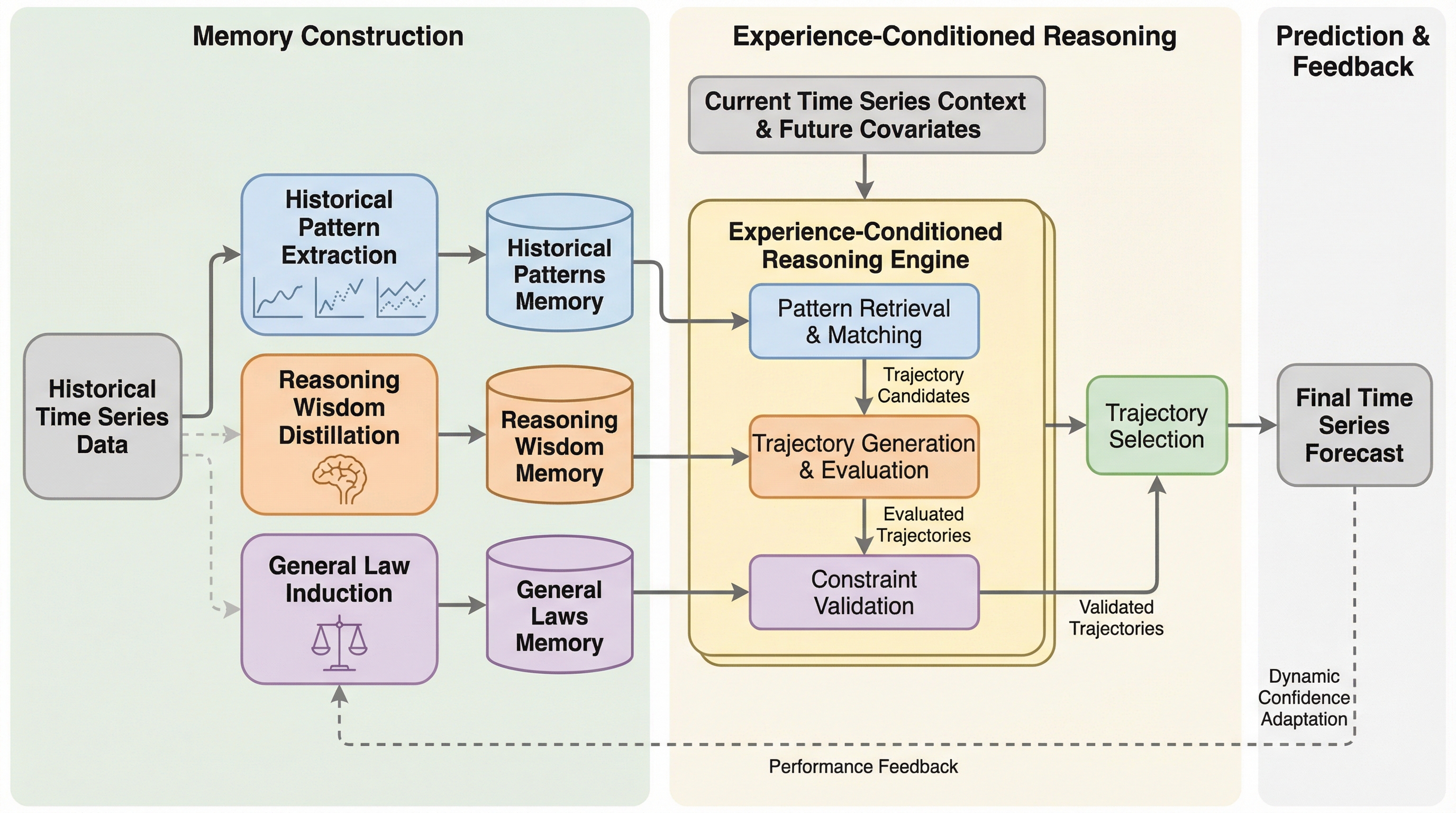
MemCastは、時系列予測を単なる数値回帰ではなく、過去の経験を条件とした推論タスクとして再定義し、大規模言語モデルに階層的な外部メモリを統合した新しいフレームワークである。 学習データから「歴史的パターン」「推論の知恵」「一般法則」の3層からなる構造化されたメモリを構築し、推論時にこれらを動的に参照・反映させることで、モデルの重みを再学習することなく高い精度と環境適応力を実現した。 電力価格、エネルギー発電量、河川流量などの多様な実データを用いた検証において、従来の統計手法や最新の深層学習モデルを一貫して上回る性能を示し、運用を通じた継続的な自己進化を可能にしている。
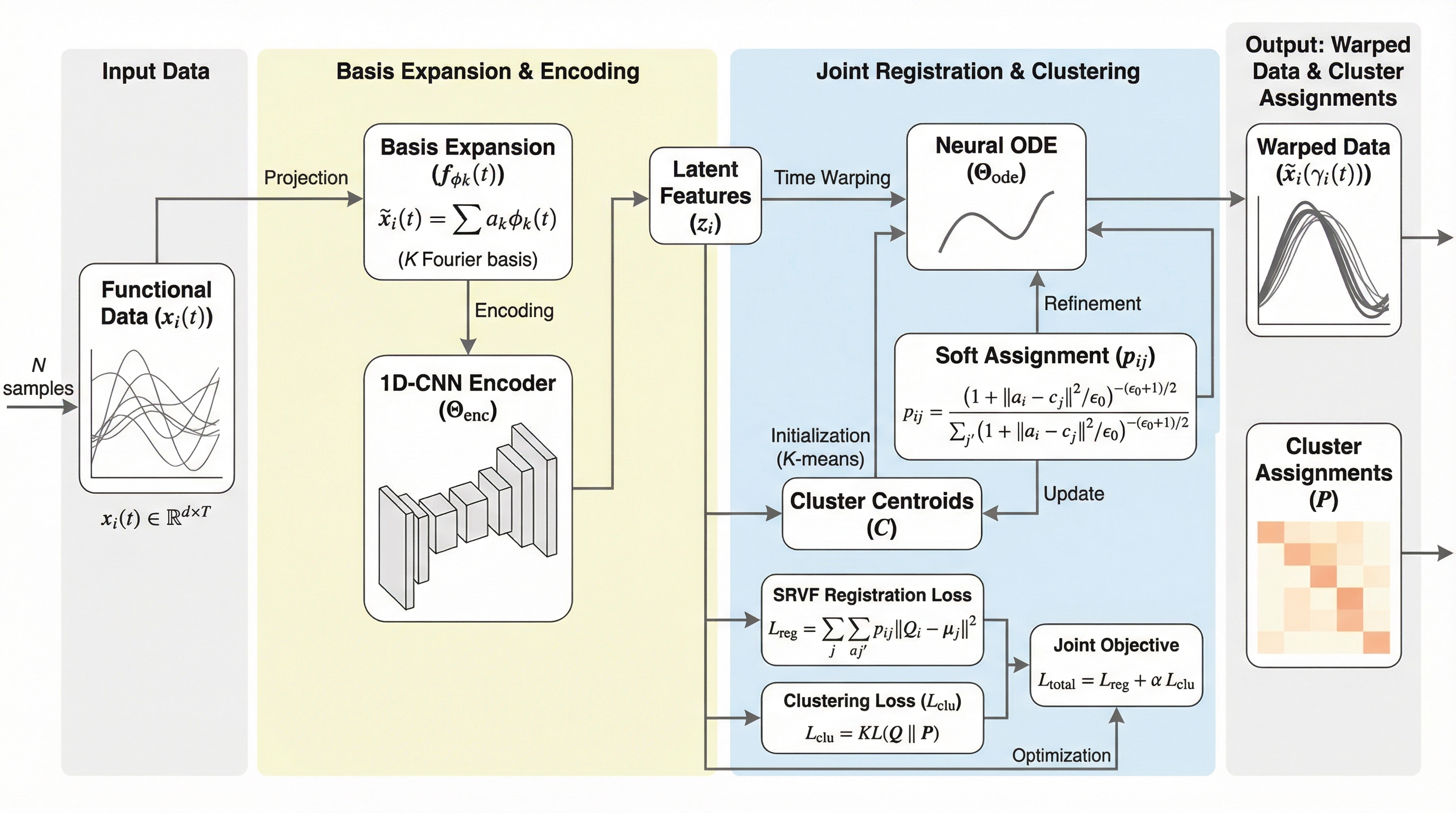
NeuralFLoCは、時間的なずれ(位相変動)を伴う関数データを高精度に分類するために開発された、完全教師なしの深層学習フレームワークである。Neural ODE(神経常微分方程式)を活用して滑らかで逆変換可能な微分同相の時間歪み関数を学習し、スペクトルクラスタリングと統合することで、データの位置合わせとグループ化を同時に最適化する。従来の段階的な手法や制約の強いモデルとは異なり、欠損値やノイズに対する堅牢性を備えつつ、大規模なデータセットに対しても線形時間での計算スケーラビリティを実現している。
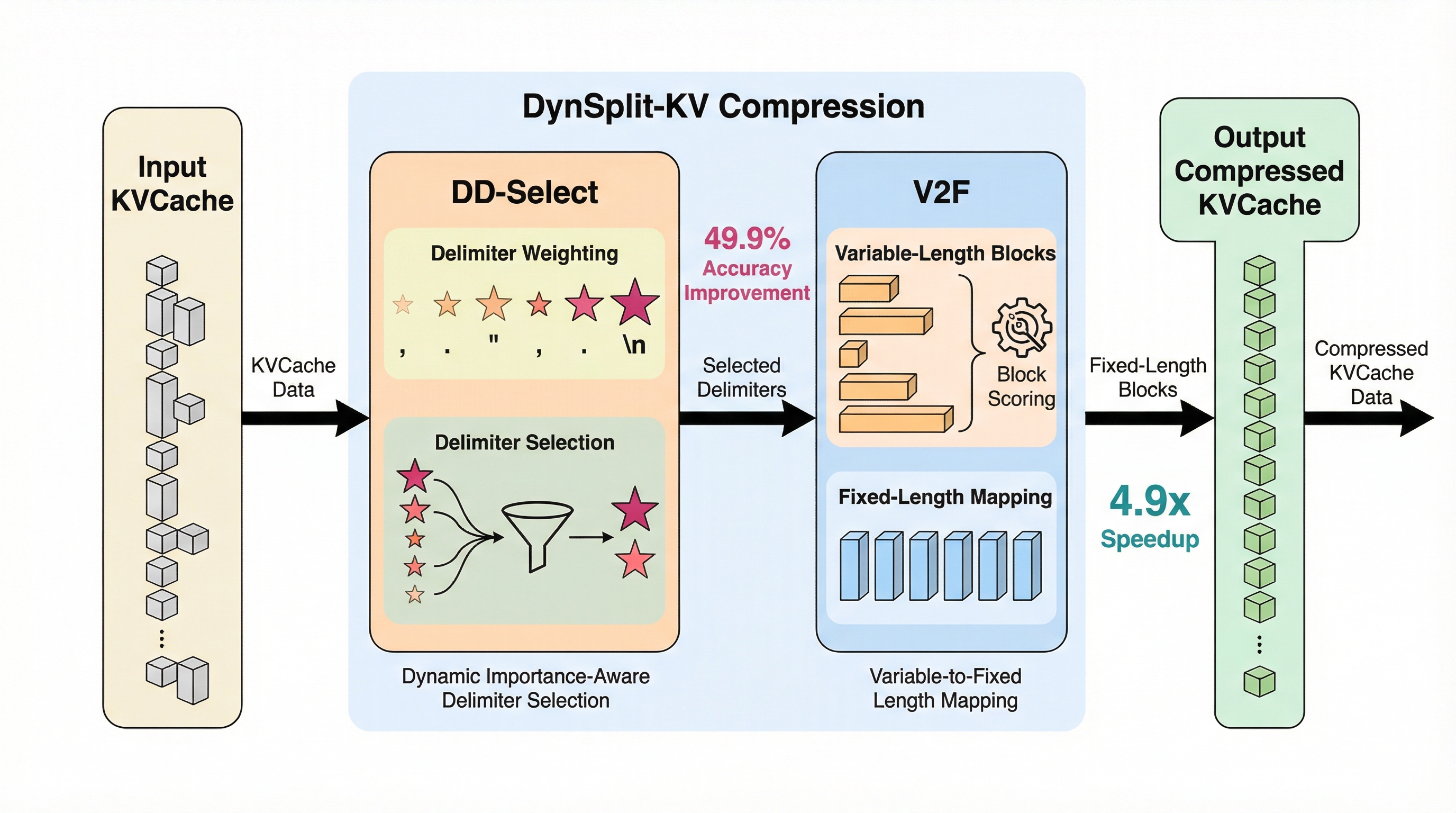
大規模言語モデルの長文推論において、従来の固定長や固定区切り文字によるKVキャッシュ分割は、文脈ごとの意味境界を無視するため最大55.1%もの大幅な精度低下を招くという深刻な課題がありましたが、本研究はこれを解決する動的分割手法を提案しました。
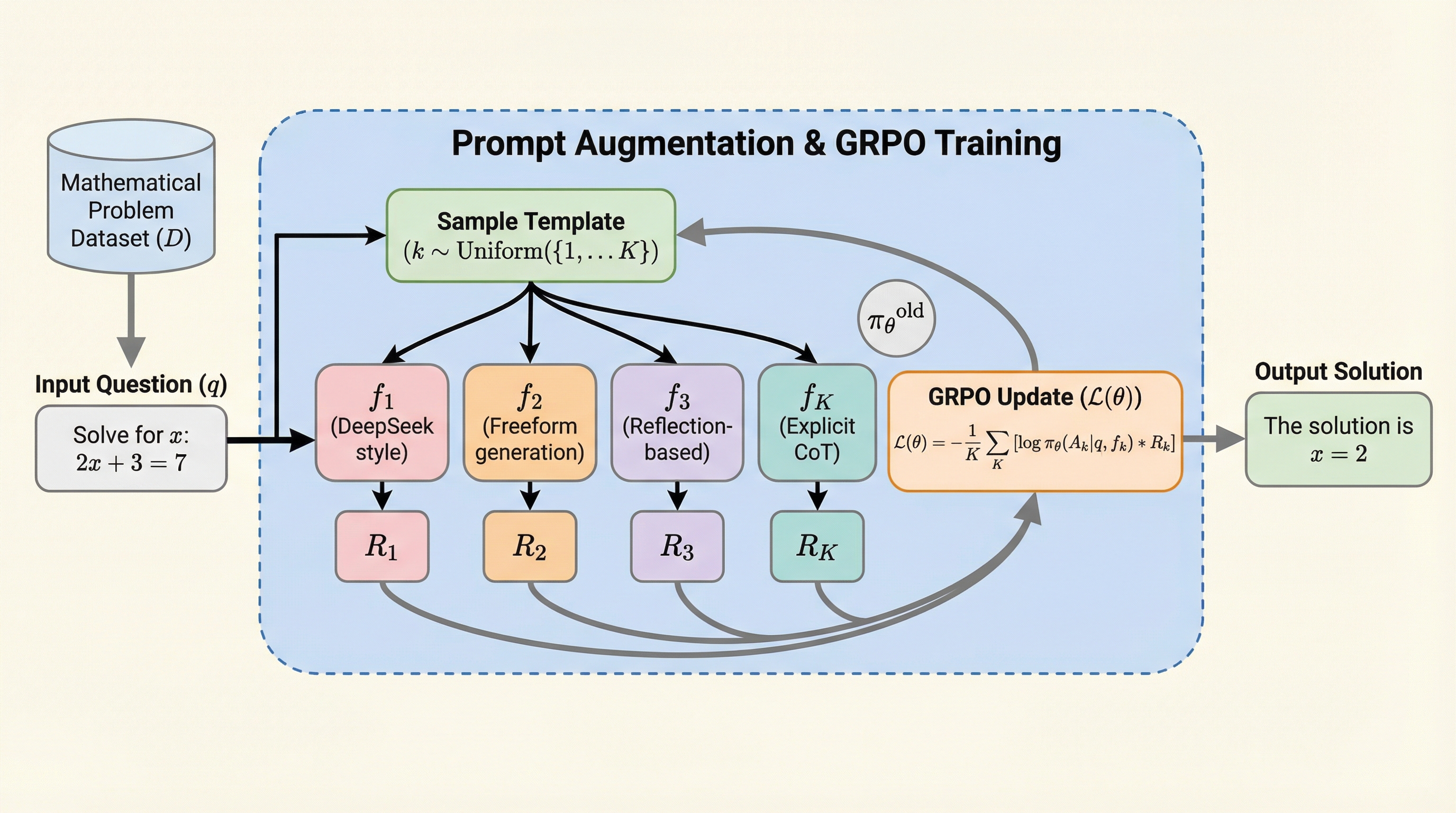
大規模言語モデルの数学的推論能力を向上させる強化学習において、従来はエントロピー崩壊による不安定性が原因で、学習が5〜20エポック程度の短期間に制限されるという課題がありました。本研究が提案する「プロンプト拡張」は、複数の推論テンプレートとフォーマット報酬を組み合わせることで、単一の学習実行内で多様な推論の振る舞いを引き出し、エントロピー崩壊を抑制することに成功しました。この手法により、Qwen2.5-Math-1.5Bモデルにおいて最大50エポックの安定した長期学習が可能となり、主要な数学ベンチマークで従来手法を上回る最高水準の精度を達成しました。具体的には、多様なテンプレートを用いることで低エントロピー状態でも学習を継続できる安定性を確保し、計算コストを抑えつつモデルの推論能力を最大限に引き出す新しいトレーニングパラダイムを提示しています。
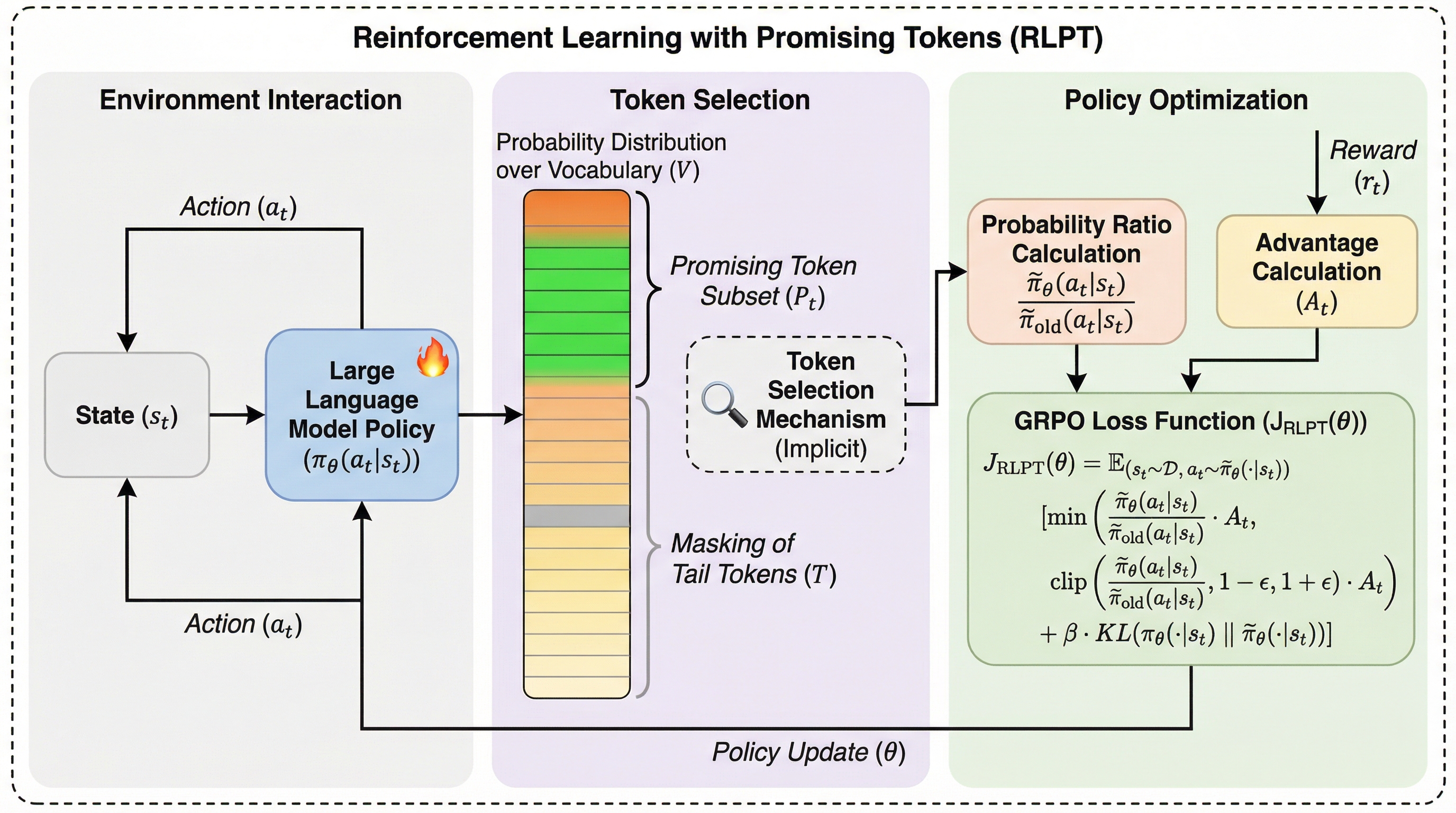
大規模言語モデル(LLM)の強化学習において、5万語を超える膨大な語彙全体を最適化対象とせず、モデルの事前知識に基づき論理的に妥当な「有望なトークン」だけに絞り込んで学習を行う新フレームワーク「RLPT」が提案されました。
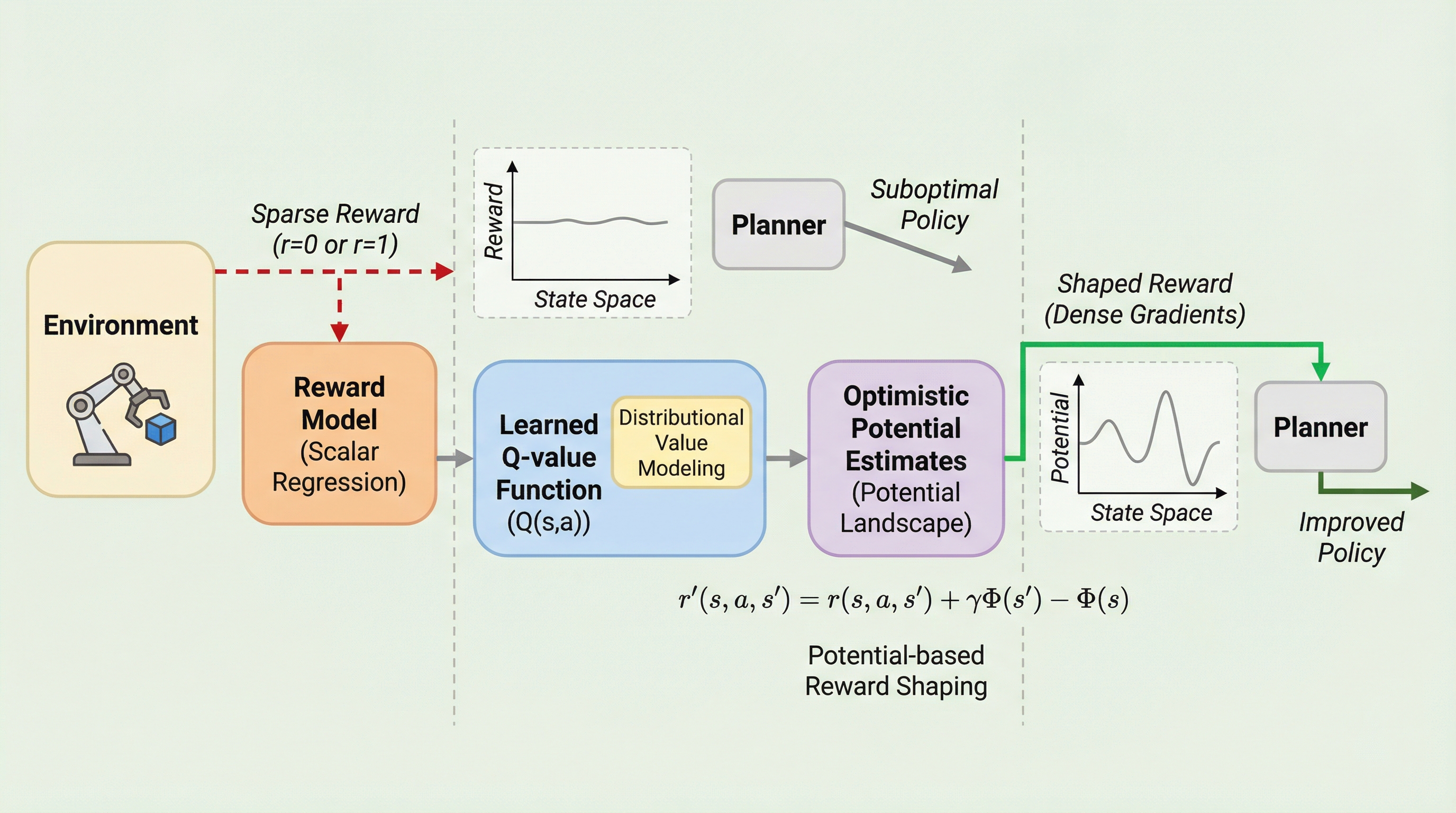
モデルベース強化学習(MBRL)はサンプル効率に優れるが、報酬が稀にしか得られない「疎な報酬」環境では、報酬モデルが平坦になり計画を導くための有益な勾配が消失するという深刻なボトルネックに直面する。