欠損モダリティに対する基盤VLMの堅牢性向上:双方向の特徴復元のためのスケーラブルな拡散
視覚と言語を統合する基盤モデル(VLM)は、推論時に画像やテキストのいずれかが欠損すると性能が著しく低下するという深刻な課題を抱えています。本研究はこの問題に対し、拡散モデルの強力な生成能力を活用して欠損した特徴を中間段階で復元する、既存のネットワークを凍結したままプラグインとして挿入可能な新しい学習戦略を提案しました。 提案手法には、利用可能な情報から意味的に一貫した特徴生成を導く「動的モダリティ・ゲーティング」と、画像とテキストの双方向で意味空間を整列させる「クロスモーダル相互学習」という二つの革新的な機構が導入されています。これにより、ノイズを抑制しながら失われた情報を高精度に補完し、単一モダリティ入力とマルチモーダル表現の間のギャップを効果的に埋めることが可能になりました。 4つの主要なベンチマークを用いたゼロショット評価において、既存のプロンプトベースや補完ベースの手法を全ての欠損シナリオで凌駕し、最高性能を達成しました。多様な欠損率や未知のデータセットに対しても高い堅牢性と汎用性を示すことが確認され、実世界のような不完全なデータ環境下での信頼性を飛躍的に高める、基盤モデルのための強力かつスケーラブルな拡張手法を確立しました。
TL;DR(結論)
視覚と言語を統合する基盤モデル(VLM)は、推論時に画像やテキストのいずれかが欠損すると性能が著しく低下するという深刻な課題を抱えています。本研究はこの問題に対し、拡散モデルの強力な生成能力を活用して欠損した特徴を中間段階で復元する、既存のネットワークを凍結したままプラグインとして挿入可能な新しい学習戦略を提案しました。 提案手法には、利用可能な情報から意味的に一貫した特徴生成を導く「動的モダリティ・ゲーティング」と、画像とテキストの双方向で意味空間を整列させる「クロスモーダル相互学習」という二つの革新的な機構が導入されています。これにより、ノイズを抑制しながら失われた情報を高精度に補完し、単一モダリティ入力とマルチモーダル表現の間のギャップを効果的に埋めることが可能になりました。 4つの主要なベンチマークを用いたゼロショット評価において、既存のプロンプトベースや補完ベースの手法を全ての欠損シナリオで凌駕し、最高性能を達成しました。多様な欠損率や未知のデータセットに対しても高い堅牢性と汎用性を示すことが確認され、実世界のような不完全なデータ環境下での信頼性を飛躍的に高める、基盤モデルのための強力かつスケーラブルな拡張手法を確立しました。
なぜこの問題か
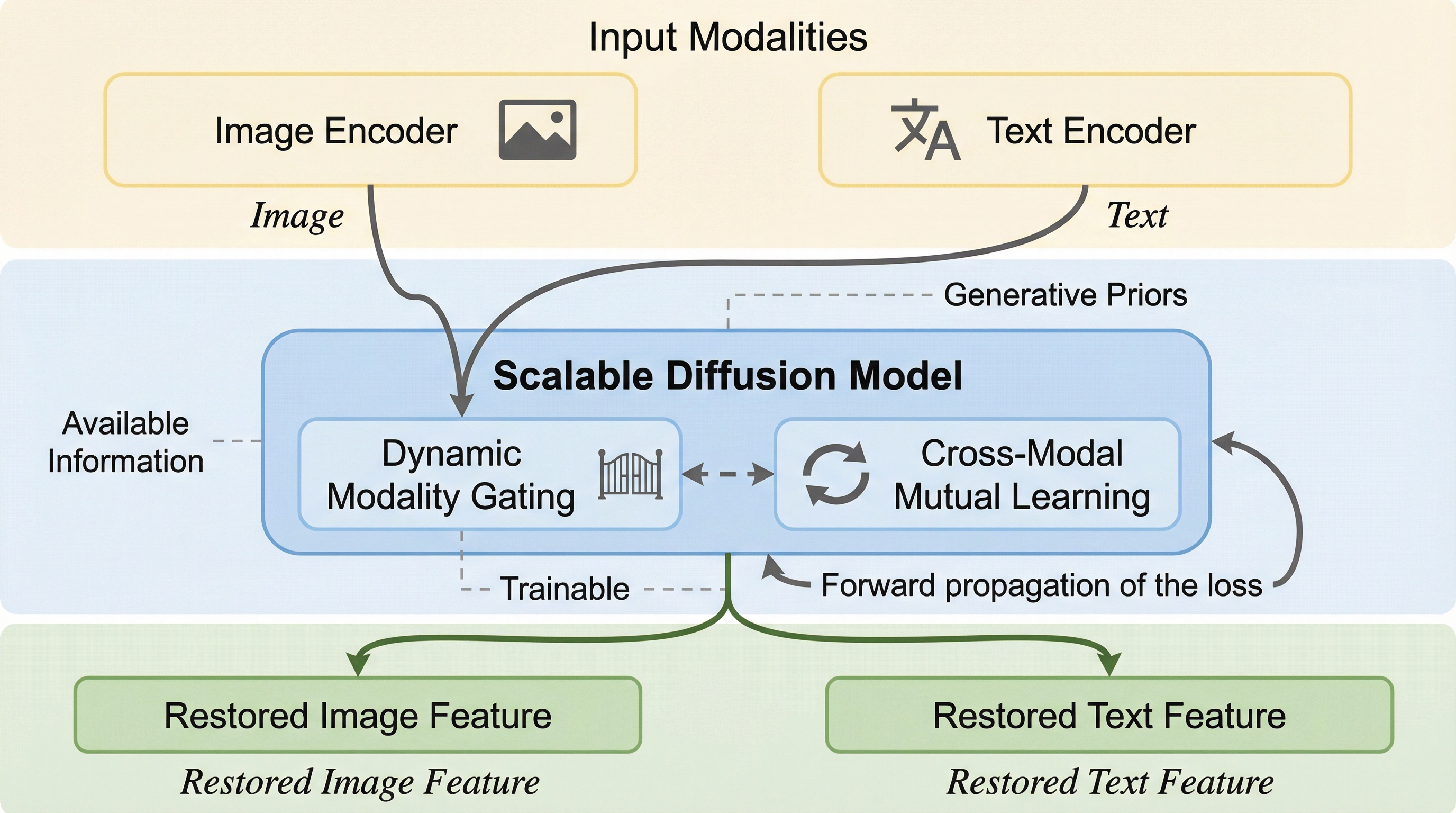
現代のマルチモーダル学習、特にCLIPやBLIPに代表される基盤的な視覚言語モデル(VLM)は、画像とテキストの双方を大規模に照合させることで、高度なクロスモーダルな意味空間を構築することに成功しています。しかし、これらのモデルの多くは、推論フェーズにおいてすべてのモダリティが完全に利用可能であるという理想的な仮定に基づいて設計されています。現実の運用環境においては、データの収集コスト、プライバシー保護、あるいはセンサーの不具合や通信エラーといった多様な要因により、特定のモダリティが欠損することは避けられない課題となっています。画像が利用できない、あるいはテキストによる説明が不足しているといった状況下では、従来のVLMの性能は急激に低下し、その汎用性が大きく制限されてしまいます。 既存の研究では、この欠損モダリティの問題に対して主に二つのアプローチが取られてきました。一つはプロンプトベースの手法であり、学習可能なプロンプトを導入することで欠損に対応しようとしますが、これらは特定のデータセットに依存した適応に留まり、VLMが本来持つ広範な汎用性を損なう傾向があります。…
核心:何を提案したのか
本論文では、スケーラブルな拡散モデル(Diffusion Model)をベースとした、新しい欠損モダリティ復元戦略を提案しています。この手法の最大の特徴は、VLMの既存のネットワークを凍結したまま、その中間段階にプラグインとして挿入可能なトレーニングモジュールを導入した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related