組合せ最適化問題。はい、その通りです。 * 待ってください、プロンプトには「同じ文章をセクション間で繰り返さない」とあり
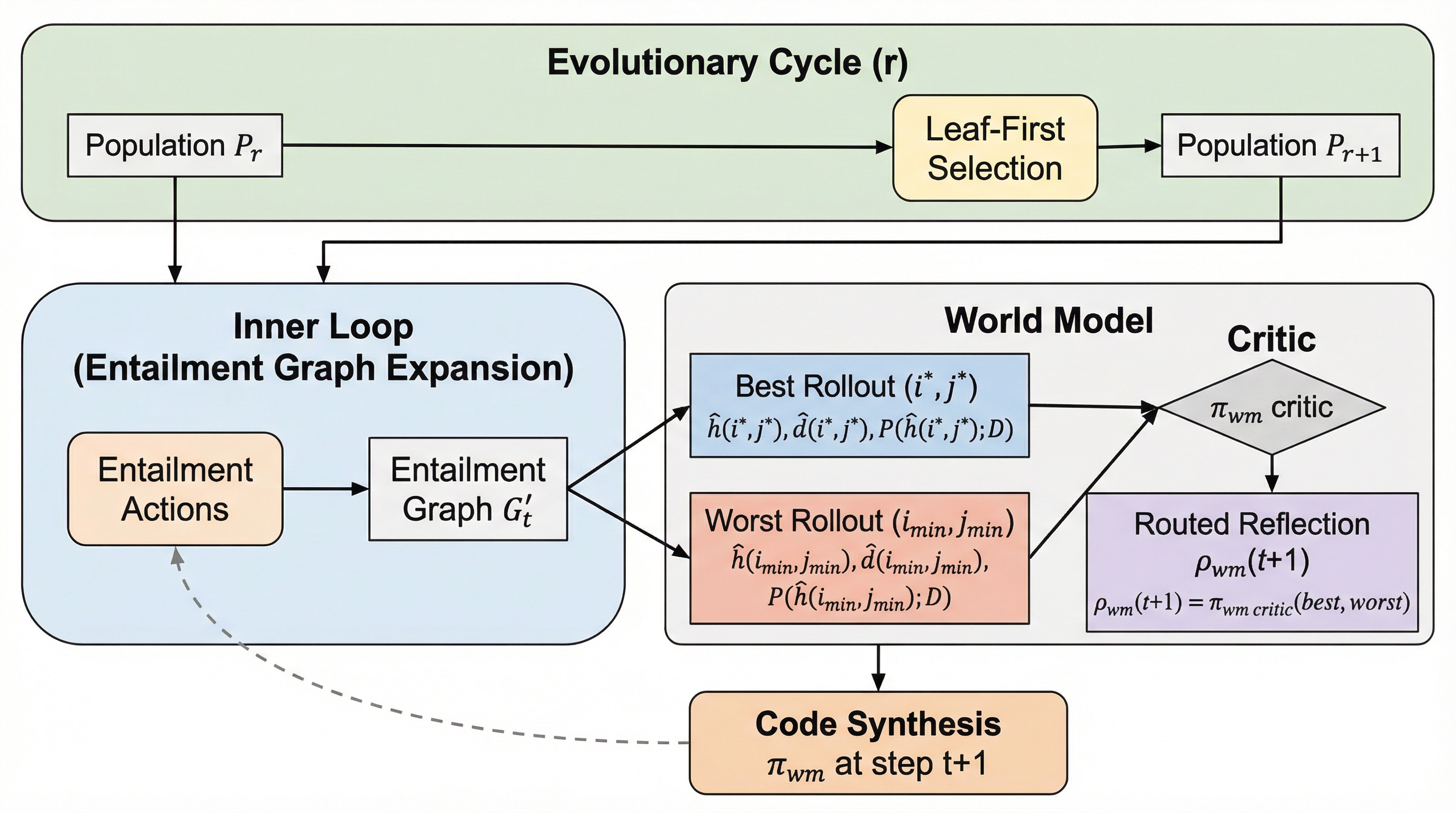
組合せ最適化問題の解決に不可欠なヒューリスティック設計を自動化する手法として、大規模言語モデル(LLM)を用いた自動ヒューリスティック設計(AHD)が注目されていますが、既存手法は固定ルールや静的プロンプトに依存し、探索履歴を十分に活用できないという課題がありました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
組合せ最適化問題の解決に不可欠なヒューリスティック設計を自動化する手法として、大規模言語モデル(LLM)を用いた自動ヒューリスティック設計(AHD)が注目されていますが、既存手法は固定ルールや静的プロンプトに依存し、探索履歴を十分に活用できないという課題がありました。
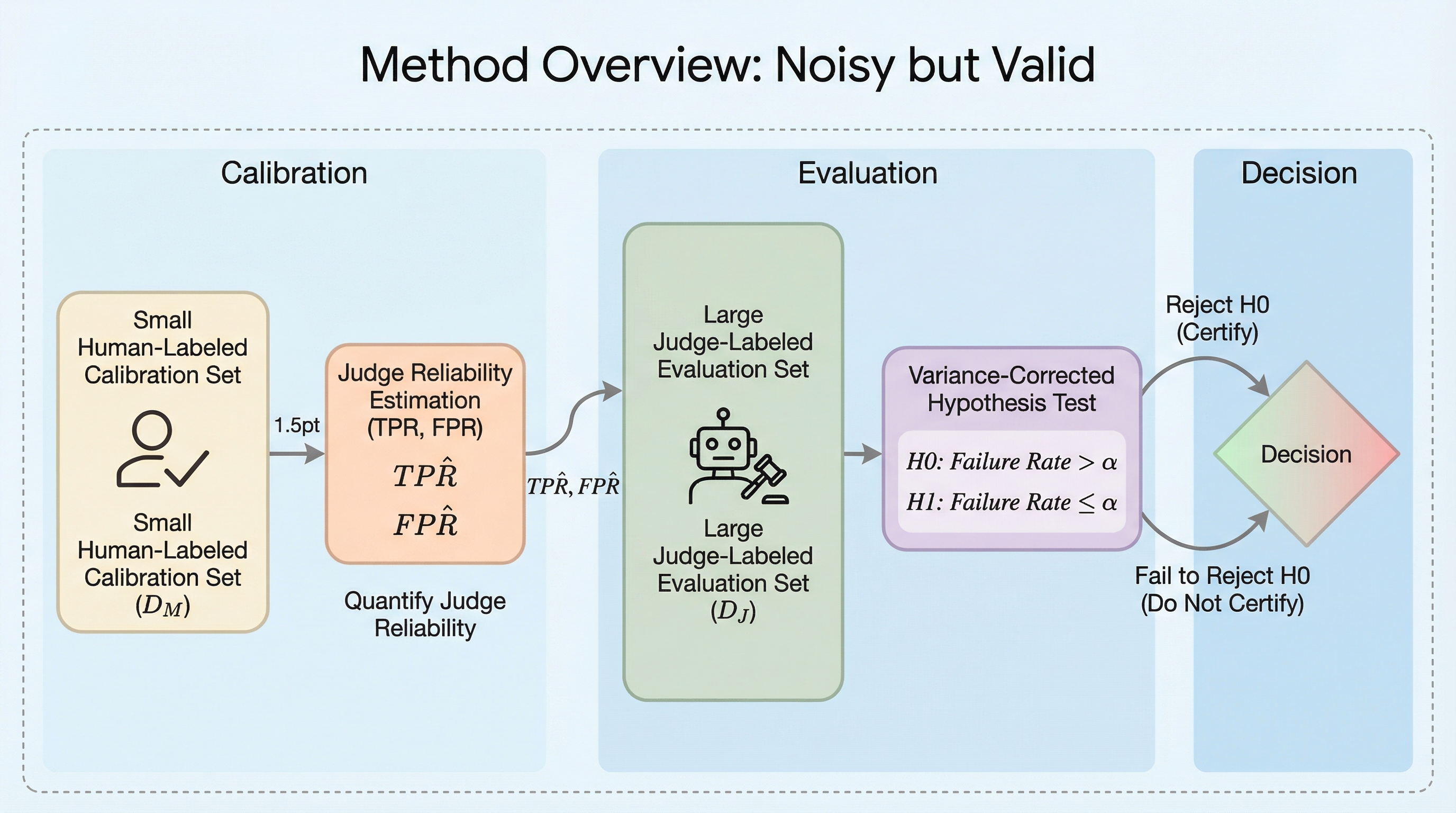
大規模言語モデル(LLM)の安全性を評価する「LLM-as-a-Judge」は、拡張性に優れる一方で評価者の誤りやバイアスが統計的信頼性を損なうという深刻な課題を抱えていたが、本研究は少量の人間によるラベル付きデータを用いて評価者の特性(真陽性率と偽陽性率)を精密に推定し、大規模な自動評価データセットに対して分散補正を適用する新しい統計的枠組み「Noisy but Valid」を提案することで、この問題を根本から解決した。 この枠組みは、評価者が不完全であっても、安全でないモデルを誤って合格させてしまう「第一種過誤」を理論的に有限サンプル内で厳密に制御することを保証しており、従来の人間による直接的な評価手法と比較して、評価者の品質が一定の基準を超えている場合には統計的な検出力を大幅に向上させることが可能であり、評価コストの劇的な削減と信頼性の向上を同時に達成している。 既存の予測駆動型推論(PPI)とは異なり、評価者のエラープロファイルを明示的にモデル化することで、評価プロセスの透明性と診断能力を確保しており、実務者が評価者の信頼性を客観的に判断し、データセットの規模や認定要件に応じた最適な評価プロトコルを設計するための理論的かつ実践的な基盤を提供している点が、本研究の最も重要な貢献である。
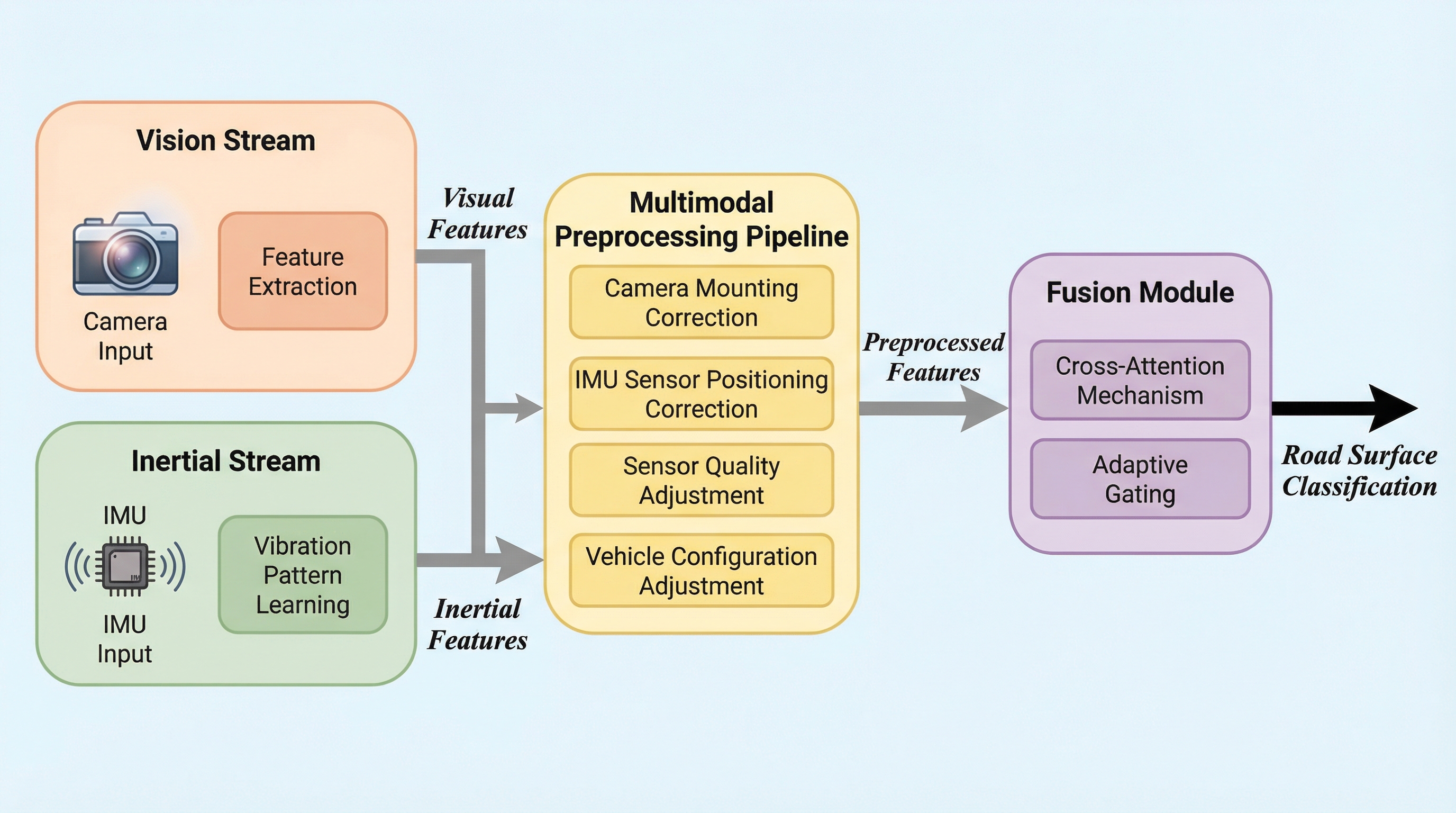
従来の路面分類技術は、日中の良好な視界を前提とした単一センサーの手法が主流であり、夜間や豪雨、未舗装路といった過酷な実環境下での堅牢性や汎用性に課題があった。本研究では、カメラ画像と慣性計測装置(IMU)のデータを統合し、環境変化に柔軟に対応できる新しいマルチモーダル学習フレームワークを提案することで、視覚情報が制限される条件下でも安定した認識を実現した。 提案手法の核心は、軽量な双方向クロスアテンション機構と適応型ゲート融合モジュールを導入した点にあり、画像と振動の情報を相互に補完させながら、状況に応じて各センサーの寄与度を動的に調整する。これにより、特定のセンサーがノイズの影響を受けた場合でも、もう一方の情報を優先的に活用することで、高精度かつ一貫性のある路面判別を継続することが可能となった。 検証のために構築された大規模データセット「ROAD」は、実世界の多様な天候や照明条件、連続走行シーケンス、さらには合成データを含んでおり、従来のベンチマークを大幅に上回る性能向上を実証した。この成果は、安価なセンサー構成での高度な路面理解を可能にし、車両の走行環境に応じた適切な予防保守システムの実現や、自動運転技術の信頼性向上に大きく貢献するものである。
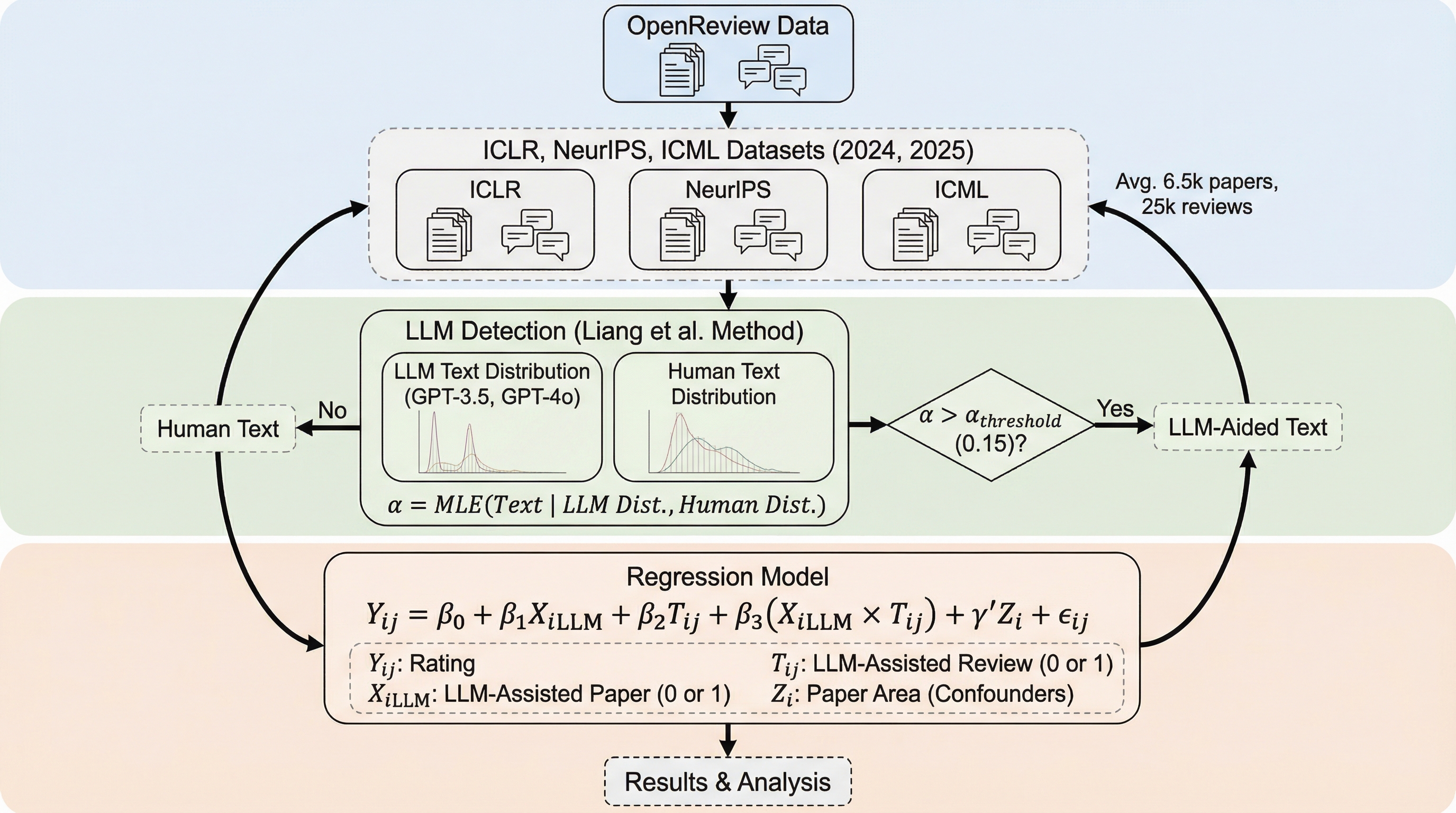
学術会議の査読において、LLMを用いた査読がLLM執筆の論文を不当に高く評価する「相互作用効果」の有無を、12万件以上のデータから検証した結果、初期分析で見られた「優遇」は、LLM査読が低品質な論文全般に対して寛容な評価を下す傾向に起因する見かけ上の現象であることが判明した。
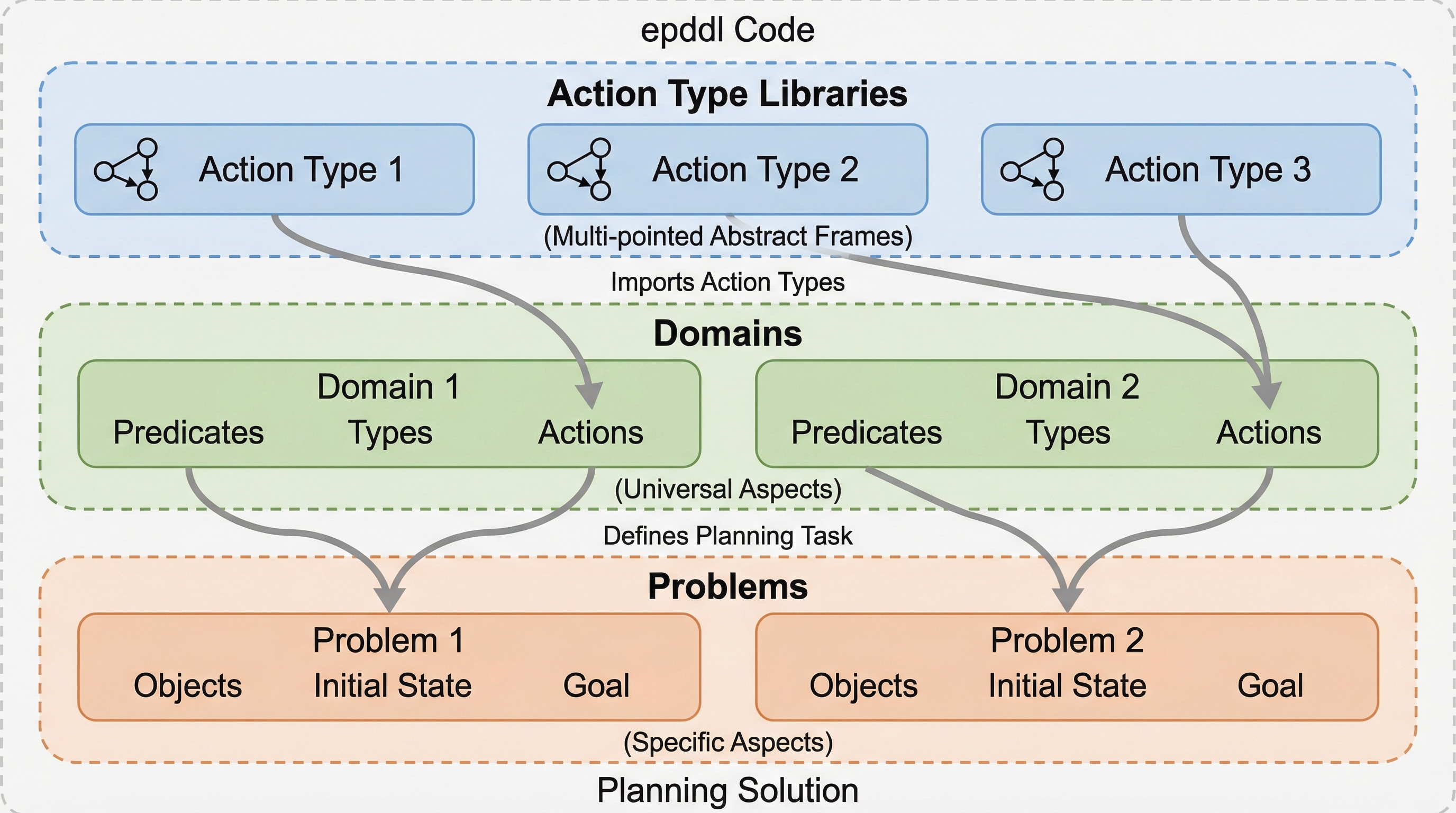
エピステミック・プランニングは、エージェントの知識や信念を第一級の要素として扱う自動計画法の一種であり、動的エピステミック論理(DEL)を基盤とするが、既存のプランナーは独自の言語や特定の断片のみを対象としていたため、比較や再利用が困難な断片化の状態にあった。
ウルドゥー語における大規模言語モデルの複雑な推論能力を厳密に評価するため、複数の翻訳システムと人間による検証を組み合わせた高品質なベンチマーク「UrduBench」が構築されました。算術、記号数学、常識、科学的知識を網羅する4つの主要な英語データセットを、文脈の整合性を維持しながらウルドゥー語へ移植することで、従来の機械翻訳手法で課題となっていた意味の断片化や論理的矛盾を解消しています。 評価の結果、思考の連鎖(Chain-of-Thought)プロンプトの導入と言語的一貫性の維持が推論の成功に不可欠であることが示され、モデルの規模以上に多言語学習の質や命令チューニングの精度が重要であることが明らかになりました。本研究は、低リソース言語における標準的な評価手法を提示するだけでなく、他の言語にも応用可能な高品質なデータセット構築のガイドラインを提供しています。 算術推論を測定するMGSM、記号数学を扱うMATH-500、常識的な推論を評価するCommonSenseQA、そして事実知識に基づく科学的推論を問うOpenBookQAという、世界的に広く利用されている4つの英語データセットをウルドゥー語に移植しました。これにより、低リソース言語の評価において最大の障壁となっていた翻訳エラーによるノイズを最小限に抑え、モデルが持つ純粋な推論能力を抽出することが可能になりました。
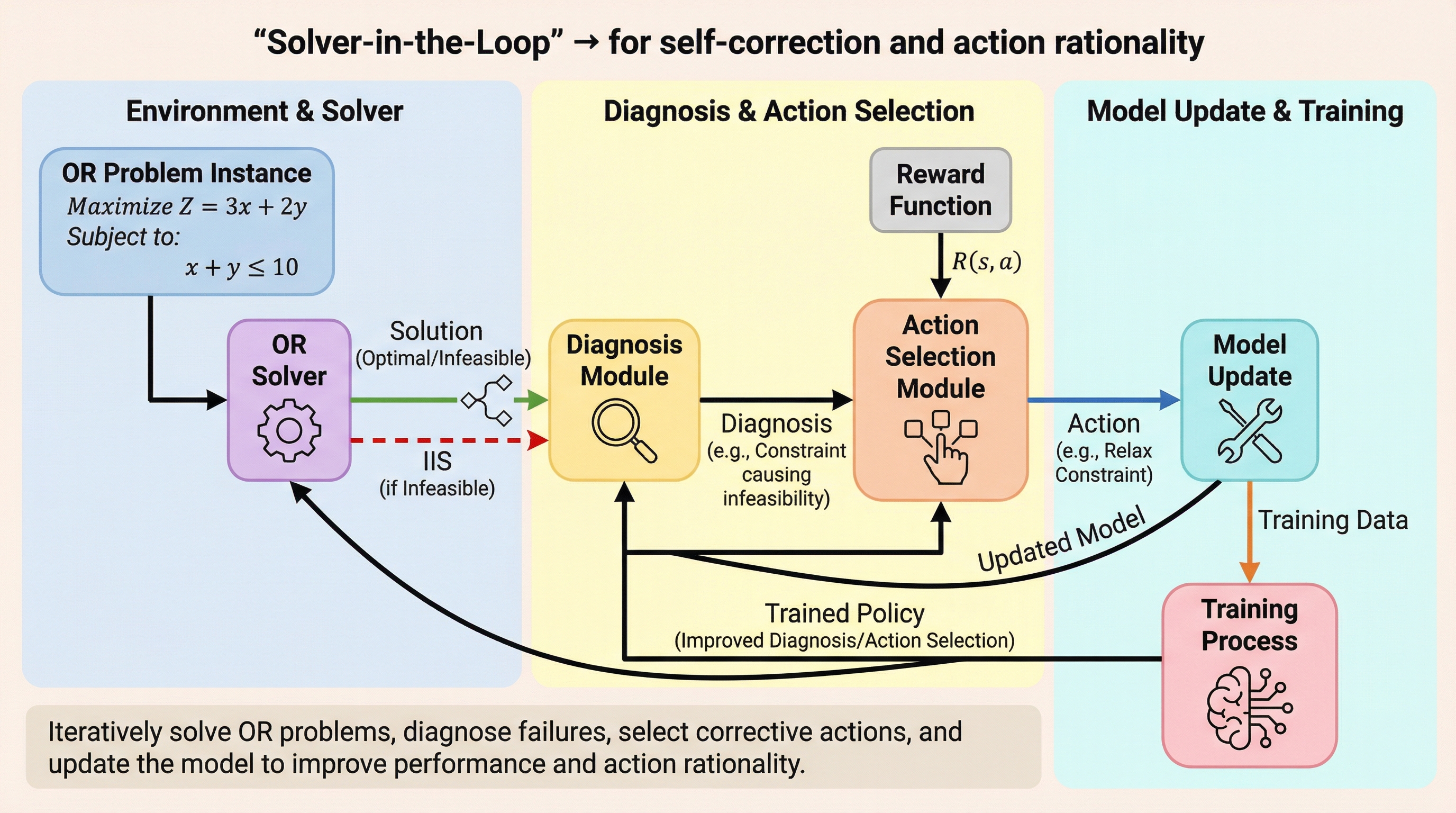
従来のLLM評価は数理最適化モデルの生成を単発の翻訳作業として扱っていたが、本研究はソルバーのフィードバックを用いた反復的な自己修正プロセスを評価する「OR-Debug-Bench」と、在庫管理における意思決定の偏りを測定する「OR-Bias-Bench」を提案した。
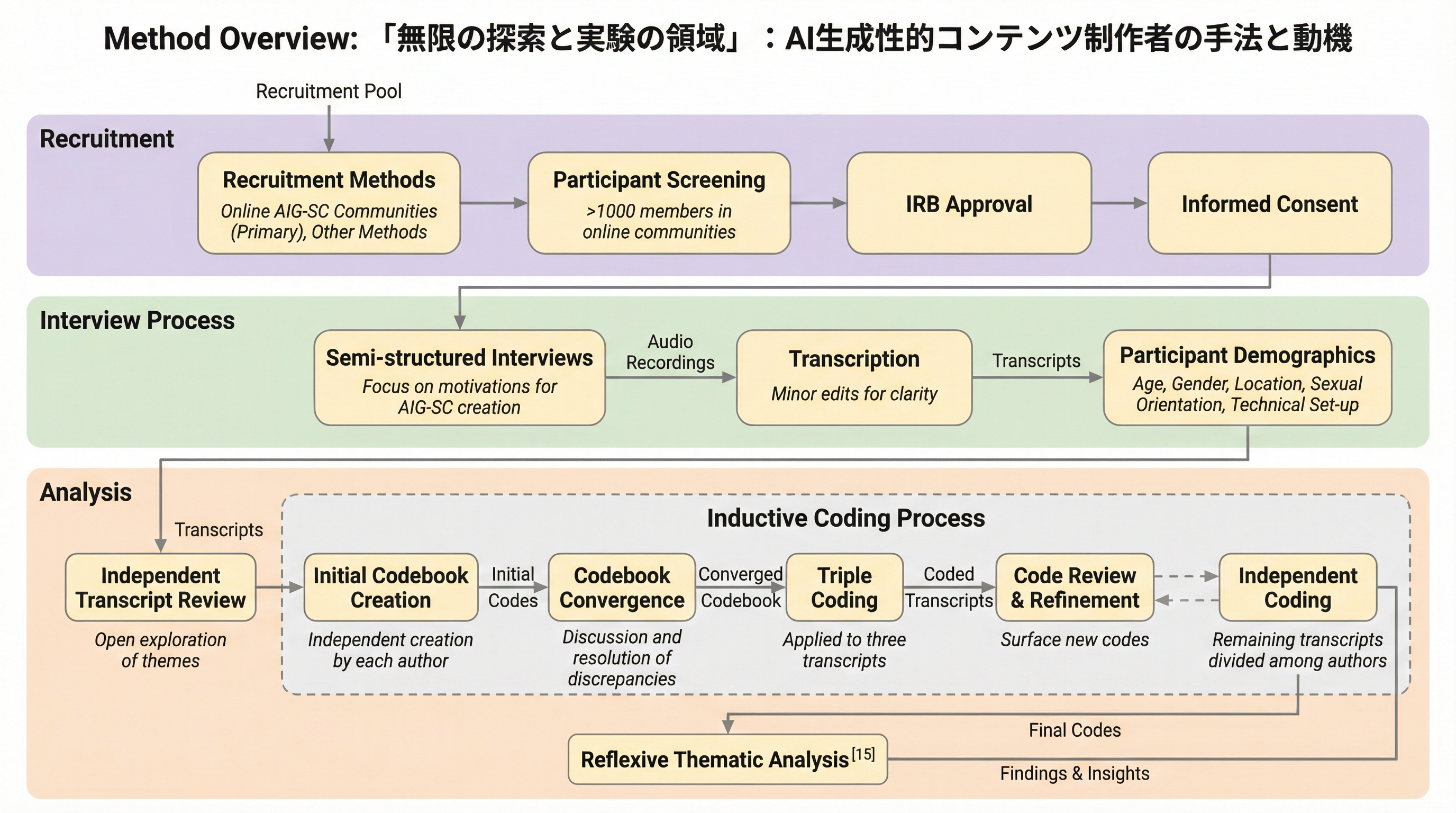
本研究は28名のAI生成性的コンテンツ(AIG-SC)制作者へのインタビューを通じ、彼らの背景、制作手法、および動機を明らかにした。制作者は技術職や芸術職、性産業従事者など多岐にわたり、独自のパイプラインやジェイルブレイクを用いてテキストや画像を生成している。
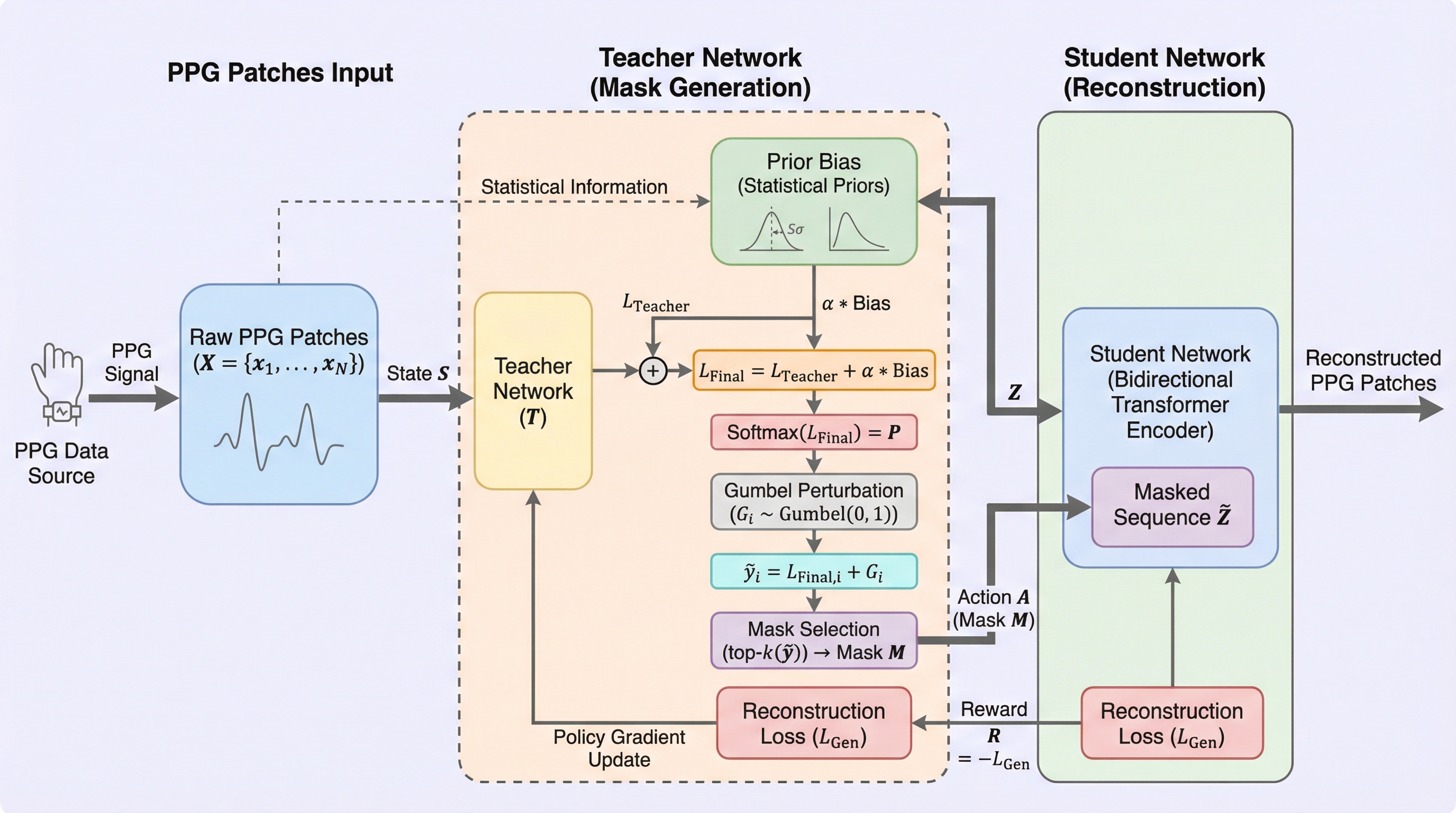
光電容積脈波(PPG)信号の解析において、従来のランダムマスキングが信号の周期性ゆえに容易に解けてしまう問題と、対照学習が微細な形態的特徴を軽視する課題を解決するため、統計的事前情報を導入した生成型基盤モデル「SIGMA-PPG」が提案されました。
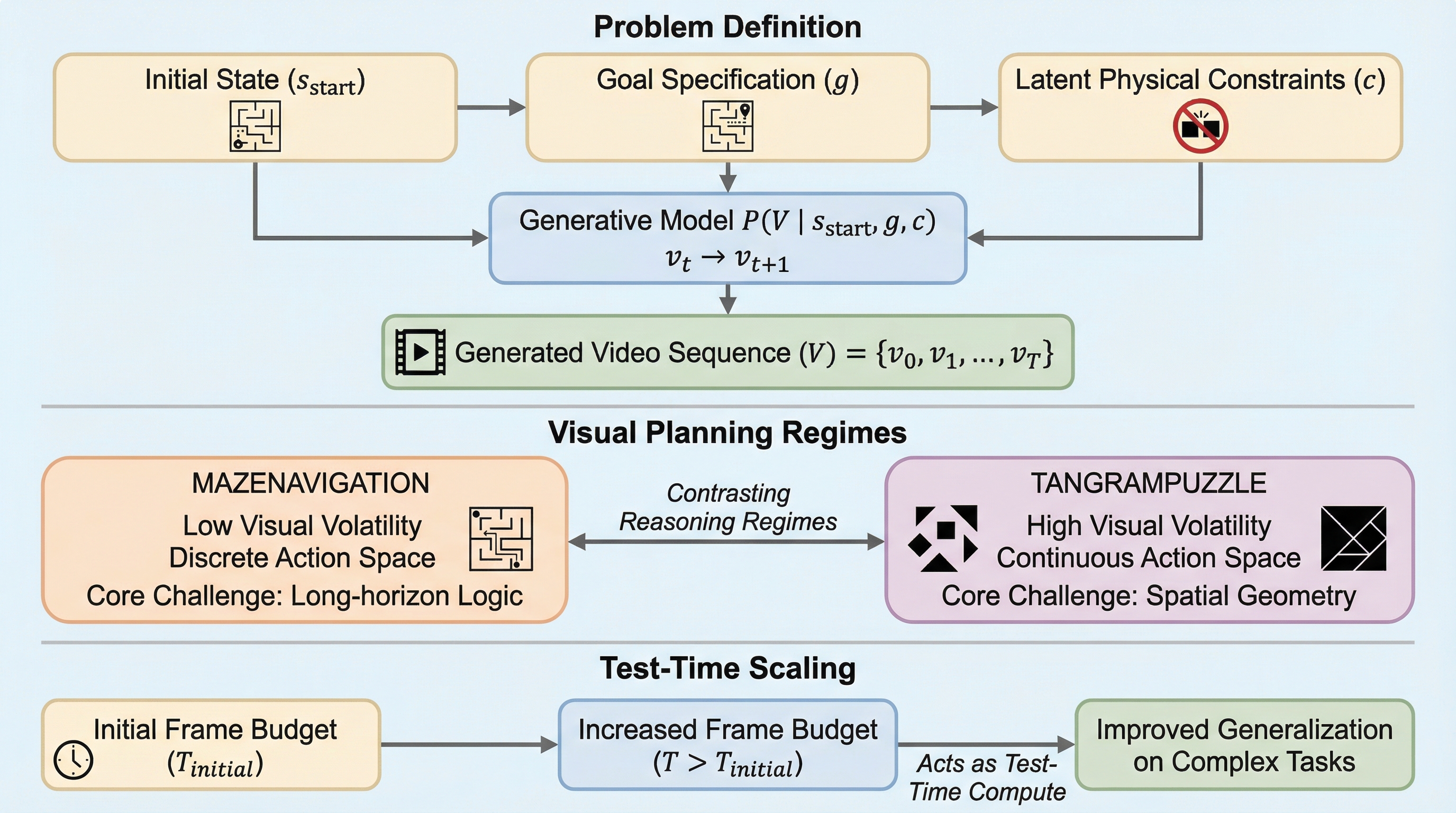
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。