ノイズはあるが有効:不完全な評価者によるLLMの堅牢な統計的評価
大規模言語モデル(LLM)の安全性を評価する「LLM-as-a-Judge」は、拡張性に優れる一方で評価者の誤りやバイアスが統計的信頼性を損なうという深刻な課題を抱えていたが、本研究は少量の人間によるラベル付きデータを用いて評価者の特性(真陽性率と偽陽性率)を精密に推定し、大規模な自動評価データセットに対して分散補正を適用する新しい統計的枠組み「Noisy but Valid」を提案することで、この問題を根本から解決した。 この枠組みは、評価者が不完全であっても、安全でないモデルを誤って合格させてしまう「第一種過誤」を理論的に有限サンプル内で厳密に制御することを保証しており、従来の人間による直接的な評価手法と比較して、評価者の品質が一定の基準を超えている場合には統計的な検出力を大幅に向上させることが可能であり、評価コストの劇的な削減と信頼性の向上を同時に達成している。 既存の予測駆動型推論(PPI)とは異なり、評価者のエラープロファイルを明示的にモデル化することで、評価プロセスの透明性と診断能力を確保しており、実務者が評価者の信頼性を客観的に判断し、データセットの規模や認定要件に応じた最適な評価プロトコルを設計するための理論的かつ実践的な基盤を提供している点が、本研究の最も重要な貢献である。
TL;DR(結論)
大規模言語モデル(LLM)の安全性を評価する「LLM-as-a-Judge」は、拡張性に優れる一方で評価者の誤りやバイアスが統計的信頼性を損なうという深刻な課題を抱えていたが、本研究は少量の人間によるラベル付きデータを用いて評価者の特性(真陽性率と偽陽性率)を精密に推定し、大規模な自動評価データセットに対して分散補正を適用する新しい統計的枠組み「Noisy but Valid」を提案することで、この問題を根本から解決した。 この枠組みは、評価者が不完全であっても、安全でないモデルを誤って合格させてしまう「第一種過誤」を理論的に有限サンプル内で厳密に制御することを保証しており、従来の人間による直接的な評価手法と比較して、評価者の品質が一定の基準を超えている場合には統計的な検出力を大幅に向上させることが可能であり、評価コストの劇的な削減と信頼性の向上を同時に達成している。 既存の予測駆動型推論(PPI)とは異なり、評価者のエラープロファイルを明示的にモデル化することで、評価プロセスの透明性と診断能力を確保しており、実務者が評価者の信頼性を客観的に判断し、データセットの規模や認定要件に応じた最適な評価プロトコルを設計するための理論的かつ実践的な基盤を提供している点が、本研究の最も重要な貢献である。
なぜこの問題か
大規模言語モデル(LLM)が仮想アシスタントや安全性が重視される意思決定支援ツールとして実社会の多様な場面に導入される中で、その出力が十分に正確で安全であるかを統計的な確信を持って判断することが不可欠となっている。しかし、LLMの信頼性を評価することは、特に自由形式の回答やリスクの高い文脈において非常に困難な課題である。現在、主に二つのアプローチが取られているが、それぞれに重大な限界が存在している。一つは公開されているリーダーボードやテストセットを用いた経験的な失敗率の測定であるが、これらはデータの汚染やラベルのノイズ、特定のデータへの過学習によって結果が歪められる可能性がある。もう一つは人間による評価であり、これは品質と安全性を評価するための「ゴールドスタンダード」と見なされているが、コストと時間が膨大にかかり、統計的に信頼できる結論を導き出すために必要なサンプルサイズを確保することが現実的に難しい。…
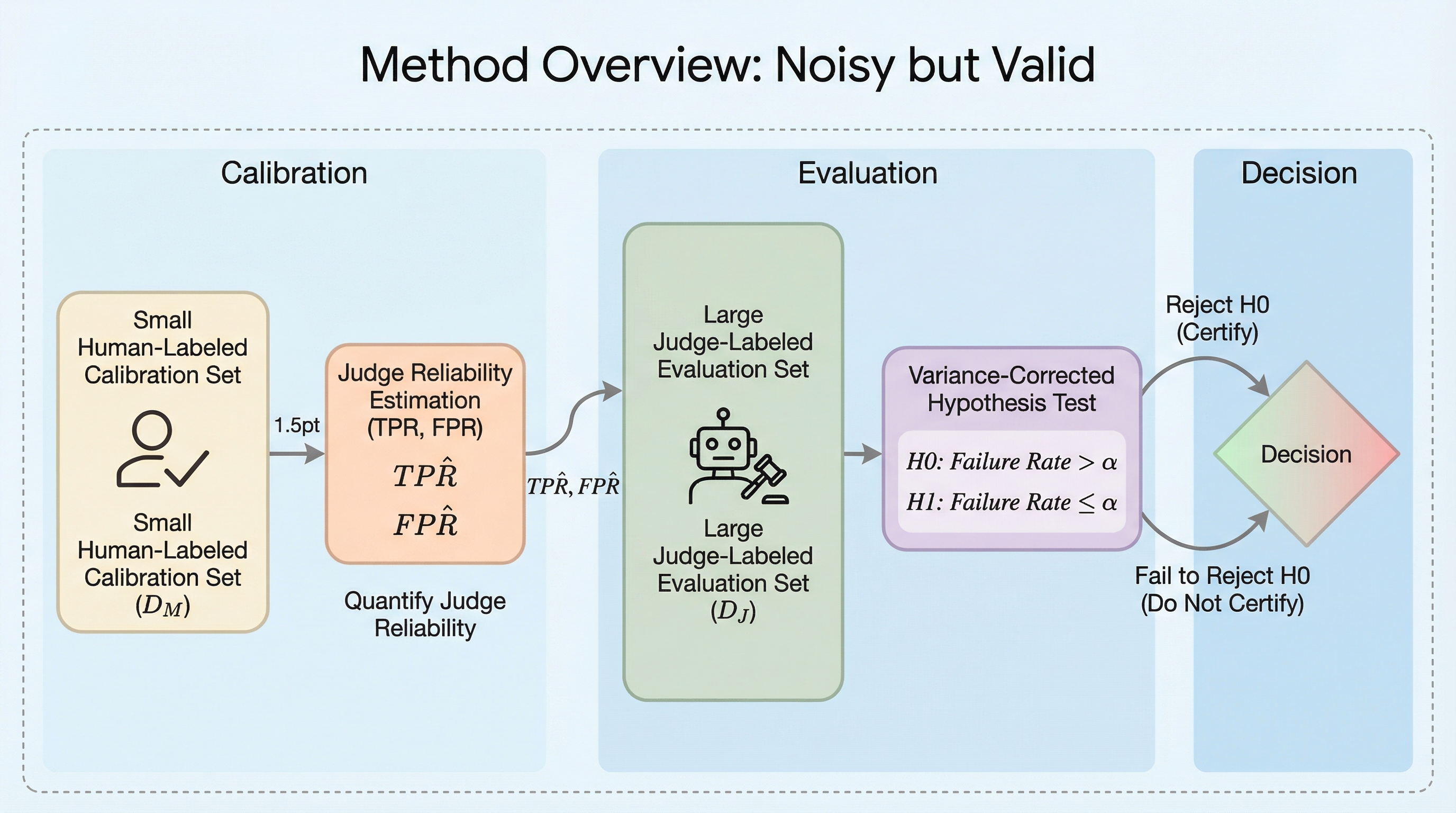
核心:何を提案したのか
本研究の核心は、不完全な評価者を利用しながらも統計的な厳密さを維持する「Noisy but Valid」という仮説検定の枠組みを提案したことにある。この枠組みでは、モデルの信頼性評価を統計的な仮説検定として定式化している。具体的には、「LLMの失敗率がユーザーの指定した許容範囲を超えている」という帰無仮説を設定し、この仮説を棄却することでモデルが安全であることを統計的に保証する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related