Solver-in-the-Loop: オペレーションズ・リサーチにおける自己修正と行動合理性のためのMDPベースのベンチマーク
従来のLLM評価は数理最適化モデルの生成を単発の翻訳作業として扱っていたが、本研究はソルバーのフィードバックを用いた反復的な自己修正プロセスを評価する「OR-Debug-Bench」と、在庫管理における意思決定の偏りを測定する「OR-Bias-Bench」を提案した。
TL;DR(結論)
従来のLLM評価は数理最適化モデルの生成を単発の翻訳作業として扱っていたが、本研究はソルバーのフィードバックを用いた反復的な自己修正プロセスを評価する「OR-Debug-Bench」と、在庫管理における意思決定の偏りを測定する「OR-Bias-Bench」を提案した。これにより、実務で不可欠なデバッグ能力と行動合理性を定量化することが可能になった。 5,000件以上のデバッグ課題と2,000件の在庫管理事例を含むベンチマークにおいて、特定の領域に特化した強化学習(GRPO)を適用した8Bパラメータの小規模モデルが、最新の巨大な商用APIモデルを上回る95.3%の修復成功率と高い診断精度を達成した。これは、モデルの規模よりも検証可能なフィードバックを用いた学習が重要であることを示している。 カリキュラム学習の導入により、未知のデータに対しても在庫発注の体系的なバイアスを48%削減することに成功し、モデルが単なるパターンの暗記ではなく、合理的な意思決定のルールを学習したことが確認された。この「Solver-in-the-Loop」アプローチは、AIが複雑な数理的問題を解決する際の信頼性と効率性を飛躍的に高める新たな標準となる。
なぜこの問題か
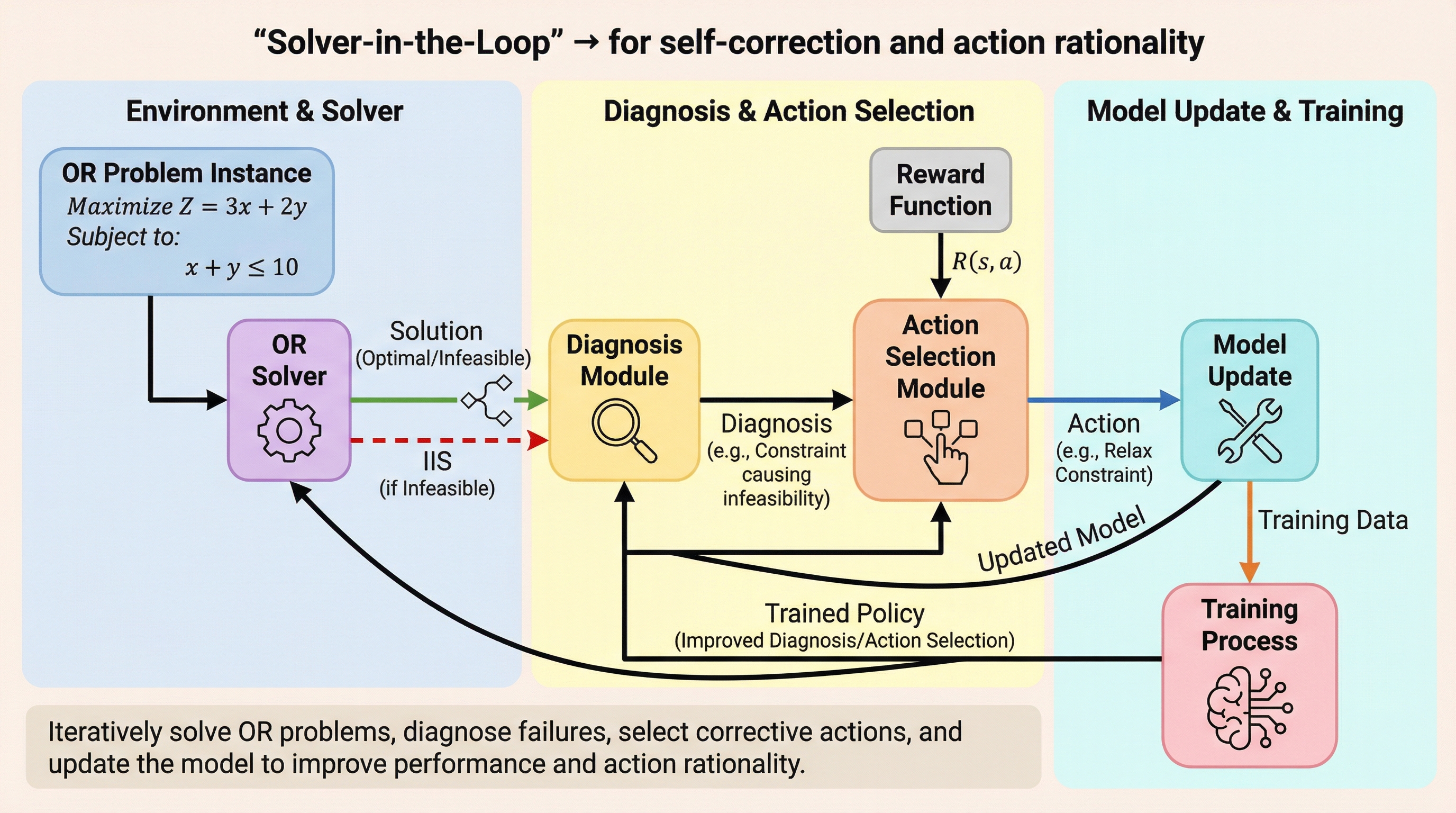
オペレーションズ・リサーチ(OR)の実務において、数理モデルが「実行不可能」と判定された際のデバッグ作業は、モデル構築そのものと同等以上に重要なプロセスである。実務家はソルバーから返される「既約実行不能サブシステム(IIS)」と呼ばれる、同時に満たすことができない最小限の制約の矛盾セットを分析し、原因を特定して定式化を修正する作業を繰り返す。しかし、既存のLLMベンチマークの多くは、問題文からソルバー用のコードを生成する「単発の翻訳」としての評価に終始しており、この診断と修正のループを完全に無視していた。先行研究によれば、LLMの誤りの64.5%は自己修正の失敗に起因するとされているが、既存の修正評価用データセットは一般的なプログラミングタスクに偏っており、構造化されたフィードバックが得られるOR領域は未開拓であった。 また、上流のモデル構築だけでなく、下流の意思決定フェーズにおいても深刻な課題が存在する。在庫管理などの運用上の意思決定において、LLMは「プル・トゥ・センター(中央への引き寄せ)」と呼ばれる体系的な行動バイアスを示すことが指摘されている。…
核心:何を提案したのか
本研究の核心は、ソルバーを評価ループに直接組み込んだ2つの新しいベンチマークと、それに基づいた強化学習フレームワークの提案にある。第一のベンチマークである「OR-Debug-Bench」は、5,000件以上の問題と9種類の異なるエラータイプを含み、エージェントがソルバーからのIISフィードバックを受け取りながら反復的にコードを修正する能力を測定する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related