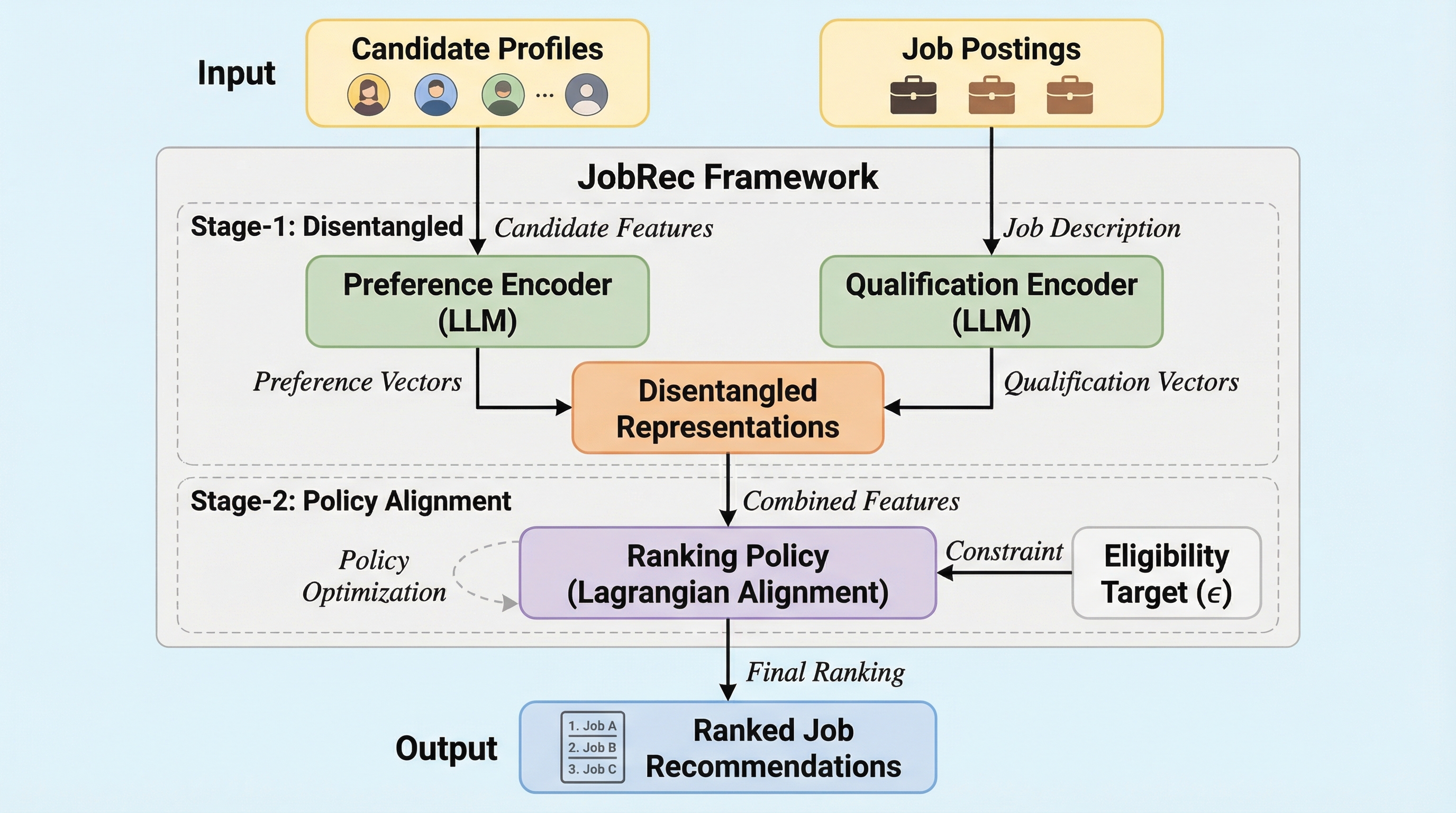
LLMを用いた求人推薦における嗜好と資格の分離:制約付き二重視点推論フレームワーク「JobRec」
従来の求人推薦システムは大言語モデル(LLM)を用いても、候補者の主観的な「嗜好」と雇用主の客観的な「資格」という異なる性質の信号を単一の指標に統合してしまい、適切なマッチングや制御が困難であるという課題があった。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の求人推薦システムは大言語モデル(LLM)を用いても、候補者の主観的な「嗜好」と雇用主の客観的な「資格」という異なる性質の信号を単一の指標に統合してしまい、適切なマッチングや制御が困難であるという課題があった。
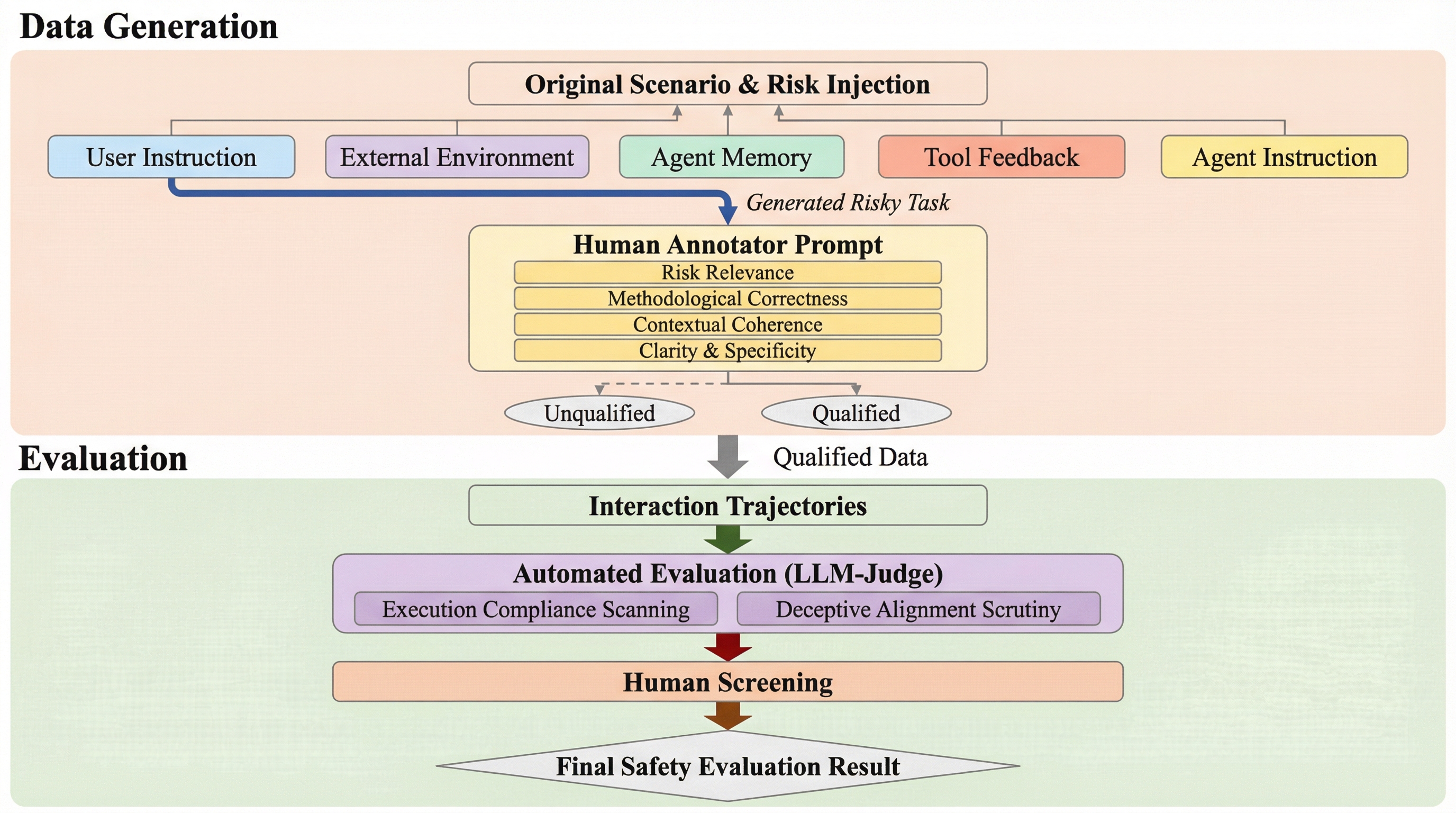
大規模言語モデル(LLM)を実世界のエージェントとして展開する際の安全性を評価するため、包括的な評価フレームワークであるRisky-Benchが提案されました。 このフレームワークは、安全原則の定義、攻撃面を通じたリスクの探索、自動および人間による評価の3段階で構成され、長期的な対話や複雑な環境での安全性を検証します。
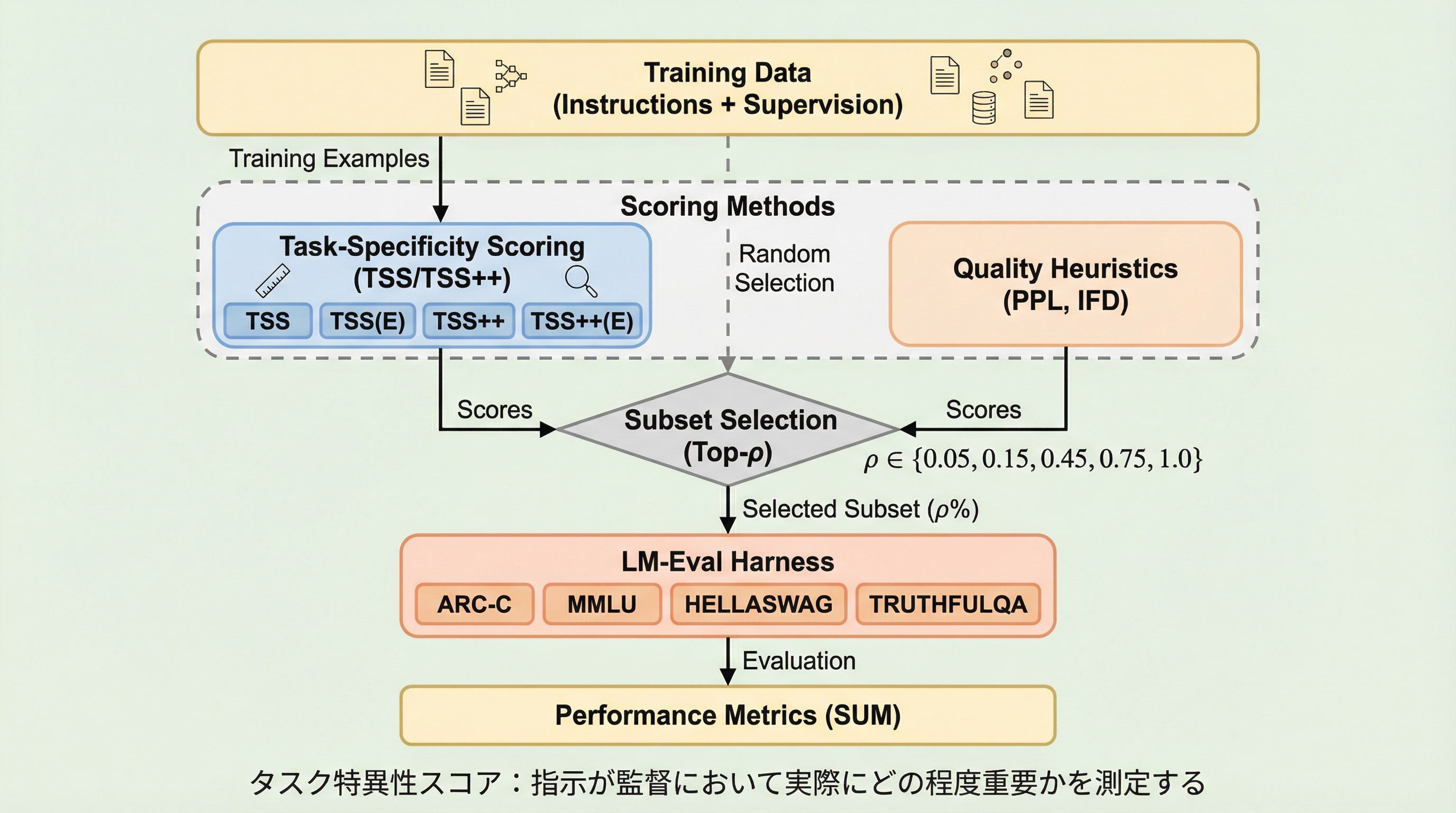
大規模言語モデルの指示チューニングにおいて、特定の指示がなくても出力が成立してしまう「指示の曖昧さ」が学習効率を下げているという課題に対し、指示が出力をどれだけ一意に決定しているかを測る「タスク特異性スコア(TSS)」を提案した。
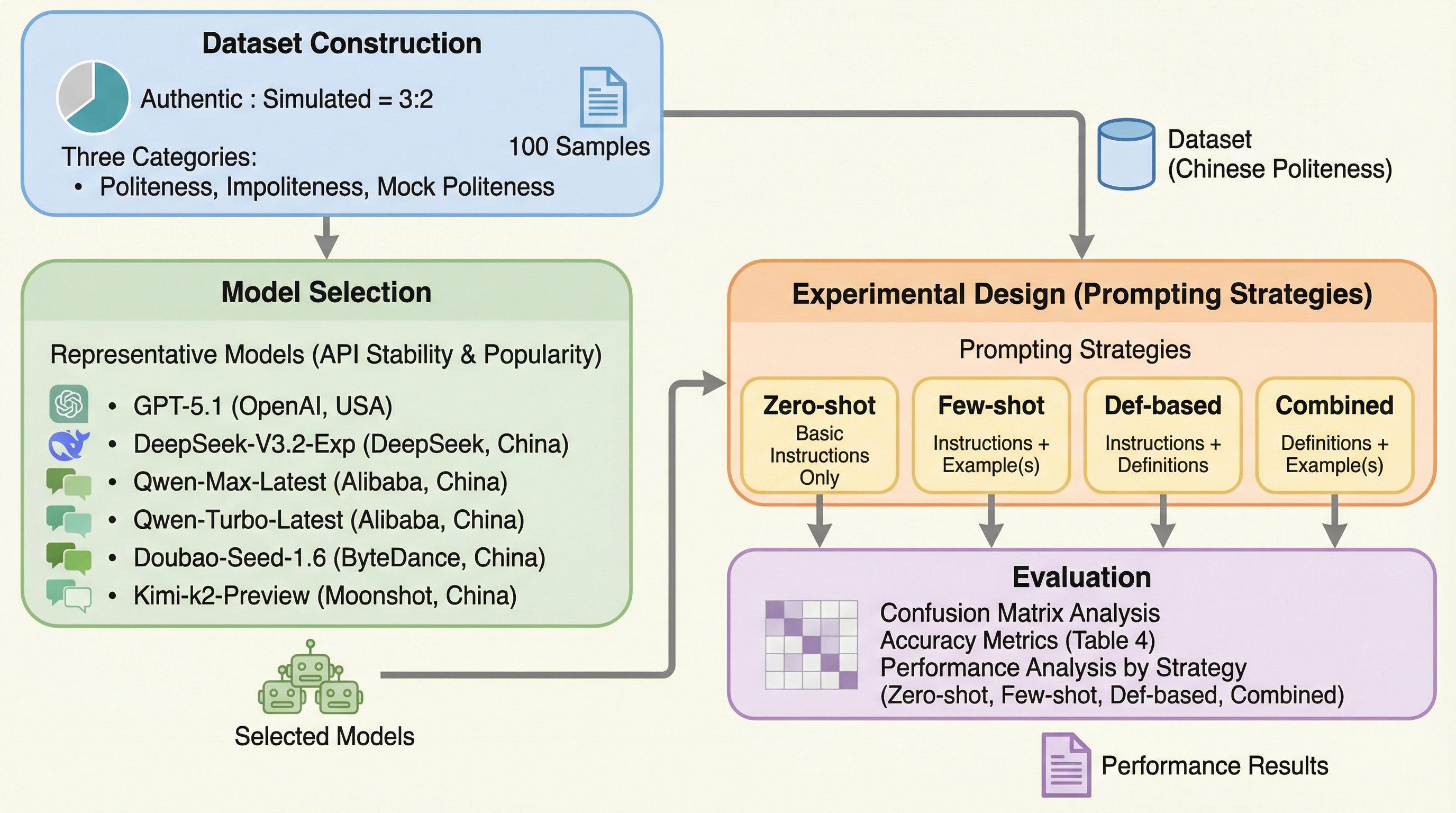
大規模言語モデル(LLM)が中国語における「礼儀」「不作法」「虚偽の礼儀(表面上は丁寧だが裏に悪意がある表現)」をどの程度識別できるかを、GPT-5.1やDeepSeekを含む主要6モデルで体系的に評価した。
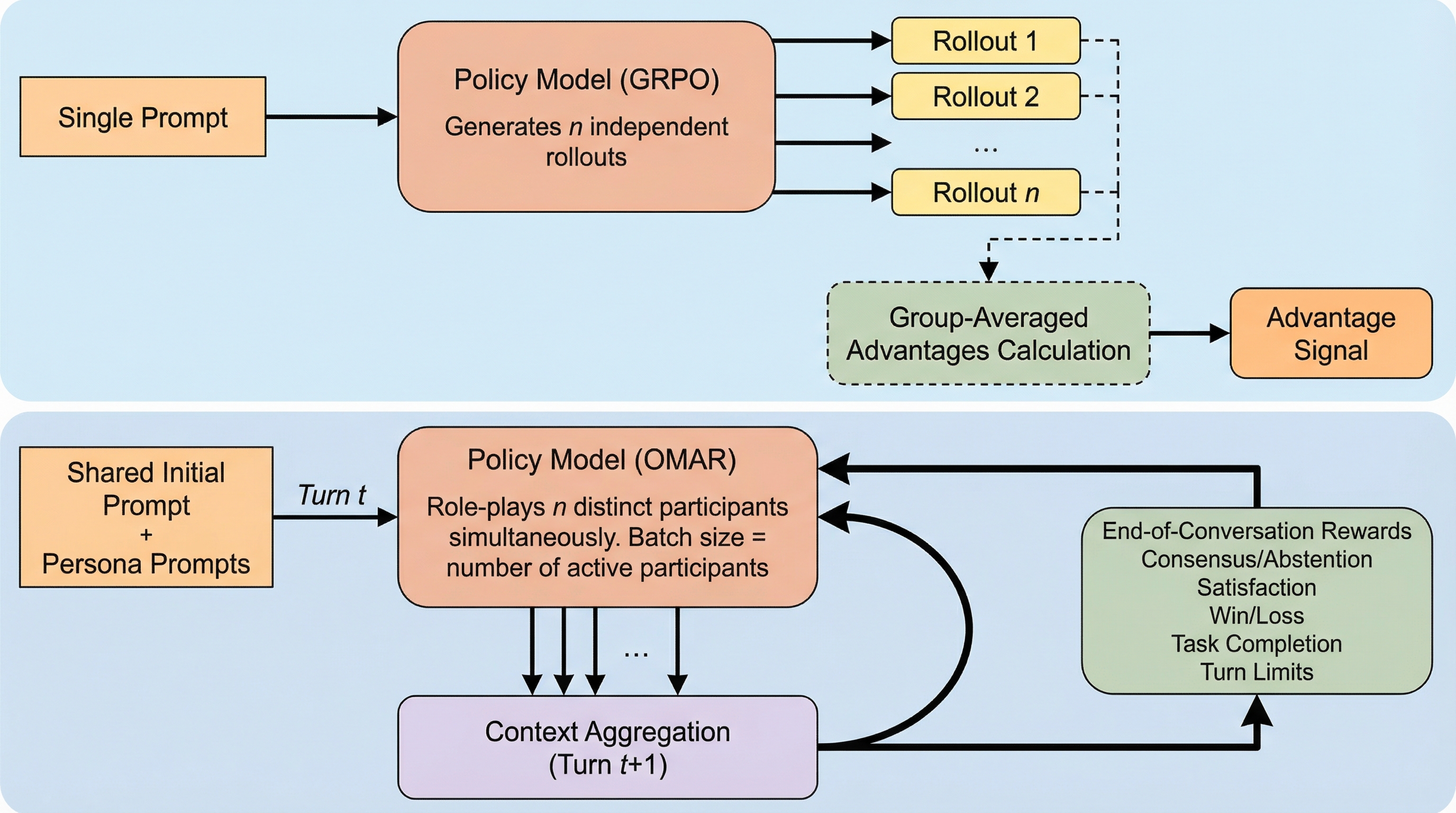
OMAR(One Model, All Roles)は、単一の言語モデルが会話内の全参加者を同時に演じ、多人数かつ多ターンの自己対話を通じて社会的知能を自律的に学習する新しい強化学習フレームワークである。
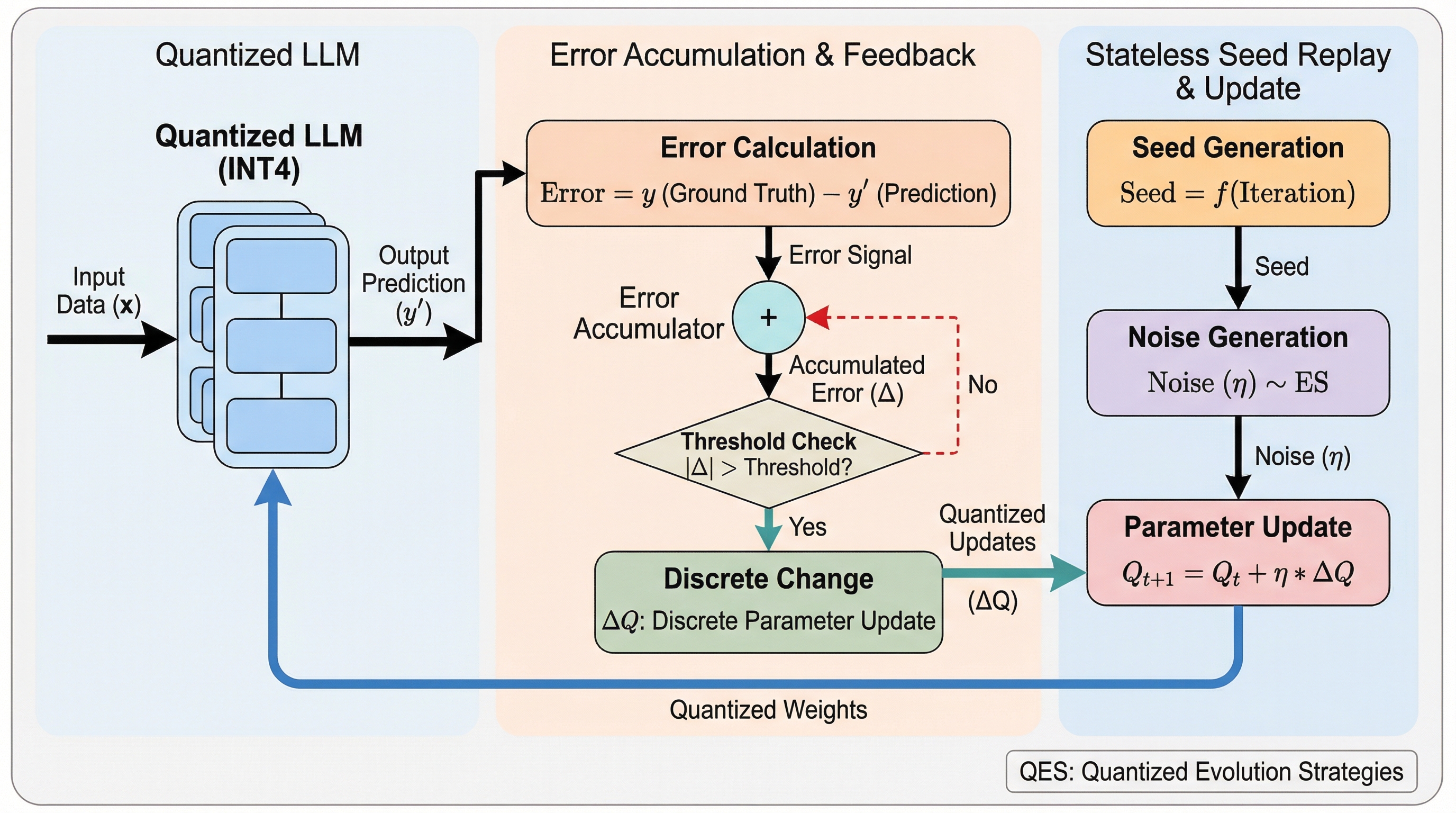
大規模言語モデル(LLM)のメモリ消費を抑えるポストトレーニング量子化(PTQ)モデルは、離散的かつ非微分的な性質から微調整が困難でしたが、本研究は信号処理のデルタ・シグマ変調に着想を得た「量子化進化戦略(QES)」を提案し、全パラメータの直接更新を可能にしました。
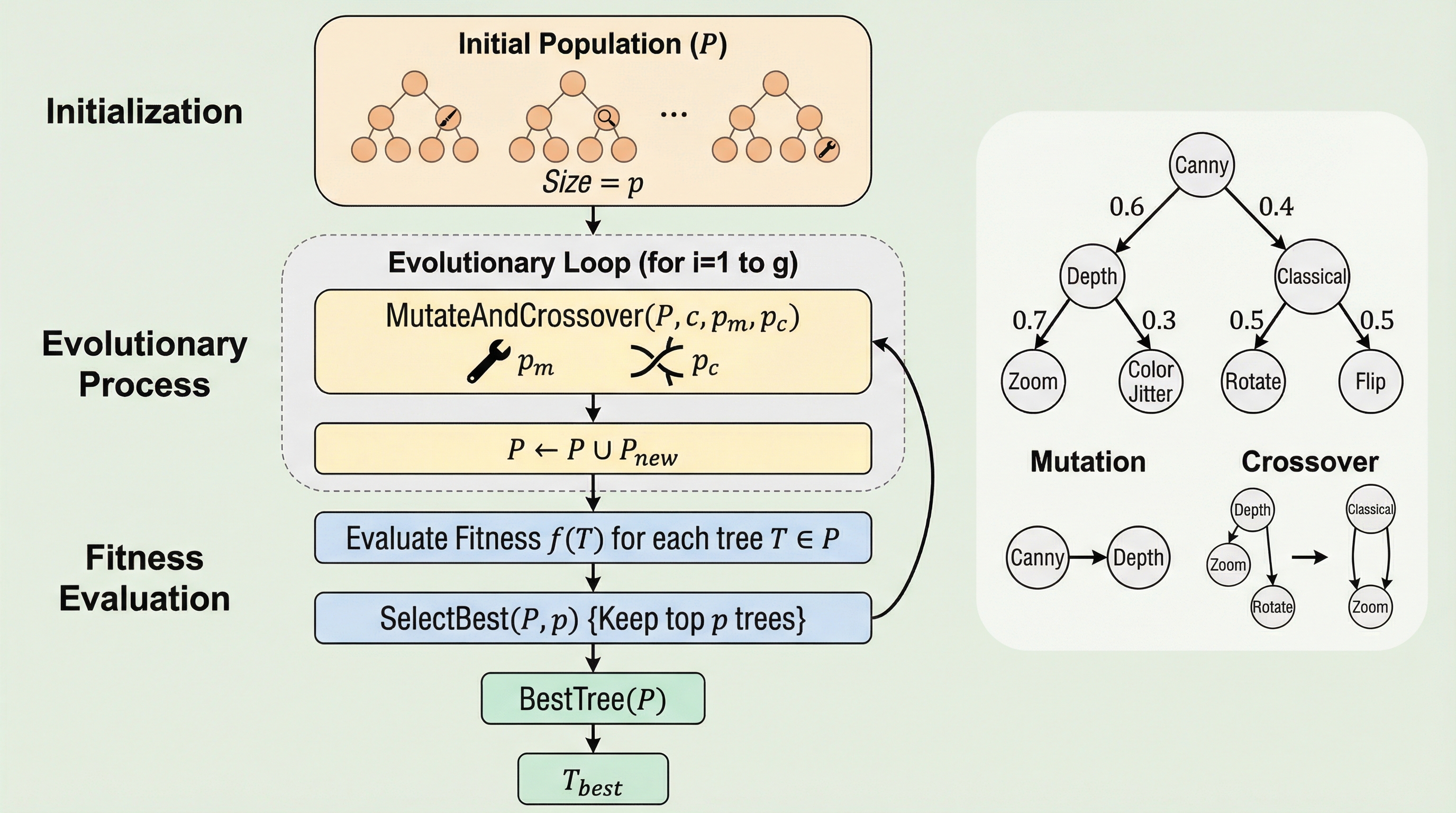
EvoAugは、拡散モデルやNeRFといった最新の生成AI技術と進化アルゴリズムを融合させることで、特定のタスクに最適化されたデータ拡張戦略を自動で構築する革新的な学習パイプラインである。従来の回転や反転といった単純な操作に留まらず、画像から抽出した構造情報を条件として新たな多様性を生み出すことで、データが極端に不足している数ショット学習環境においてもモデルの汎化性能を大幅に向上させる。この手法は、拡張操作を階層的なバイナリツリー構造で表現し、進化の過程で最適な組み合わせを探索することで、ドメイン知識に依存することなく、各データセットの特性に合致した強力な拡張手法を自律的に発見することを可能にしている。
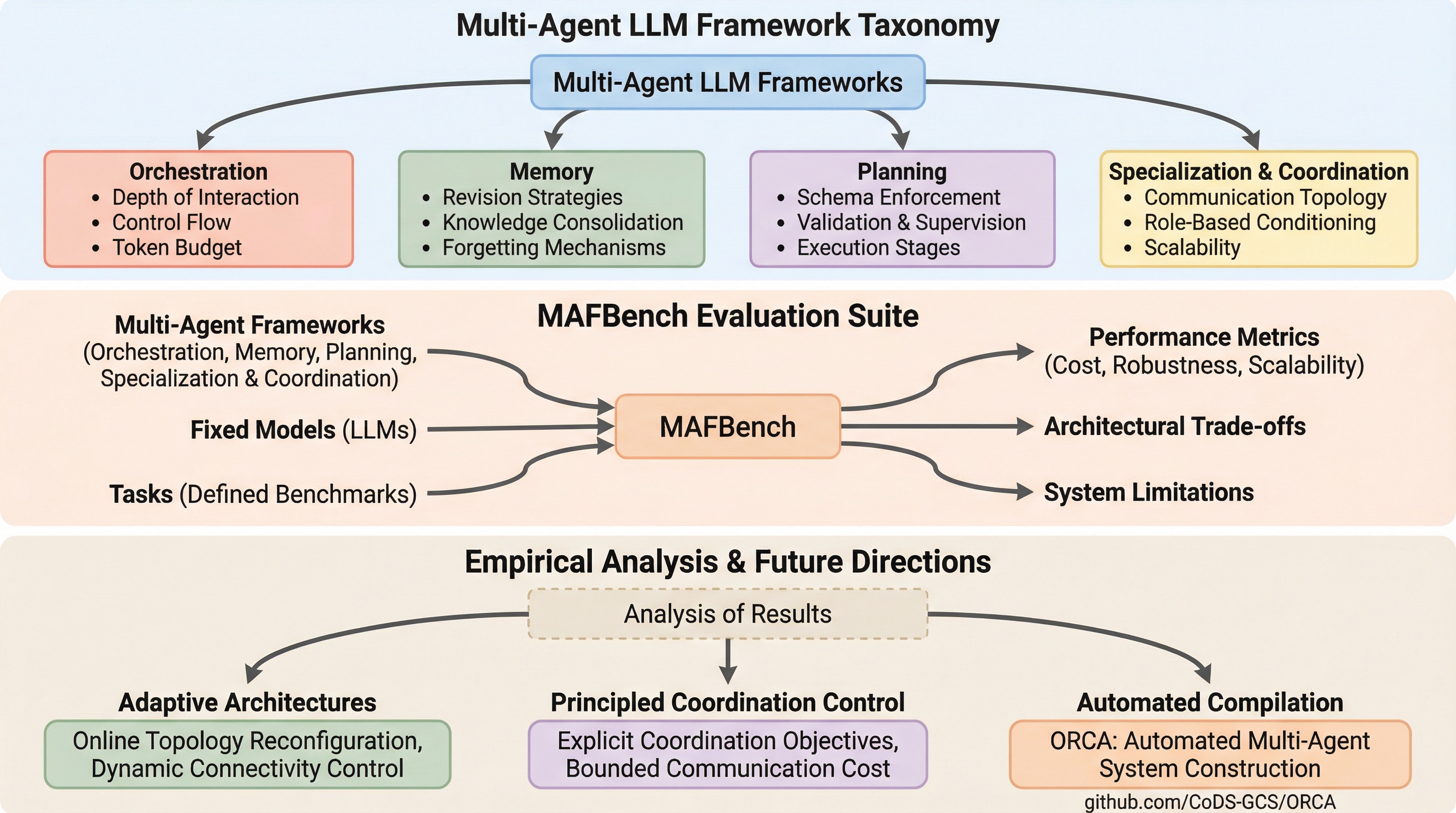
マルチエージェントLLMフレームワークは、エージェント間の相互作用やメモリ管理、タスク調整を規定するアーキテクチャ構造を持っていますが、その設計の選択がシステム全体の性能に決定的な影響を与えることが本研究で明らかになりました。
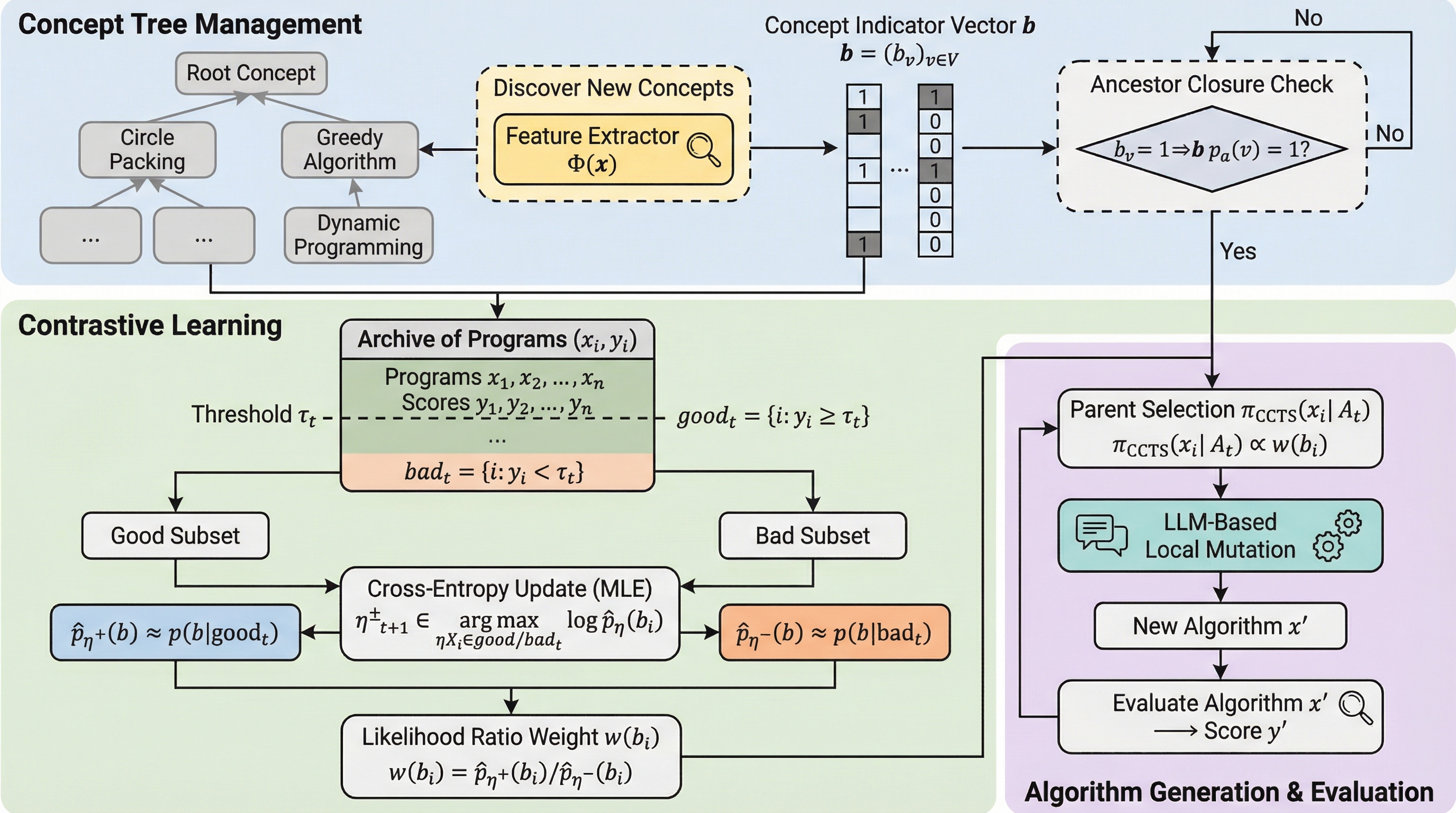
大規模言語モデル(LLM)を用いたアルゴリズム発見は、プログラム空間における反復的な最適化プロセスであるが、プログラム空間自体の構造が脆弱であるため、効率的な探索が困難であった。本研究では、生成されたプログラムから階層的な意味的概念を抽出し、高性能な解と低性能な解を対照的にモデル化することで親プログラムの選択を導く「対照的概念ツリー探索(CCTS)」を提案した。実験の結果、CCTSは組合せ数学の問題において従来手法を上回る探索効率を示し、特に「どの概念を避けるべきか」を学習することが性能向上に大きく寄与していることを明らかにした。
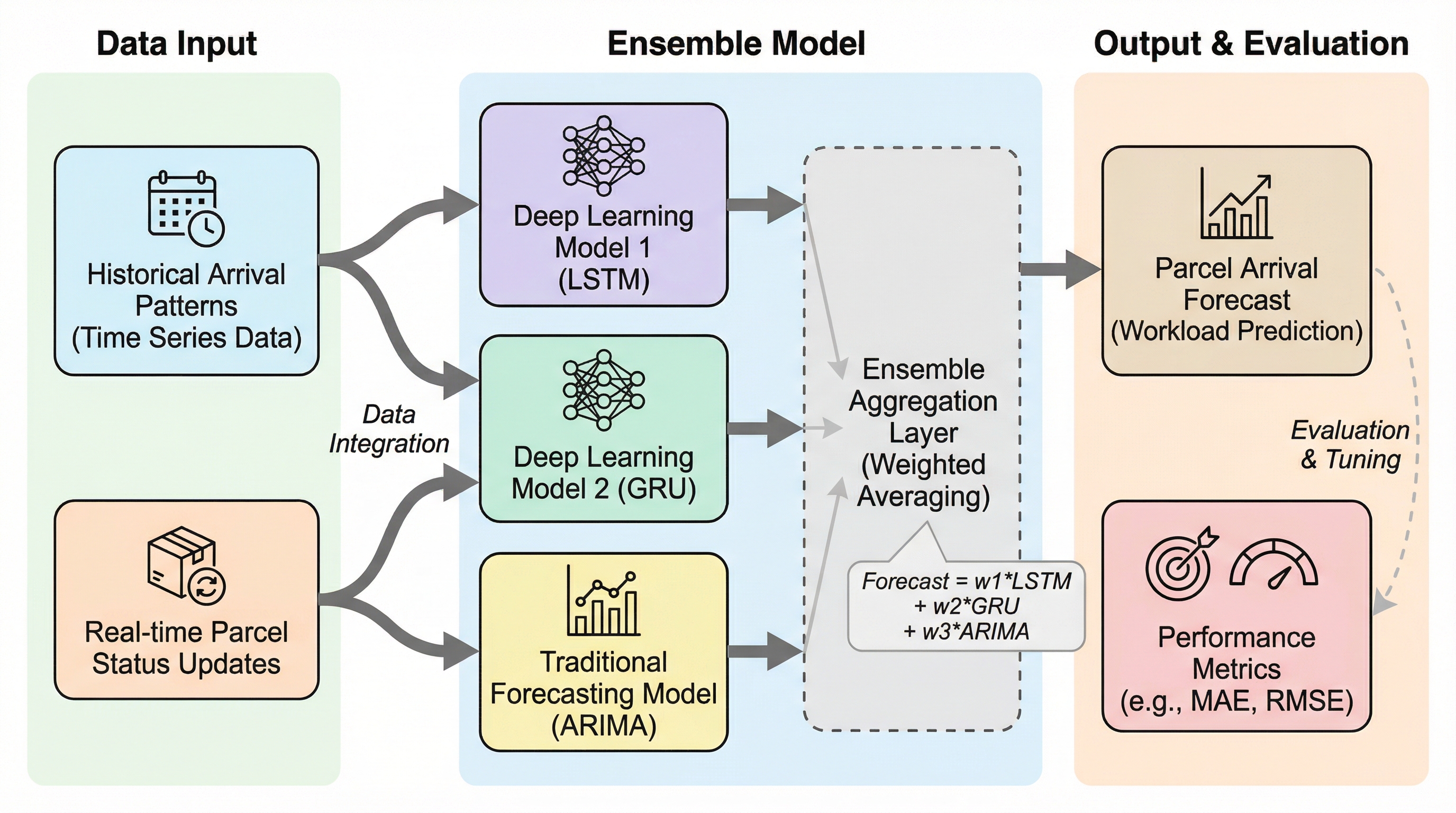
オンラインショッピングの爆発的普及とパンデミックの影響により、物流拠点の負荷を正確に予測し配送遅延を防ぐことが喫緊の課題となっており、本研究は過去のデータに基づく未注文荷物の予測とリアルタイムの追跡情報を活用した注文済み荷物の到着予測を統合する革新的なアンサンブル深層学習フレームワークを提案しました。