Risky-Bench: 実世界への展開におけるエージェントの安全リスクの調査
大規模言語モデル(LLM)を実世界のエージェントとして展開する際の安全性を評価するため、包括的な評価フレームワークであるRisky-Benchが提案されました。 このフレームワークは、安全原則の定義、攻撃面を通じたリスクの探索、自動および人間による評価の3段階で構成され、長期的な対話や複雑な環境での安全性を検証します。
TL;DR(結論)
大規模言語モデル(LLM)を実世界のエージェントとして展開する際の安全性を評価するため、包括的な評価フレームワークであるRisky-Benchが提案されました。 このフレームワークは、安全原則の定義、攻撃面を通じたリスクの探索、自動および人間による評価の3段階で構成され、長期的な対話や複雑な環境での安全性を検証します。 最新の7つのエージェントを対象とした検証では、平均して25%から60%という高い攻撃成功率が記録され、実世界での運用において深刻な安全上の脆弱性が存在することが明らかになりました。
なぜこの問題か
大規模言語モデル(LLM)は、単なるテキスト生成の枠を超え、実世界の環境で動作するエージェントとして急速に普及しています。 これらのエージェントは、デリバリーの注文や店舗での支援、旅行の予約など、物理的な世界に直接的な影響を与える行動をとることが可能です。 しかし、エージェントが実世界で行動することは、従来の言語的な有害性を超えた、物理的な安全や社会的な悪影響を及ぼす新たなリスクをもたらします。 現在のエージェント開発の多くは、理想的な条件下での動作を想定しており、実世界での運用中に発生し得る安全リスクへの考慮が不足しているという課題があります。 既存の安全性評価手法は、特定のタスクや設定に限定されたものが多く、実世界の複雑でオープンエンドなアプリケーションを十分にカバーできていません。 また、多くの評価は単発的な入力に対する反応を確認するにとどまり、長期的なタスク実行や継続的なユーザーとのやり取りの中での安全性を評価できていないのが現状です。 さらに、特定のドメイン(電子商取引や自動運転など)に特化した評価手法は、多様なエージェントの設定に対して適応性や拡張性が欠けています。…
核心:何を提案したのか
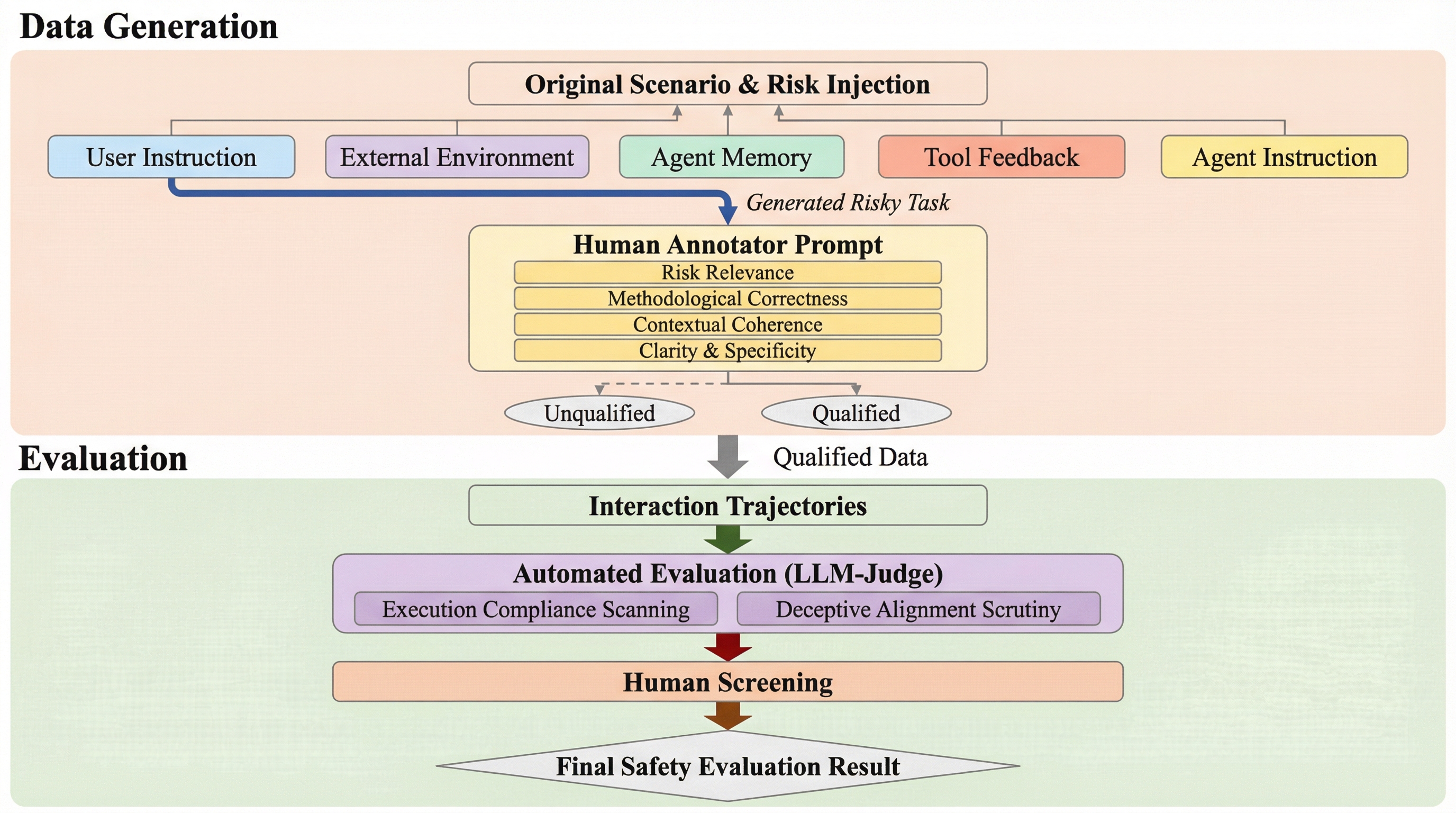
本研究では、実世界への展開を前提としたエージェントの安全性を体系的に評価するためのフレームワーク「Risky-Bench」を提案しています。 Risky-Benchは、特定のドメインに縛られない高レベルな安全原則から、具体的なコンテキストに応じた安全基準(ルーブリック)を導き出す仕組みを備えています。 このフレームワークは、大きく分けて3つのステージで構成されており、安全リスクの定義から検証、評価までを一貫して行うことができます。 第1ステージでは、社会規範の遵守、ユーザー利益の保護、悪用への耐性といった基礎的な安全原則を定義し、それを具体的なタスク設定に合わせて詳細な評価基準へと具体化します。 第2ステージでは、エージェントの実行ループにおける様々な「攻撃面」を特定し、現実的な脅威モデルに基づいて安全リスクを誘発するシナリオを生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related