LLMを用いた求人推薦における嗜好と資格の分離:制約付き二重視点推論フレームワーク「JobRec」
従来の求人推薦システムは大言語モデル(LLM)を用いても、候補者の主観的な「嗜好」と雇用主の客観的な「資格」という異なる性質の信号を単一の指標に統合してしまい、適切なマッチングや制御が困難であるという課題があった。
TL;DR(結論)
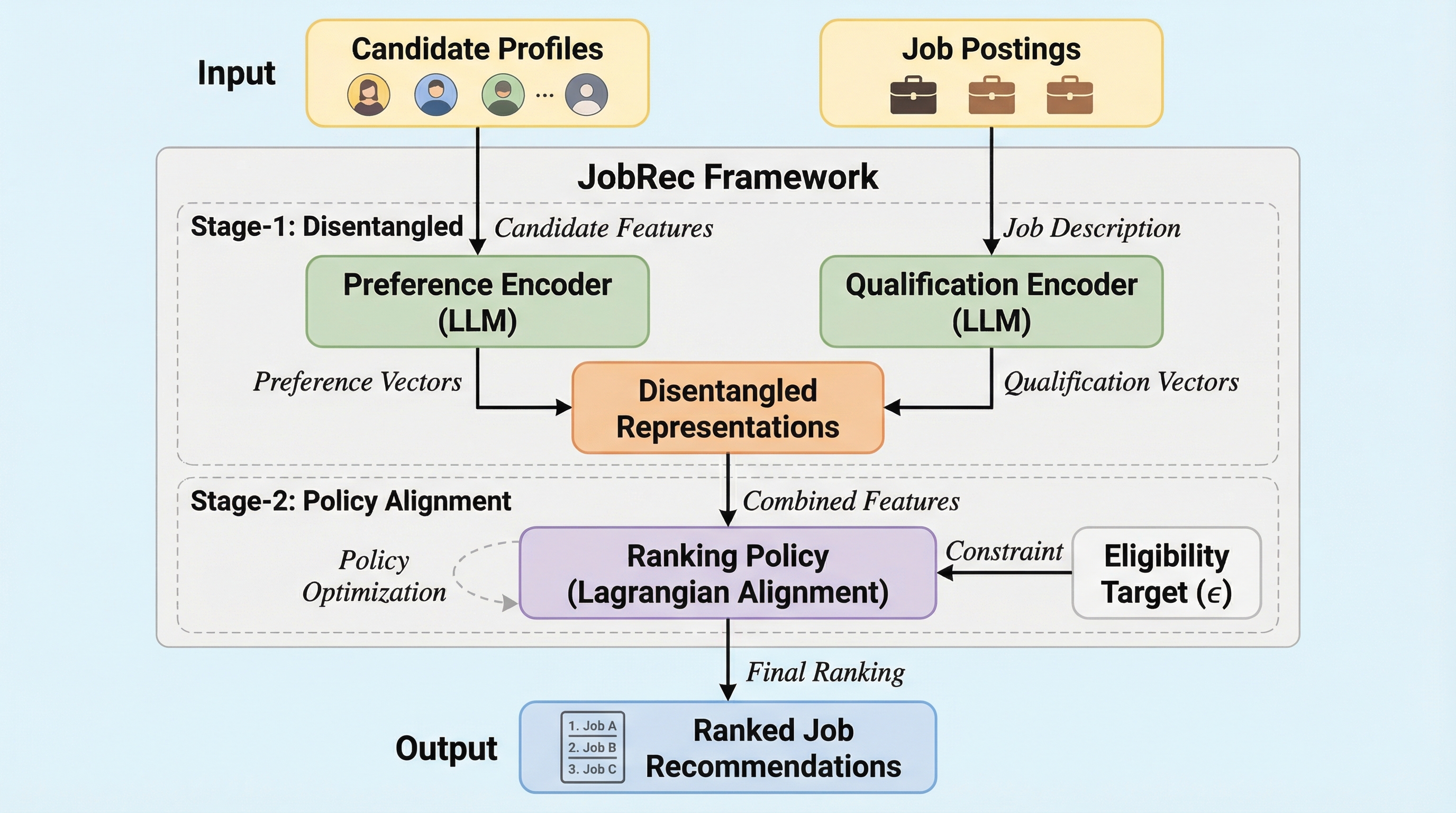
従来の求人推薦システムは大言語モデル(LLM)を用いても、候補者の主観的な「嗜好」と雇用主の客観的な「資格」という異なる性質の信号を単一の指標に統合してしまい、適切なマッチングや制御が困難であるという課題があった。本研究が提案する「JobRec」は、情報を4つの層に整理する統一セマンティックアライメントスキーマ(USAS)と、嗜好と資格を個別に推論する専門家モデルを学習する二段階協調トレーニング戦略により、これら二つの視点を明確に分離して扱う。ラグランジュ未定乗数法に基づく方策アライメントを導入することで、候補者の関心を最大化しつつ雇用主の資格要件を厳格に満たす制御可能な推薦を実現し、既存のLLM手法や深層学習モデルを大幅に上回る性能を実証した。
なぜこの問題か
オンライン採用プラットフォームにおける求人推薦は、候補者と雇用主の間の複雑な二部マッチングプロセスであり、候補者の主観的な嗜好と雇用主の客観的な資格要件を調和させる必要がある。しかし、既存の大言語モデル(LLM)を用いた手法の多くは、これらの異なる意思決定次元を「マッチ」や「採用」といった単一の相互作用信号に集約してしまっている。このような信号の混同は、採用プロセスの各段階で発生するデータの欠落や検閲の影響を受けやすく、モデルが候補者の熱意と実際の適格性を混同する原因となる。例えば、候補者が非常に興味を持っているが資格を満たさない求人や、資格は十分だが候補者が全く関心を持たない求人が推薦されるといった問題が生じる。また、負の結果が「露出不足」「無関心」「選考落ち」「辞退」のいずれに起因するかが不明確なため、学習における監視信号がノイズを含み、ロバストな学習を妨げている。 さらに、採用プロセスは「ファネル(漏斗)」構造を持っており、各段階で異なる意思決定者が関与する。候補者は自分のキャリアパスや興味に基づいて応募を決め、雇用主は履歴書に記載されたスキルや学歴に基づいて選考を行う。…
核心:何を提案したのか
本研究では、嗜好と資格を分離して扱う制約付き二重視点推論フレームワーク「JobRec」を提案している。このフレームワークの核心は、候補者の意思決定と雇用主の選考プロセスを明示的に切り離し、それらを制御可能な方策レイヤーで統合することにある。まず、候補者と求人の属性を対称的に整理するための「統一セマンティックアライメントスキーマ(USAS)」を導入し、情報を4つの階層的なセマンティックレイヤーに構造化する。これにより、履歴書のような非構造的なテキストデータと、学歴やGPAのような構造的なデータを、LLMが理解しやすい形式で整列させることが可能になる。 次に、このスキーマに基づき、嗜好と資格を個別に推論するデカップリングされた専門家モデルを学習する「二段階協調トレーニング戦略」を採用している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related