マルチエージェントLLMフレームワークの理解:統一ベンチマークと実験的分析
マルチエージェントLLMフレームワークは、エージェント間の相互作用やメモリ管理、タスク調整を規定するアーキテクチャ構造を持っていますが、その設計の選択がシステム全体の性能に決定的な影響を与えることが本研究で明らかになりました。
TL;DR(結論)
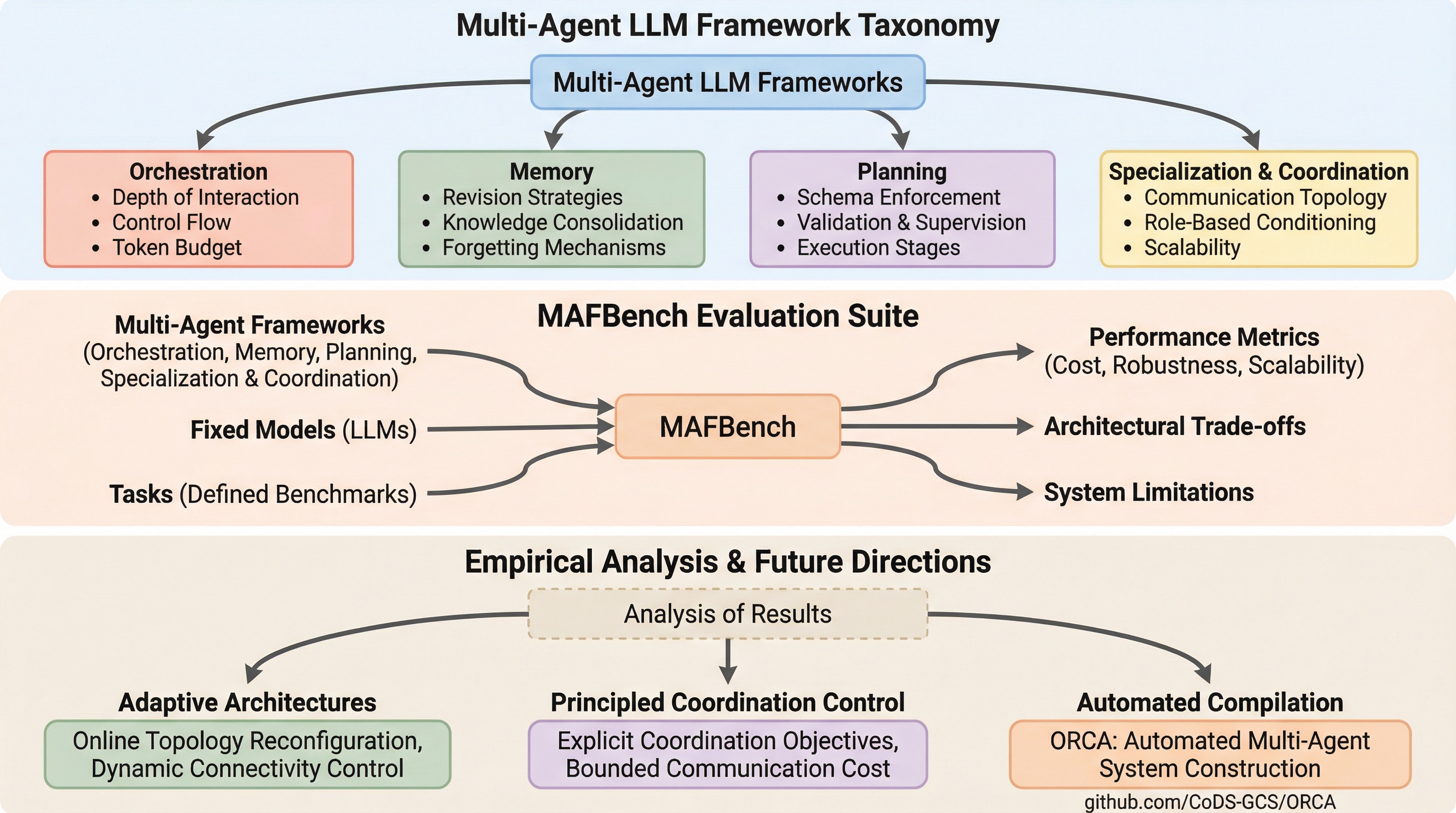
マルチエージェントLLMフレームワークは、エージェント間の相互作用やメモリ管理、タスク調整を規定するアーキテクチャ構造を持っていますが、その設計の選択がシステム全体の性能に決定的な影響を与えることが本研究で明らかになりました。 研究チームは、フレームワークを体系的に比較するための「アーキテクチャ・タクソノミー」と、既存のベンチマークを統合した評価スイート「MAFBench」を導入し、同一の言語モデルを使用した場合でもフレームワークの設計次第で性能に極端な差が出ることを実証しました。 実験の結果、設計の選択によって遅延が100倍以上増加し、計画精度が30%低下し、調整の成功率が90%以上から30%未満にまで激減する場合があることが判明したため、モデルの品質以上にフレームワークのアーキテクチャが重要であると結論付けられています。
なぜこの問題か
現在、大規模言語モデル(LLM)を基盤としたマルチエージェントシステムは、複雑なインテリジェントアプリケーションを構築するための標準的な手法として急速に普及しています。これに伴い、エージェントのオーケストレーションやメモリ管理、ツールへのアクセスを支援する多様なマルチエージェントLLMフレームワークが登場しました。しかし、これらのフレームワークが提供するアーキテクチャ上の選択が、実際のシステム性能にどのような影響を及ぼすのかについては、これまで十分に理解されてきませんでした。この知識の欠如は極めて深刻であり、アーキテクチャの選択一つで遅延やスループットに桁違いの差が生じ、精度やスケーラビリティにも大きなばらつきが出ることが推測されます。 既存の評価手法やベンチマークの多くは、ツールの利用能力、メモリと検索、あるいは協調的な推論といった個別の能力を測定することに特化しています。これらのベンチマークは単一の能力を分離して測定するには効果的ですが、複数の能力を統合し、それらが相互に作用する際のフレームワークレベルの挙動を特徴付けるようには設計されていません。…
核心:何を提案したのか
本研究の核心的な提案は、マルチエージェントLLMフレームワークを体系的に理解し評価するための新しい手法とツールの導入です。まず、研究チームは「アーキテクチャ・タクソノミー(建築的分類学)」を提案しました。これは、制御フロー、エージェントの抽象化、通信構造、メモリ管理、および実行セマンティクスという基本的な次元に沿って、多様なフレームワークを分類・比較するための概念的な枠組みです。このタクソノミーにより、特定のモデルやタスクに依存することなく、システムレベルでの設計のトレードオフを議論することが可能になります。 次に、このタクソノミーを具現化した評価スイートとして「MAFBench」を開発しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related