タスク特異性スコア:指示が監督において実際にどの程度重要かを測定する
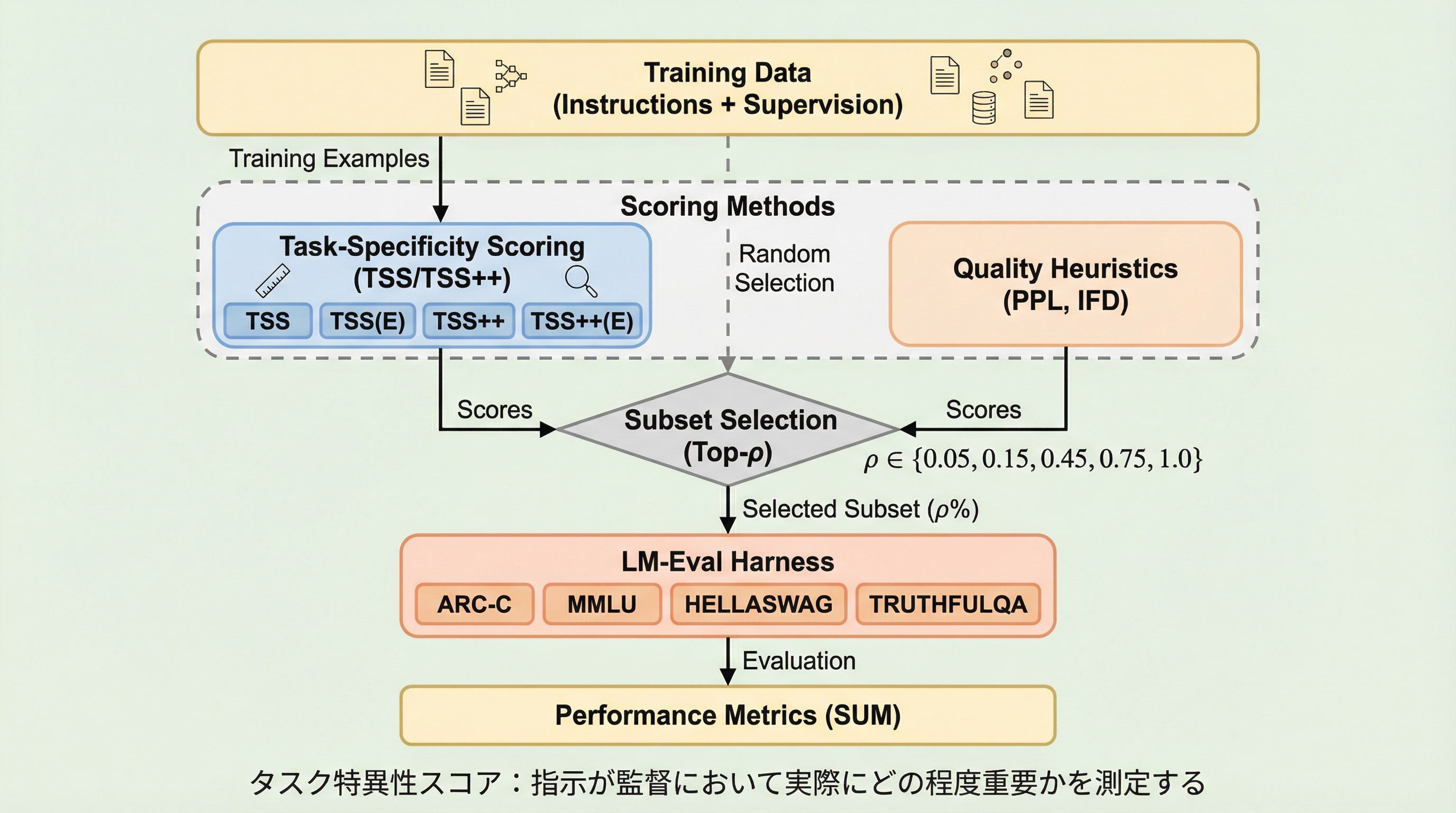
大規模言語モデルの指示チューニングにおいて、特定の指示がなくても出力が成立してしまう「指示の曖昧さ」が学習効率を下げているという課題に対し、指示が出力をどれだけ一意に決定しているかを測る「タスク特異性スコア(TSS)」を提案した。
TL;DR(結論)
大規模言語モデルの指示チューニングにおいて、特定の指示がなくても出力が成立してしまう「指示の曖昧さ」が学習効率を下げているという課題に対し、指示が出力をどれだけ一意に決定しているかを測る「タスク特異性スコア(TSS)」を提案した。 TSSは、真の指示と代替指示の間で出力の尤度を比較することで、そのデータがタスクを定義する上でどれほど重要かを定量化し、さらに品質と対照学習の概念を取り入れた「TSS++」によって、ノイズに強く精度の高いデータ選別を可能にしている。 3つのデータセットと3つのモデルを用いた検証の結果、TSSに基づいて選別されたわずか5%から15%の高品質なデータを用いることで、全データを用いた学習と同等以上の性能を達成できることが示され、計算資源が限られた状況での学習効率を大幅に向上させた。
なぜこの問題か
大規模言語モデル(LLM)を特定のタスクに適応させるための標準的な手法として、指示、入力、出力の三つ組からなるデータセットを用いた指示チューニングが広く普及している。しかし、既存の膨大なデータセットに含まれる多くの例は、指示の指定が不十分であるという根本的な問題を抱えている。例えば、ある入力に対して出力される回答が、複数の異なる指示(「質問に答えてください」や「文章を要約してください」など)のいずれに対しても妥当に見えてしまう場合がある。このようなデータは、モデルにとって学習自体は容易かもしれないが、特定の指示がどのようにモデルの行動を制約すべきかという重要な情報を提供していない可能性がある。 これまでのデータ選別手法は、主に「出力の品質」や「モデルへの適合度」に焦点を当ててきた。例えば、パープレキシティ(Perplexity)に基づくフィルタリングは、モデルにとって流暢で分布に近い回答を優先する傾向がある。…
核心:何を提案したのか
本論文の核心的な提案は、指示が出力をどれだけ一意に特定しているかを測定する「タスク特異性スコア(Task-Specificity Score: TSS)」である。これはモデルに依存しない指標であり、同じ入力に対して考えられる他の妥当な指示と比較して、真の指示がどれだけ出力を強く決定づけているかを評価するものである。直感的には、ある例の出力が、与えられた真の指示に対しては非常に適合し、かつ他の合理的な代替指示に対しては適合性が著しく低い場合に、その例は「高いタスク特異性」を持つと見なされる。 情報理論的な観点から見ると、TSSは入力が与えられた条件下での指示と出力の間の「条件付き相互情報量」のモンテカルロ近似として解釈できる。これは大規模言語モデルにおいて直接計算することが困難な値であるが、TSSを用いることで実用的な計算が可能になる。さらに、著者らはこの基本概念を拡張した「TSS++」を提案している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related