礼儀の仮面:大規模言語モデルにおける中国語の擬似的な丁寧さの理解のベンチマーク
大規模言語モデル(LLM)が中国語における「礼儀」「不作法」「虚偽の礼儀(表面上は丁寧だが裏に悪意がある表現)」をどの程度識別できるかを、GPT-5.1やDeepSeekを含む主要6モデルで体系的に評価した。
TL;DR(結論)
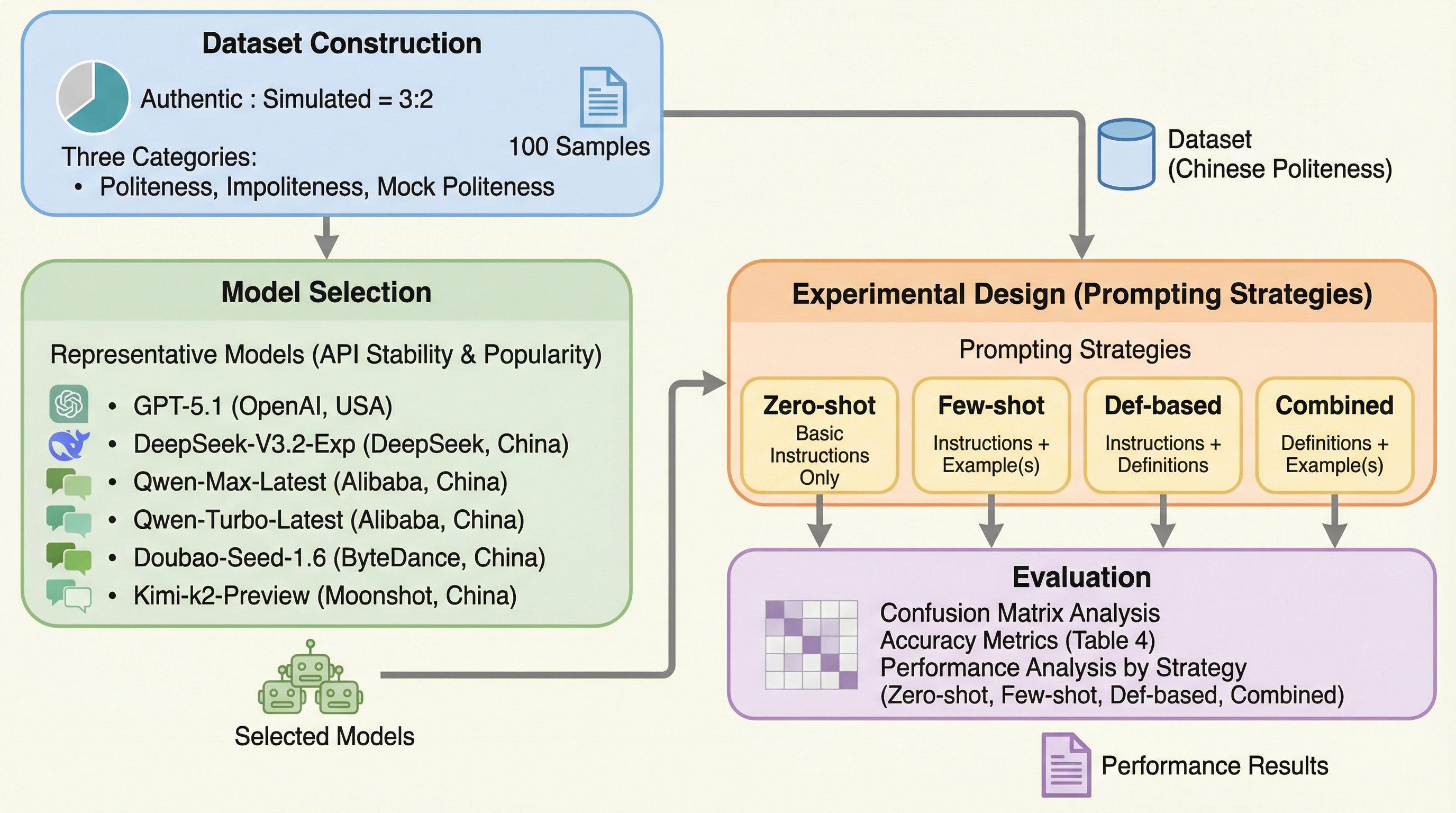
大規模言語モデル(LLM)が中国語における「礼儀」「不作法」「虚偽の礼儀(表面上は丁寧だが裏に悪意がある表現)」をどの程度識別できるかを、GPT-5.1やDeepSeekを含む主要6モデルで体系的に評価した。検証の結果、モデルは明確な礼儀や不作法は識別できるものの、文脈と表現が乖離する「虚偽の礼儀」を本物の礼儀と誤認する傾向が強く、特に事前の知識付与がない状態ではその複雑な意図を読み解くのが困難であることが判明した。語用論の理論的定義を与える「知識強化型」や、例示と定義を組み合わせた「ハイブリッド型」のプロンプト戦略を用いることで識別精度が大幅に向上し、中国語の文脈においては中国国内で開発されたモデルが米国製モデルを上回る性能を示すことが確認された。
なぜこの問題か
大規模言語モデル(LLM)は、数千億のパラメータを持つ深層ニューラルネットワークによって構築されており、2022年末のChatGPTの登場以来、人工知能は新たな時代に突入した。これらのモデルは単なる知識の生成器にとどまらず、社会や人文科学的な議論と深く結びついている。言語学の観点から見ると、LLMは深い意味や暗黙の関係性を理解する驚くべき能力を示しており、研究の新たな地平を切り開きつつある。しかし、現在のLLMが直面している大きな課題は「語用論的能力」の向上である。これは、話し手の意図、文脈、そして社会的な規範を理解する能力を指し、非人間的な技術が模倣する上で最も困難な側面とされている。これまでの研究から、多くのLLMは複雑な語用論的現象を認識・理解する際に依然として限界を抱えていることが示唆されている。事実情報の正確性を確保することは重要だが、それと同時に語用論的な次元における能力の欠如に焦点を当てることも極めて重要である。 特に中国語のような文脈依存性の高い言語において、言葉の裏に隠された意図を読み取ることは、人間同士のコミュニケーションにおいても高度なスキルを要する。…
核心:何を提案したのか
本研究の核心は、語用論的な視点から、代表的なLLMが中国語の礼儀、不作法、および虚偽の礼儀を認識する性能の差異を体系的に評価したことにある。この目的を達成するために、研究チームは「ラポール管理理論(Rapport Management Theory)」および「虚偽の礼儀モデル(Model of Mock Politeness)」のフレームワークを採用した。これらの理論に基づき、実際の対話データとシミュレーションされたデータを組み合わせた、3つのカテゴリーからなる独自のデータセットを構築した。具体的には、以下の3つのカテゴリーを定義している。第一に「礼儀(Politeness)」であり、これは社会的相互作用において適切、配慮がある、あるいは調和のとれた対人関係に資すると評価される言語的・行動的戦略を指す。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related