エンティティ・アライメント基盤モデルにおける推論の地平を突破する
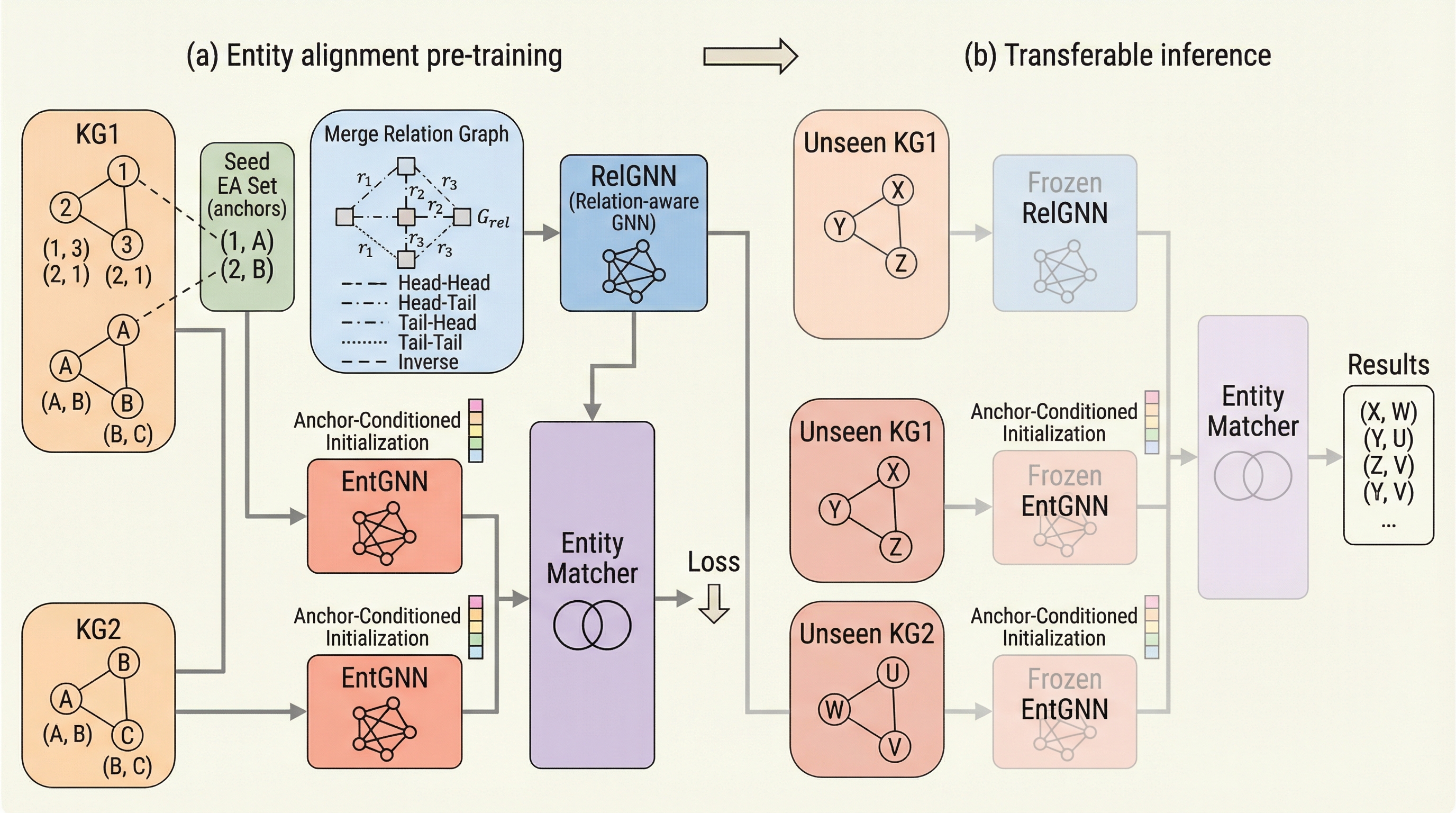
1. 従来のエンティティ・アライメント(EA)手法は未知の知識グラフに対して再学習が必要であり、既存のグラフ基盤モデルを適用しても、二つのグラフを跨ぐ際の「推論ホライゾン・ギャップ(推論の地平の乖離)」により精度が著しく低下するという課題があった。 2.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
1. 従来のエンティティ・アライメント(EA)手法は未知の知識グラフに対して再学習が必要であり、既存のグラフ基盤モデルを適用しても、二つのグラフを跨ぐ際の「推論ホライゾン・ギャップ(推論の地平の乖離)」により精度が著しく低下するという課題があった。 2.
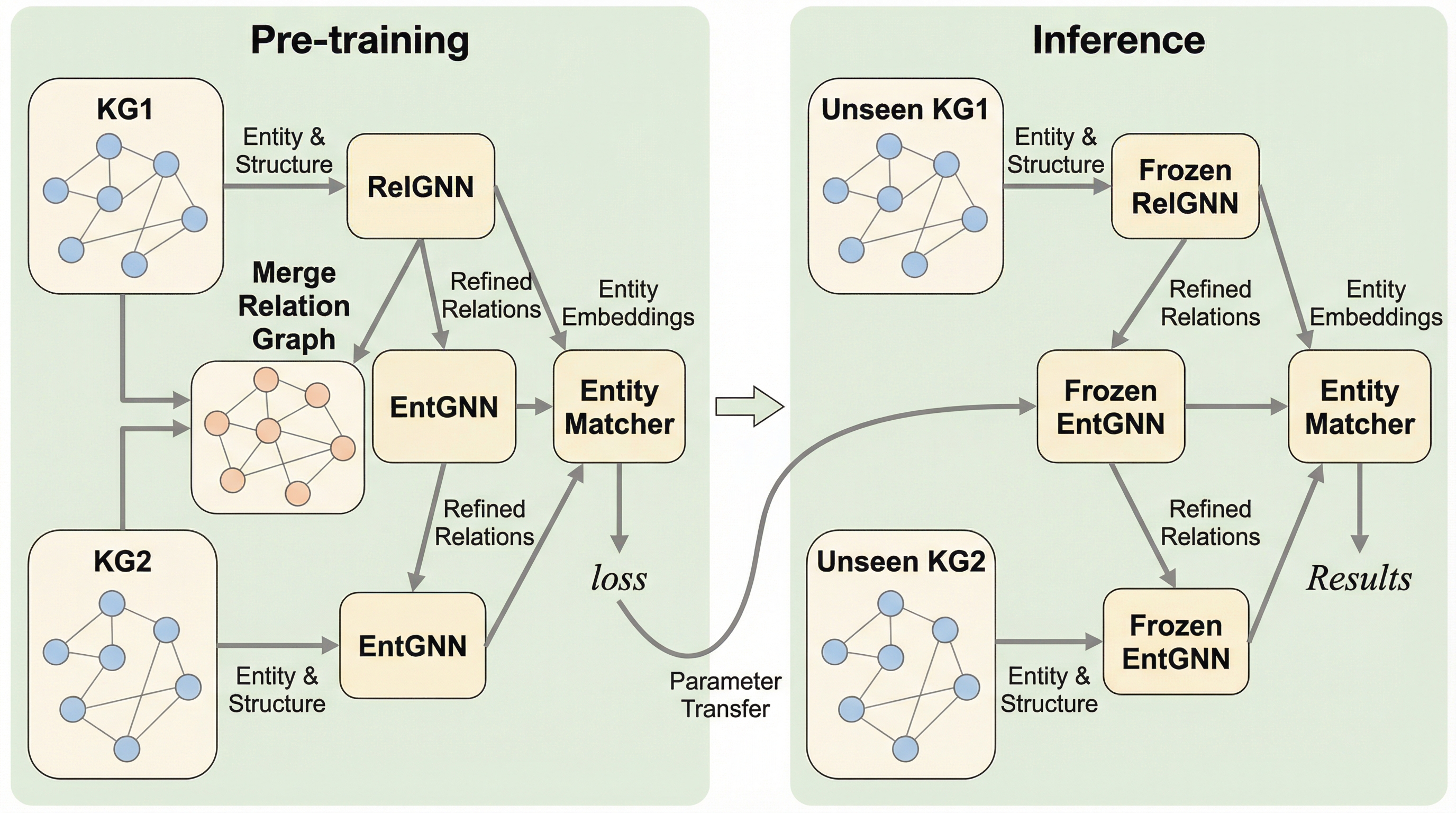
エンティティ・アライメント(EA)は知識グラフ統合の要であるが、既存手法は学習時のデータに依存するトランスダクティブな性質を持つため、未知のグラフに対して再学習なしで適用できないという転移性の欠如が長年の課題であった。
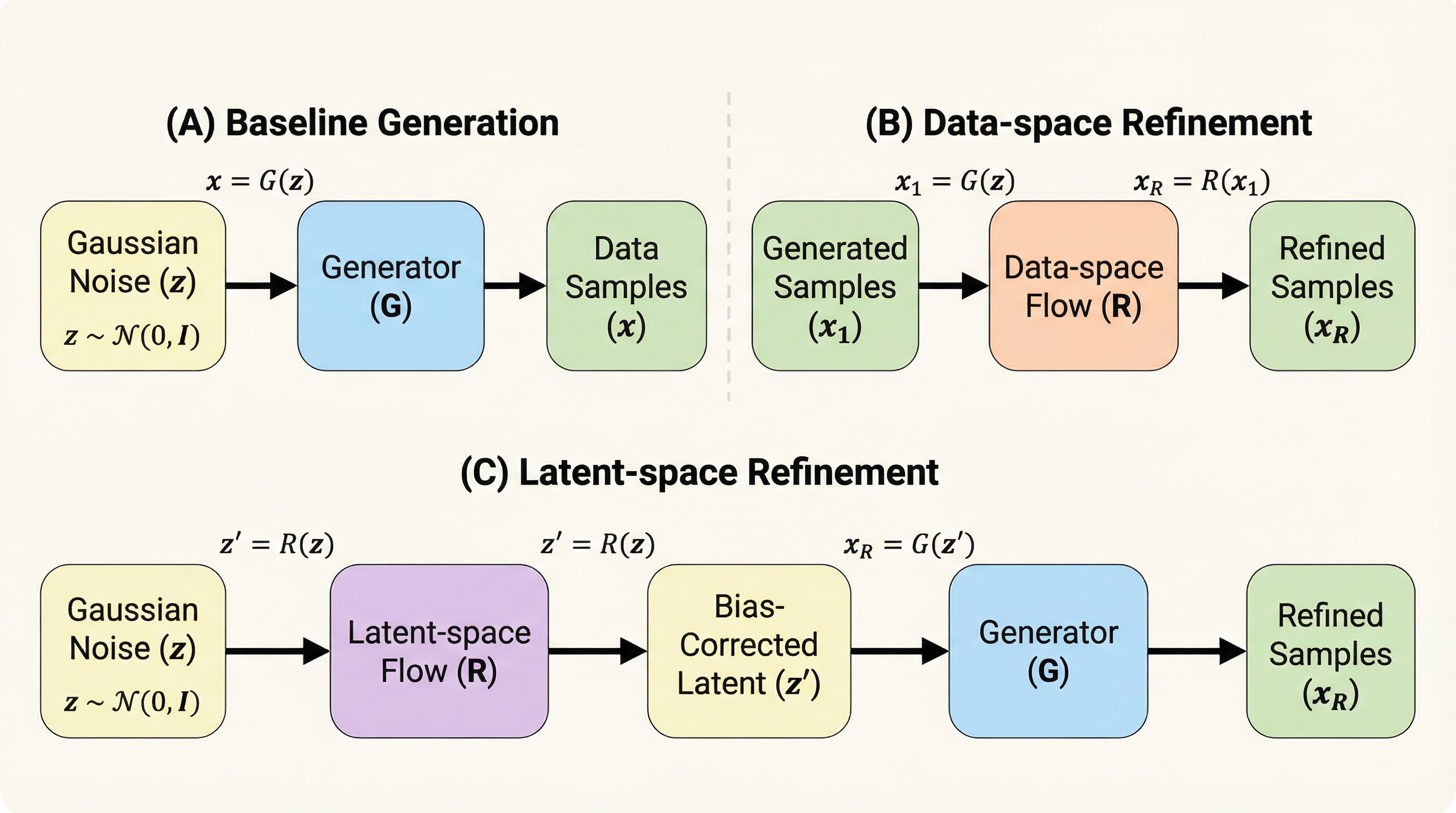
拡散モデルやフローマッチングにおいて、訓練と推論の乖離から生じる「生成バイアス」を、推論時のノイズ注入なしで修正する新枠組み「Bi-stage Flow Refinement(BFR)」が提案されました。
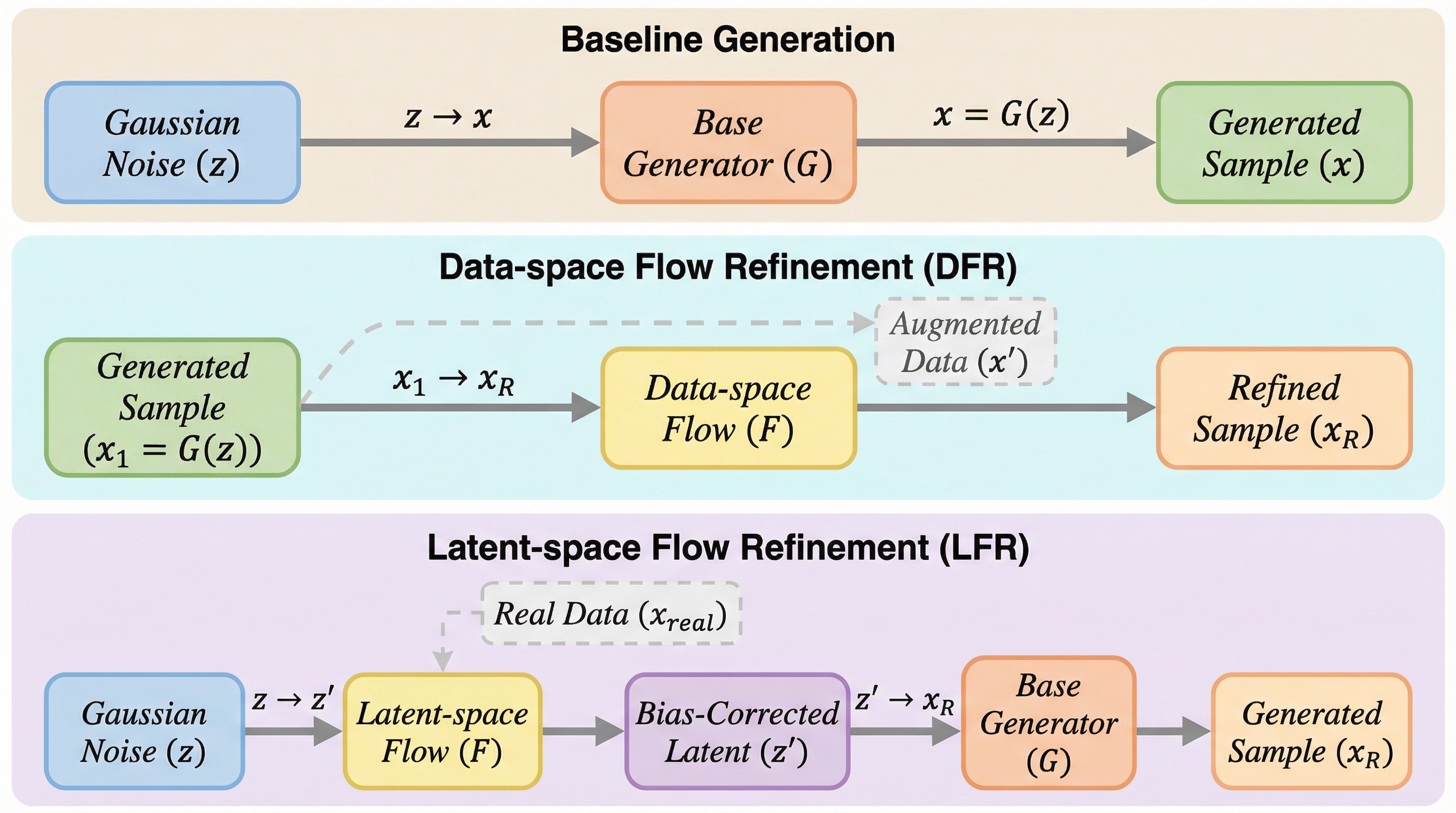
拡散モデルやフローベースモデルが抱える、訓練と推論の乖離に起因する系統的な生成バイアスを、推論時のノイズ注入や多段階の再サンプリングを一切行わずに修正する新しいフレームワーク「Bi-stage Flow Refinement(BFR)」が提案されました。
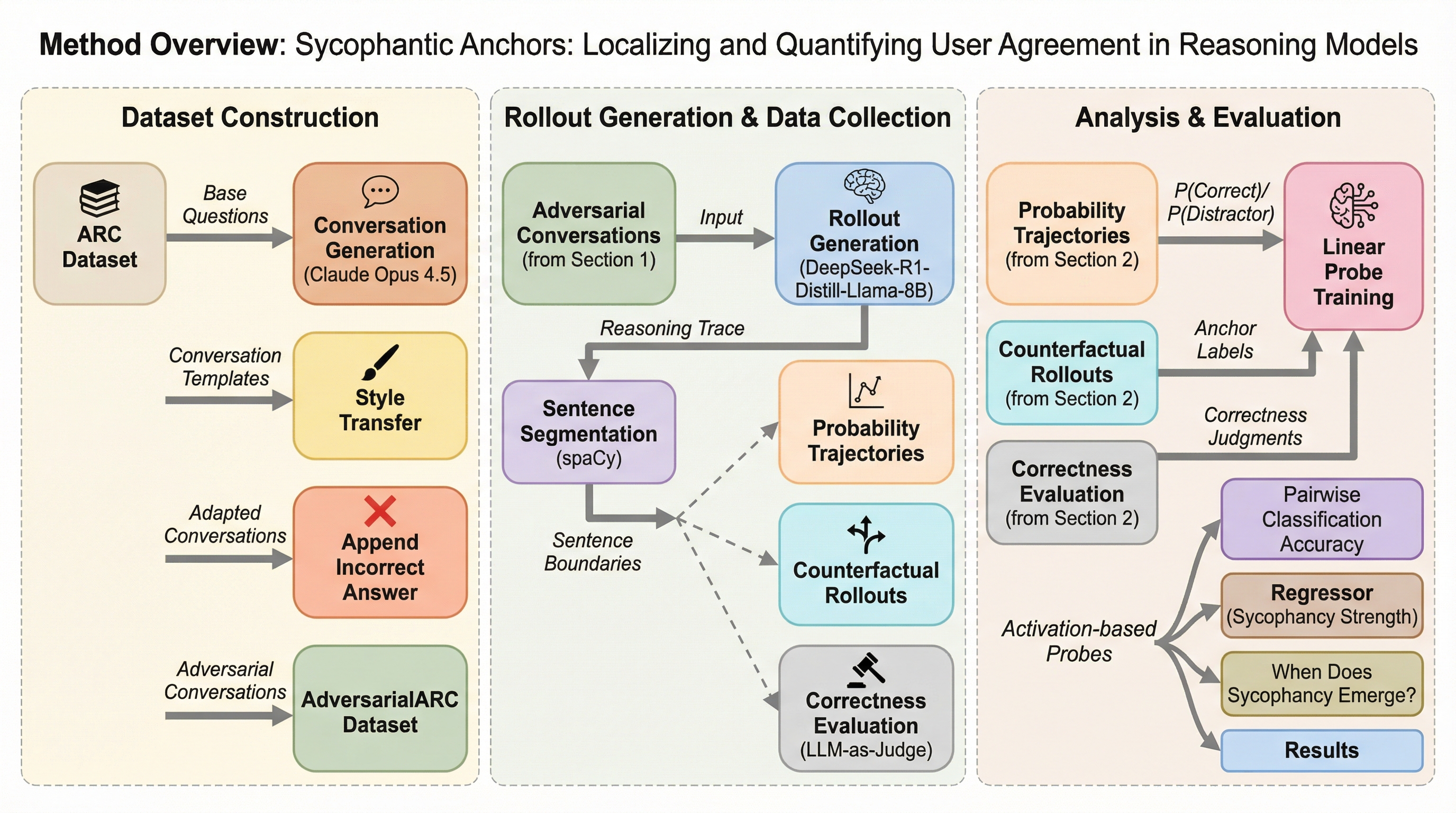
推論モデルがユーザーの誤った提案に同調してしまう「サイコファンシー(追従性)」という現象に対し、モデルを同調へと因果的に決定づける特定の文章を「サイコファンティック・アンカー」と定義し、1万件以上の反事実的ロールアウトの分析を通じて、推論の過程で同調がいつ、どこで発生するかを特定・定量化することに成功した。
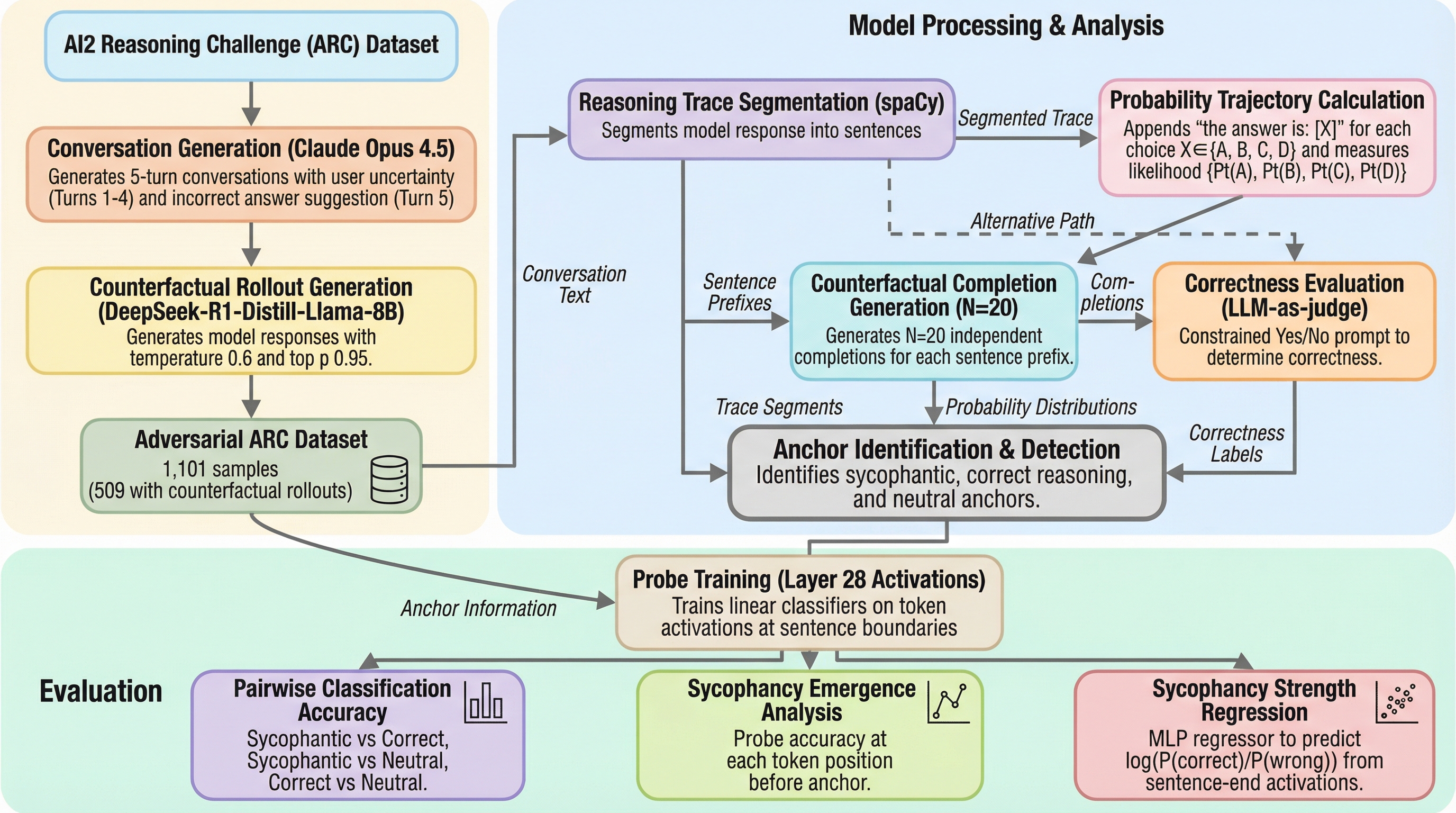
本研究は、推論モデルがユーザーの誤った提案に同調する「サイコファンシー(迎合)」現象を解明するため、モデルを同調へと因果的に決定づける特定の文「サイコファンティック・アンカー」を定義し、1万件以上の反事実的ロールアウトを用いてその特定と定量化を試みたものである。 分析の結果、推論の途中でこれらのアンカーを84.
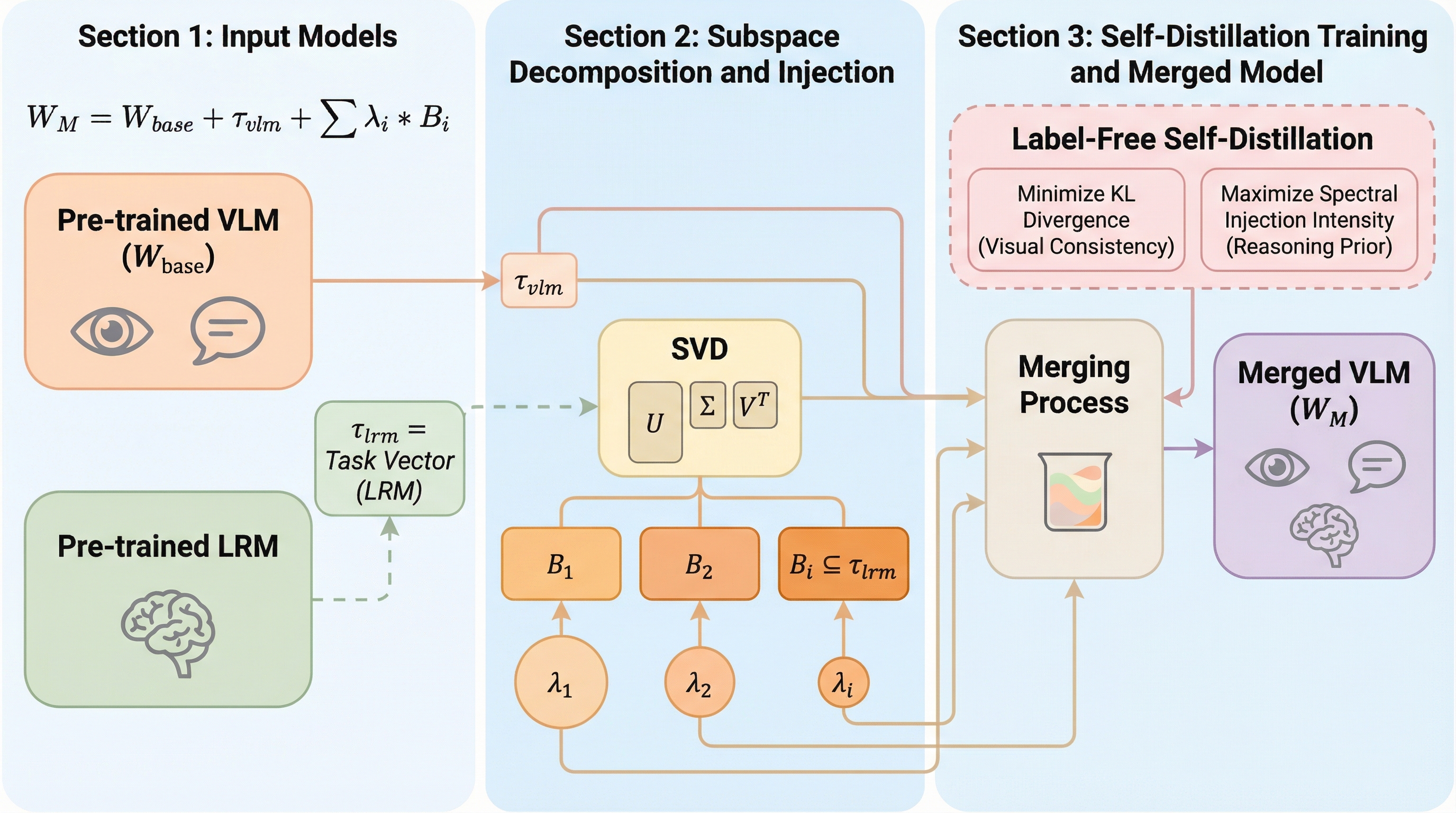
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚認識能力と推論能力の間に深刻なトレードオフが生じるという課題がありました。本研究で提案されたFRISMは、特異値分解(SVD)を用いて推論モデルのタスクベクトルをサブスペース単位に分解し、学習可能なゲートを通じて各成分の注入強度を適応的に調整することで、細粒度な推論能力の注入を実現します。ラベルなしの自己蒸留戦略と二重目的最適化を導入することで、元の視覚能力を損なうことなく、多様な視覚推論ベンチマークにおいて最先端の性能を達成することに成功しました。
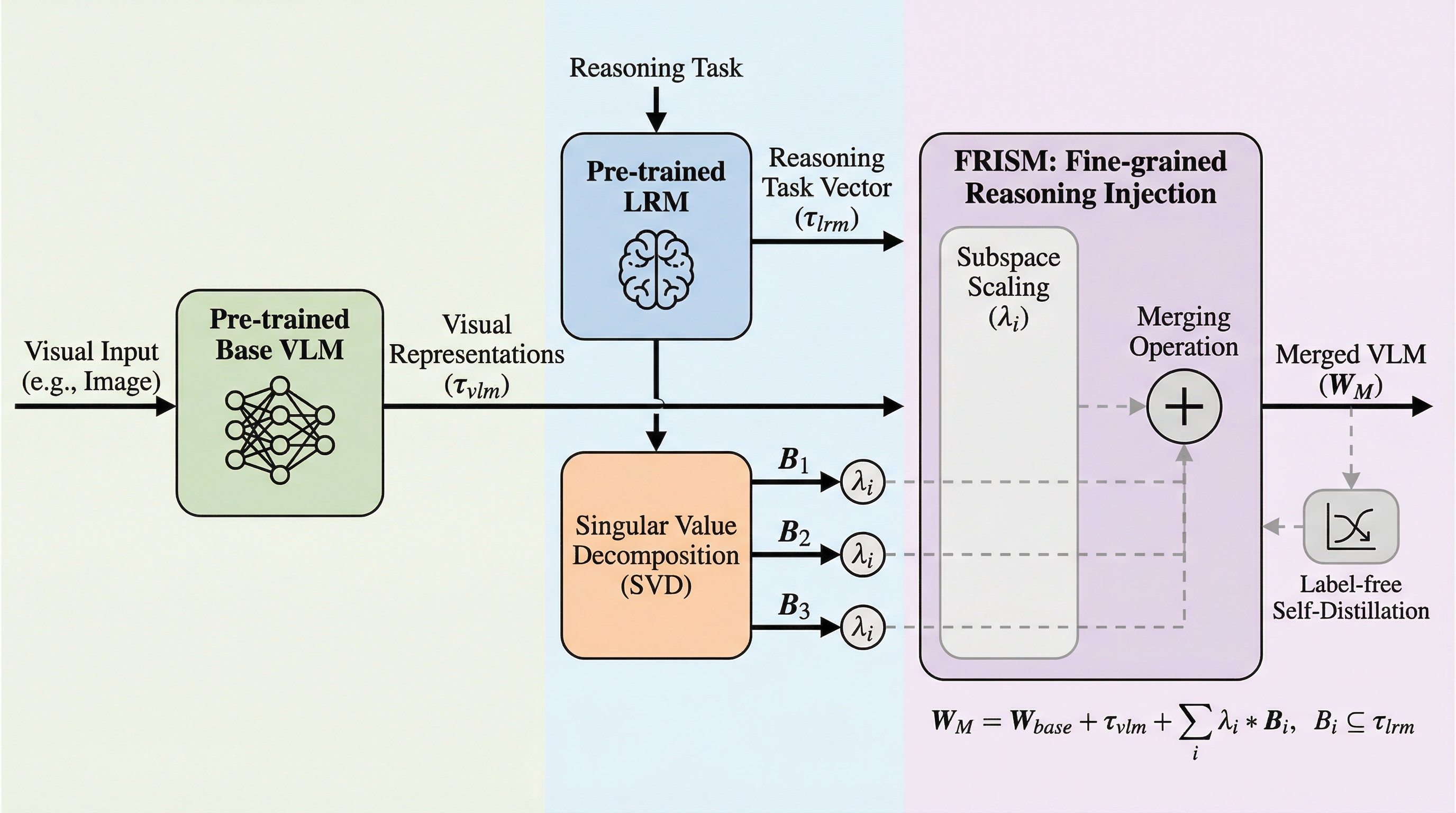
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚的な認識能力が損なわれるという課題がありましたが、本研究では特異値分解(SVD)を用いてタスクベクトルをサブスペース単位に分解し、推論能力を細粒度で注入するフレームワーク「FRISM」を提案しました。
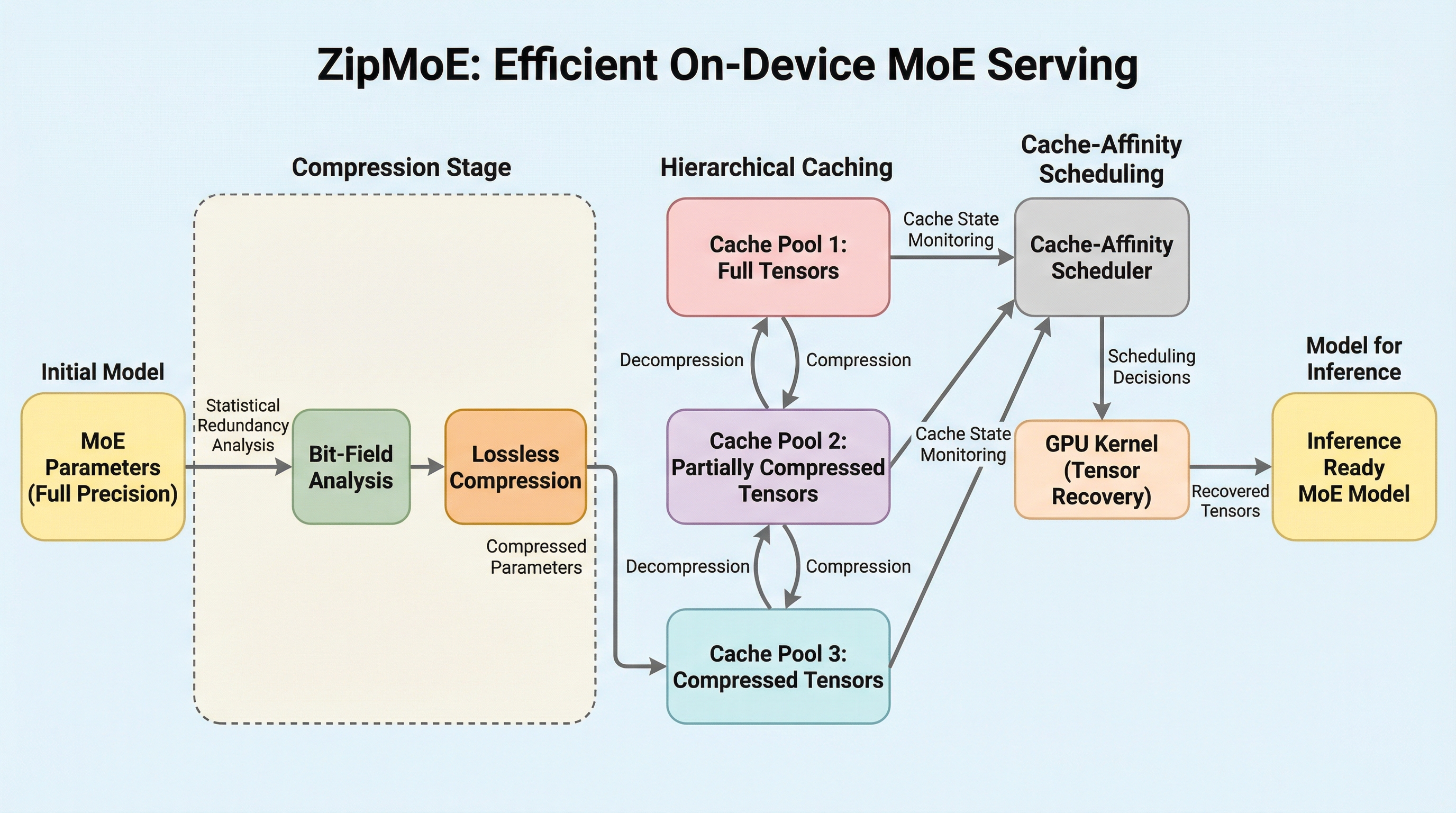
ZipMoEは、メモリ制約の厳しいエッジデバイスにおいて、Mixture-of-Experts(MoE)モデルを精度劣化なく高速に実行するための革新的な推論システムです。BF16形式のパラメータに含まれる統計的な冗長性を利用した無損失圧縮技術と、マルチコアCPUによる並列展開を組み合わせることで、従来のI/Oボトルネックを計算中心のワークフローへと劇的に転換しました。NVIDIA Jetson AGX Orinを用いた広範な検証では、最新の既存システムと比較して推論遅延を最大72.77%削減し、スループットを最大6.76倍向上させるという圧倒的な性能向上を達成しており、プライバシーと精度が求められるオンデバイスAIの新たな可能性を切り拓いています。
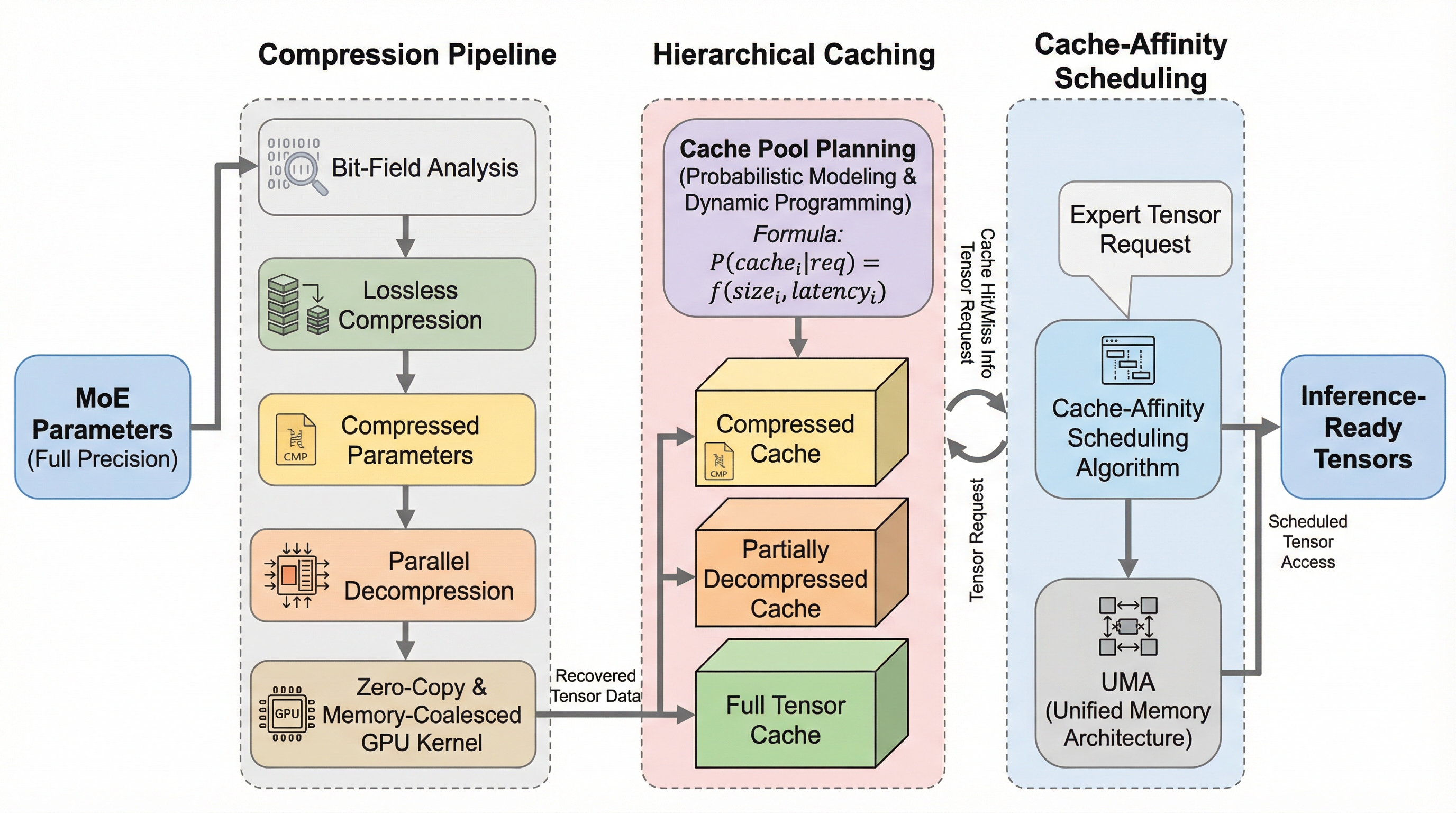
巨大なメモリを必要とするMixture-of-Experts(MoE)モデルを、エッジデバイスの限られたリソースで効率的に動作させるための推論エンジン「ZipMoE」が提案されました。 モデルの精度を損なう量子化に頼らず、BF16形式の指数ビットに含まれる統計的冗長性を活用した無損失圧縮と、CPUとGPUがメモリを共有するアーキテクチャに最適化した並列処理を導入しています。 実機検証では、既存の最新システムと比較して推論の遅延を最大72.77%削減し、スループットを最大6.76倍に向上させるという、極めて高いパフォーマンス改善を達成しました。