FRISM: 視覚言語モデルのための部分空間レベルのモデルマージによるきめ細やかな推論の注入
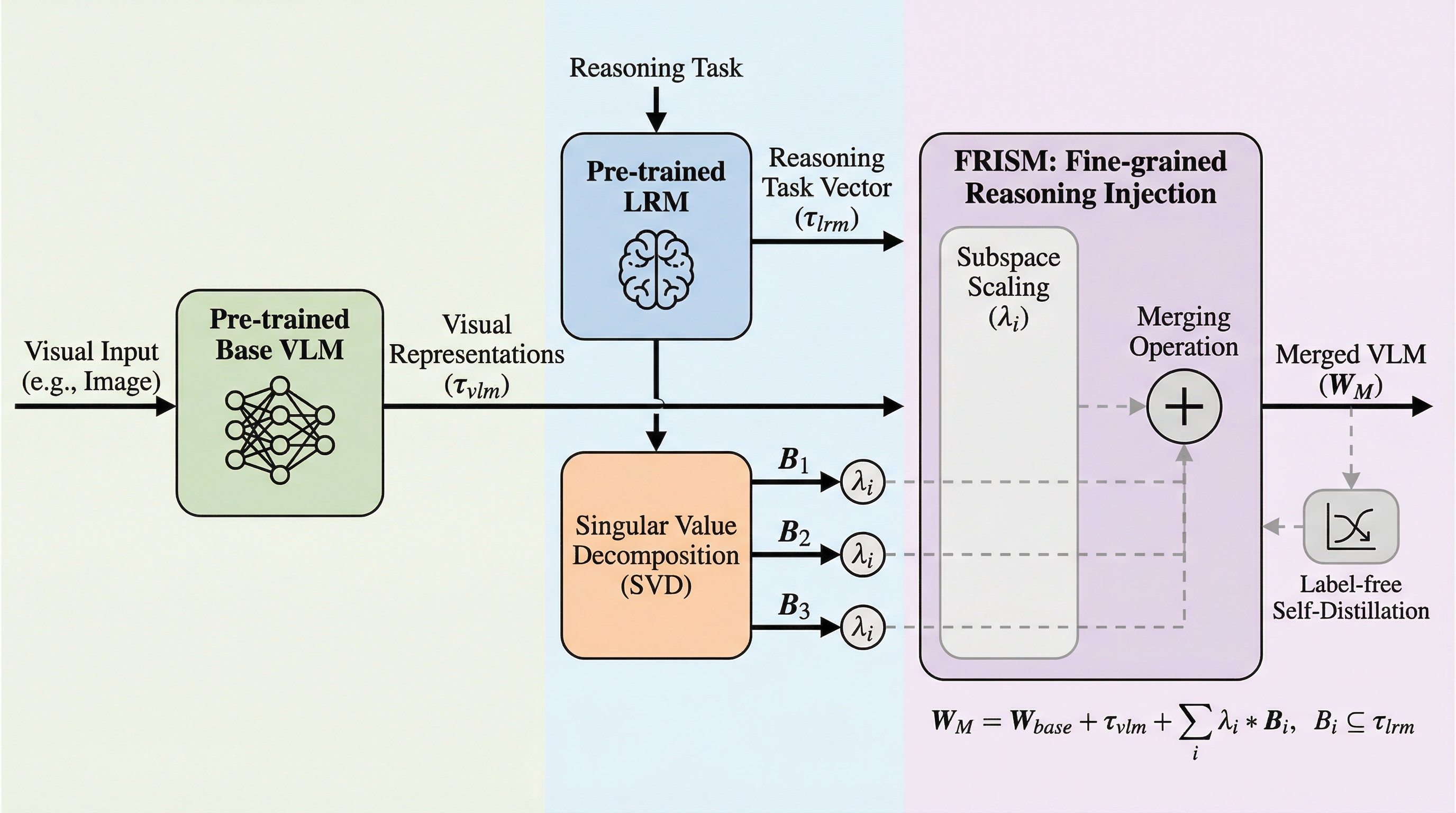
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚的な認識能力が損なわれるという課題がありましたが、本研究では特異値分解(SVD)を用いてタスクベクトルをサブスペース単位に分解し、推論能力を細粒度で注入するフレームワーク「FRISM」を提案しました。
TL;DR(結論)
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚的な認識能力が損なわれるという課題がありましたが、本研究では特異値分解(SVD)を用いてタスクベクトルをサブスペース単位に分解し、推論能力を細粒度で注入するフレームワーク「FRISM」を提案しました。 この手法では、推論能力が特定のサブスペースに符号化されているという知見に基づき、学習を通じて各サブスペースのスケーリング係数を適応的に調整することで、視覚的な特徴を維持しながら推論に寄与する成分のみを効果的に抽出してモデルに組み込むことが可能になっています。 ラベル不要の自己蒸留戦略と二重目的最適化を導入することで、視覚的な一貫性を保ちつつ推論の事前知識を最大限に吸収させることに成功しており、多様なベンチマークにおいて視覚能力を犠牲にすることなく推論性能を大幅に向上させ、最先端の成果を達成したことが確認されました。
なぜこの問題か
近年、LLaVAやQwen-VL、InternVLに代表される視覚言語モデル(VLM)は、画像認識や視覚的理解、テキスト生成といった幅広いタスクにおいて目覚ましい成果を上げています。一方で、DeepSeek-R1やOpenAI-o1のような大規模推論モデル(LRM)の登場により、数学的推論やプログラミング、複雑な問題解決といった能力の境界が大きく押し広げられてきました。これに伴い、VLMに対してこれらの高度な推論能力を効率的に付与することが重要な研究課題となっています。しかし、マルチモーダルな推論用トレーニングデータの不足や、追加学習に伴う膨大な計算コストが大きな障壁となって立ちはだかっています。 既存の研究では、モデルマージという手法を用いることで、LRMとVLMの重みを統合し、最小限のコストで推論能力を注入する試みが行われてきました。例えば、BR2Vはモデルマージによる推論能力の転移が可能であることを示しましたが、従来の多くの手法は層レベルでの粗い粒度でマージを行っていました。…
核心:何を提案したのか
本論文では、サブスペースレベルのモデルマージに基づく細粒度な推論注入フレームワークである「FRISM」を提案しています。FRISMは、推論能力が特定のサブスペースに符号化されているという観察に基づき、従来の層単位のマージから脱却して、より精密なパラメータ制御を実現する手法です。具体的には、LRMのタスクベクトルを特異値分解(SVD)によって直交するサブスペースに分解し、それぞれのサブスペースに対して適応的なスケーリング係数を学習させることで、推論に寄与する成分を選択的に強化します。 このアプローチの核心は、モデルの重み更新が低ランクの性質を持っているという知見を活かし、推論の事前知識をサブスペースの形式で扱う点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related