FRISM: サブスペースレベルのモデルマージによる視覚言語モデルへの細粒度な推論能力の注入
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚認識能力と推論能力の間に深刻なトレードオフが生じるという課題がありました。本研究で提案されたFRISMは、特異値分解(SVD)を用いて推論モデルのタスクベクトルをサブスペース単位に分解し、学習可能なゲートを通じて各成分の注入強度を適応的に調整することで、細粒度な推論能力の注入を実現します。ラベルなしの自己蒸留戦略と二重目的最適化を導入することで、元の視覚能力を損なうことなく、多様な視覚推論ベンチマークにおいて最先端の性能を達成することに成功しました。
TL;DR(結論)
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚認識能力と推論能力の間に深刻なトレードオフが生じるという課題がありました。本研究で提案されたFRISMは、特異値分解(SVD)を用いて推論モデルのタスクベクトルをサブスペース単位に分解し、学習可能なゲートを通じて各成分の注入強度を適応的に調整することで、細粒度な推論能力の注入を実現します。ラベルなしの自己蒸留戦略と二重目的最適化を導入することで、元の視覚能力を損なうことなく、多様な視覚推論ベンチマークにおいて最先端の性能を達成することに成功しました。
なぜこの問題か
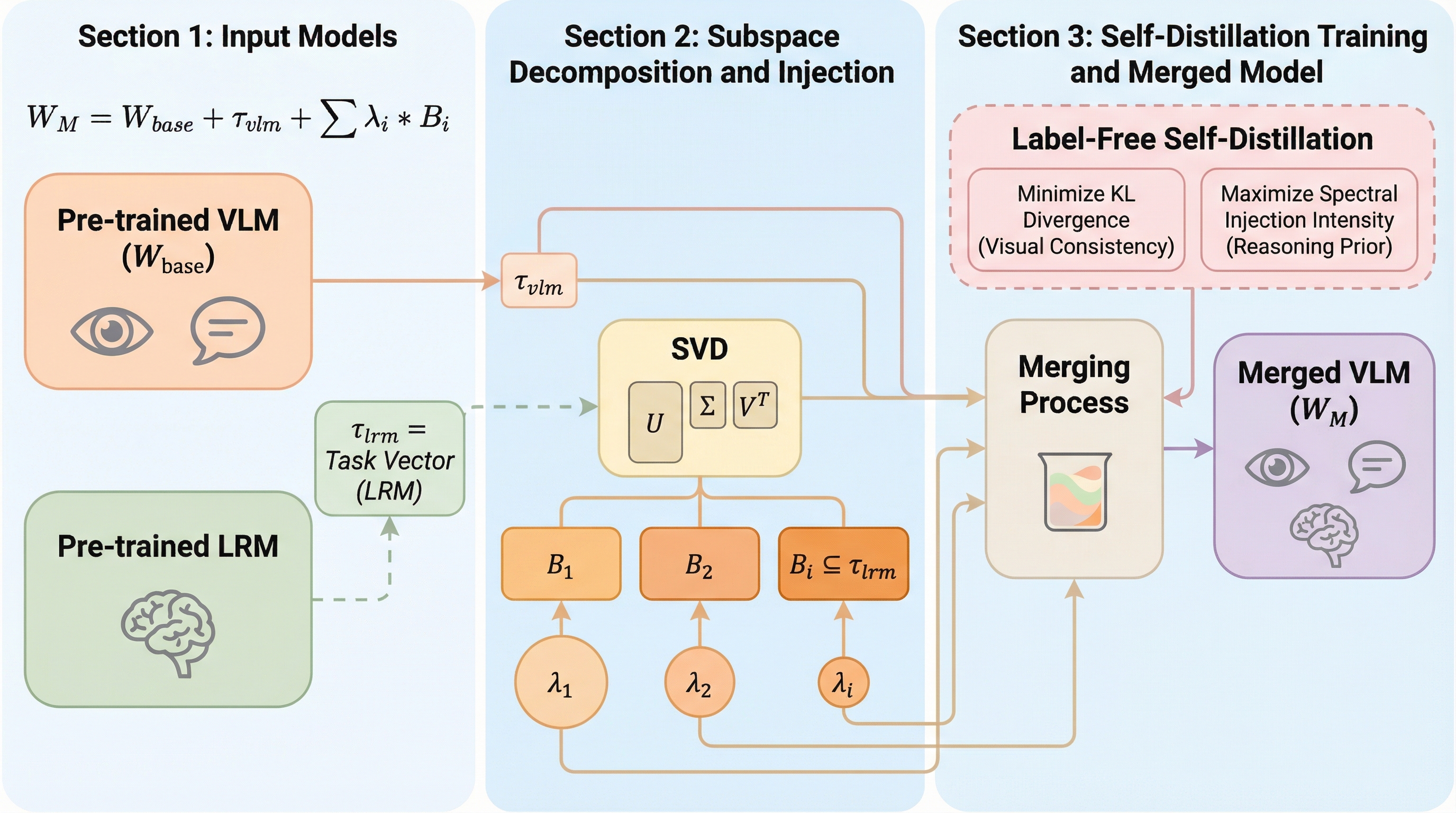
近年、LLaVAやQwen-VL、InternVLといった視覚言語モデル(VLM)は、画像認識や視覚的理解、テキスト生成などの幅広いタスクで目覚ましい成果を上げています。これらと並行して、DeepSeek-R1やOpenAI-o1に代表される大規模推論モデル(LRM)が登場し、数学的推論や複雑な問題解決、プログラミングなどの分野でモデルの能力を飛躍的に向上させました。これら二つのモデルの強みを組み合わせ、VLMに高度な推論能力を付与することは非常に有望な研究方向となっています。しかし、ラベル付きの視覚と言語の推論トレーニングデータセットは極めて希少であり、また学習後のポストトレーニングには膨大な計算コストがかかるという現実的な問題があります。 この課題を解決するために、最小限のトレーニングオーバーヘッドとデータ注釈コストでLRMとVLMの重みを統合する「モデルマージ」という手法が注目されています。先行研究であるBR2Vなどは、LRMからVLMへの推論能力の注入が可能であることを示しました。…
核心:何を提案したのか
本研究の核心は、層をモデル能力の最小単位と見なす従来の常識を覆し、単一の層の内部であっても推論能力と視覚表現が異なるサブスペース(部分空間)に存在するという洞察にあります。この仮説に基づき、サブスペースレベルでのモデルマージによる細粒度な推論注入フレームワークである「FRISM(Fine-grained Reasoning Injection via Subspace-level model Merging)」を提案しました。FRISMは、大規模推論モデル(LRM)のタスクベクトルを特異値分解(SVD)によって分解し、各サブスペースのスケーリング係数を適応的に調整することで、精密な推論能力の注入を可能にします。 具体的には、LRMのタスクベクトルから得られたサブスペースを「推論の事前知識」として利用します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related