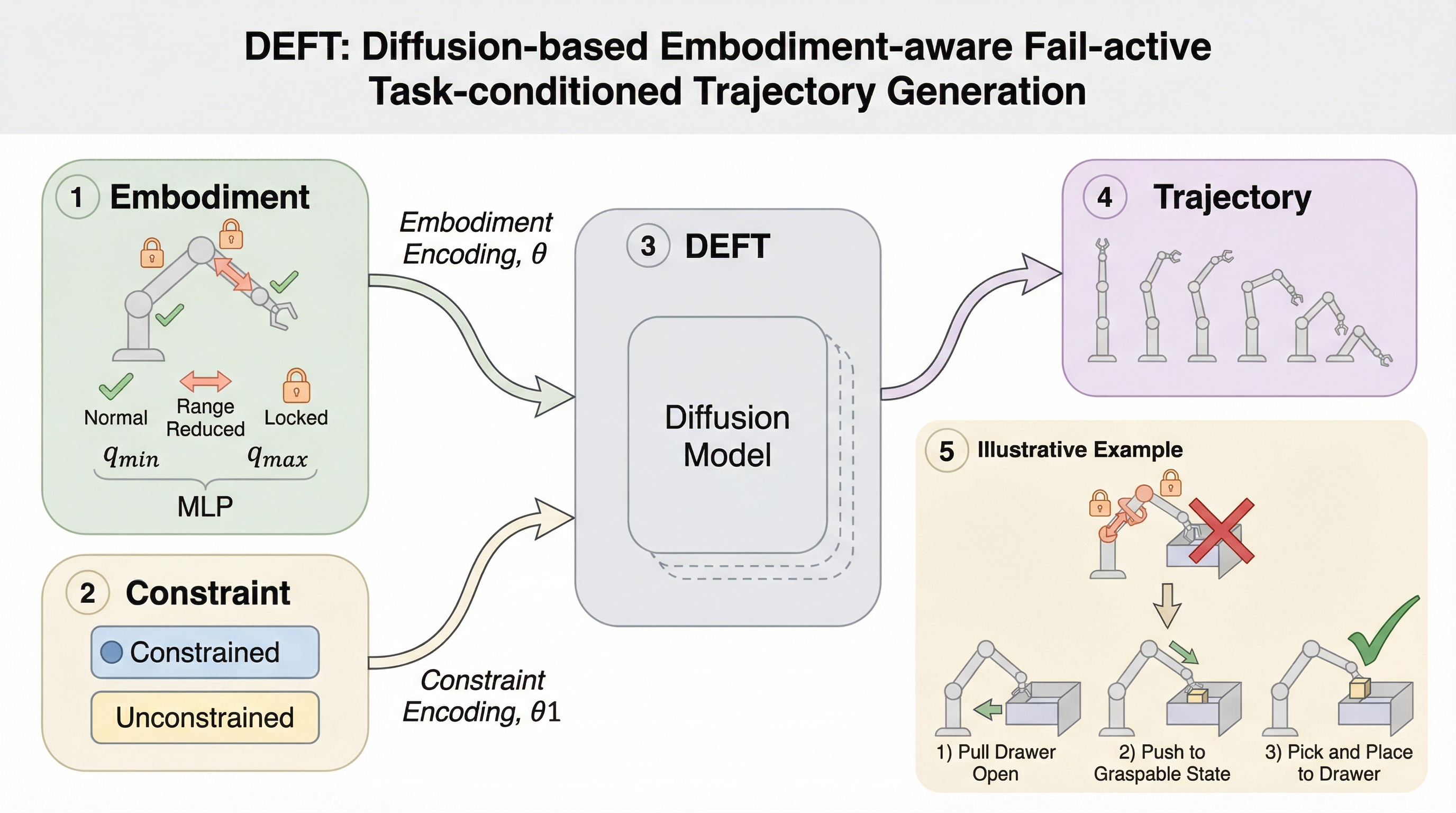
壊れていても、進み続ける:身体性とタスクを条件とした拡散ポリシーによるフェイルアクティブな軌道生成
ロボットの関節故障(可動域制限やロック)が発生した際、システムを停止させずにタスクを継続する「フェイルアクティブ」な動作を実現するため、拡散モデルを用いた軌道生成フレームワーク「DEFT」を提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ロボットの関節故障(可動域制限やロック)が発生した際、システムを停止させずにタスクを継続する「フェイルアクティブ」な動作を実現するため、拡散モデルを用いた軌道生成フレームワーク「DEFT」を提案しました。
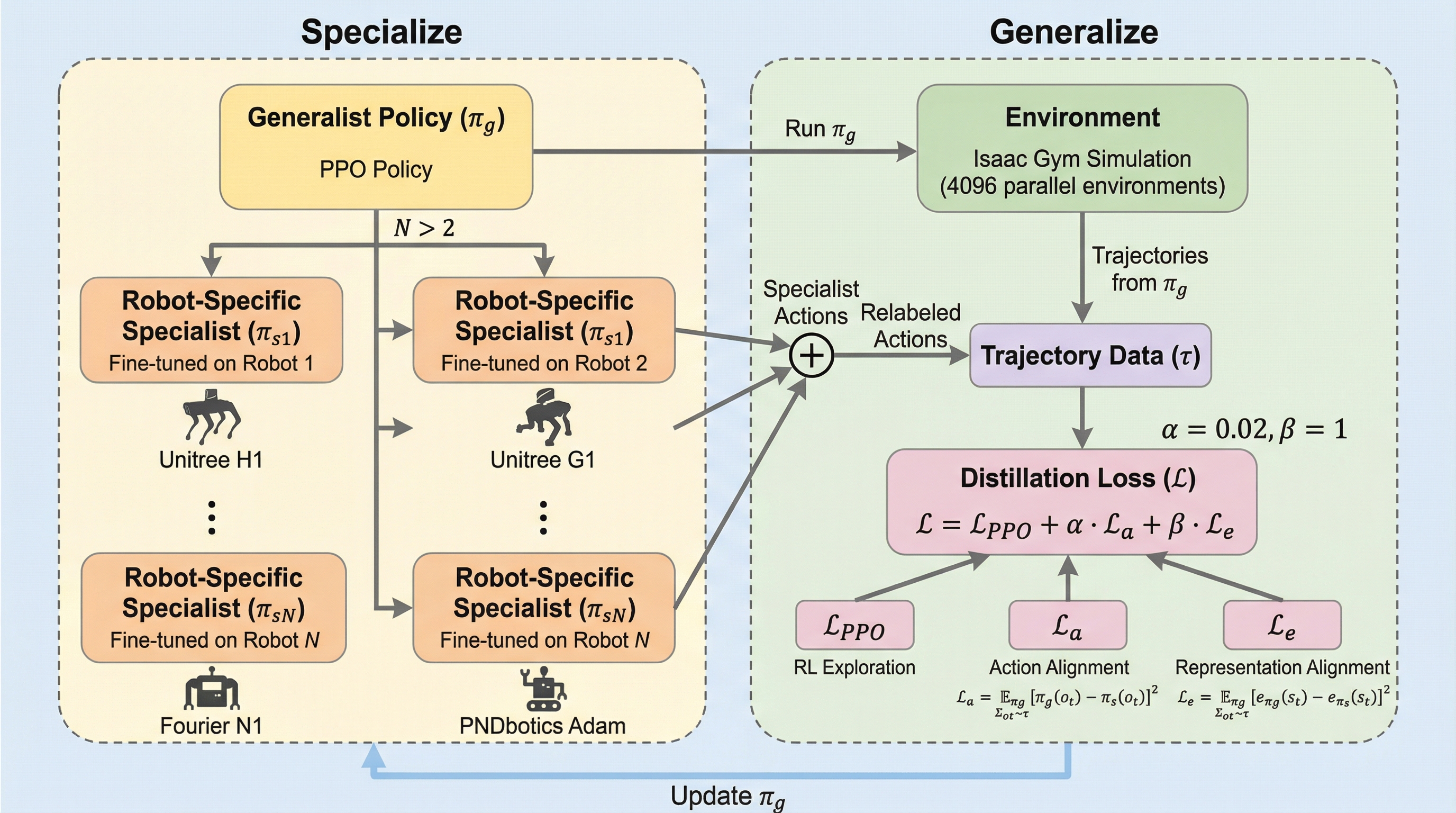
本研究は、構造の異なる複数のヒューマノイドを単一のポリシーで制御する学習フレームワーク「EAGLE」を開発し、歩行だけでなく、しゃがむ、傾くといった多様な全身動作を、ロボットごとの報酬調整なしで実現した。
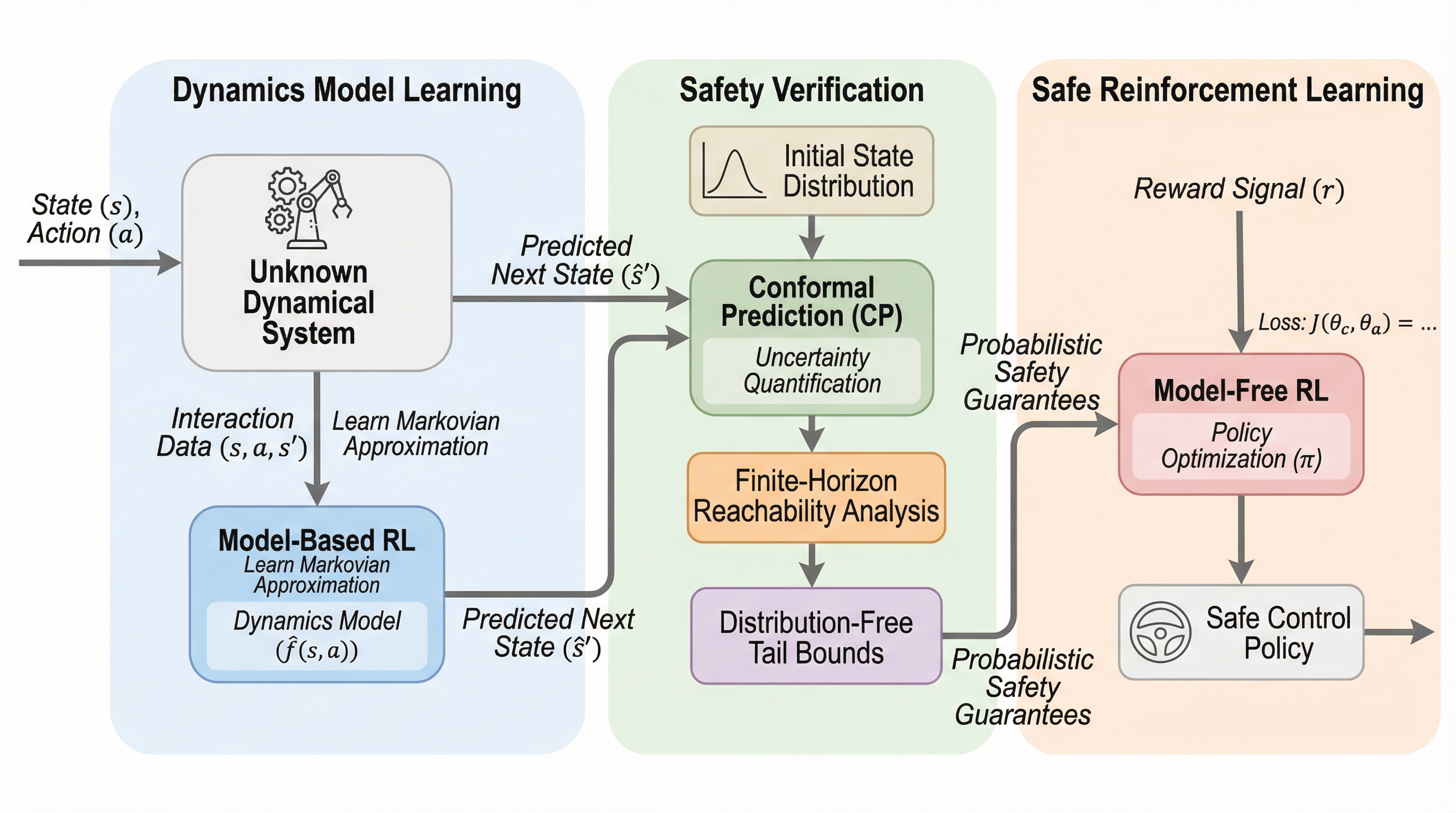
未知の力学系や確率的な環境下において、システムダイナミクスの完全な知識がなくても、数学的に厳密な「証明可能な安全性」を保証しながら制御を行う新しいフレームワーク「ReCORS」が提案されました。
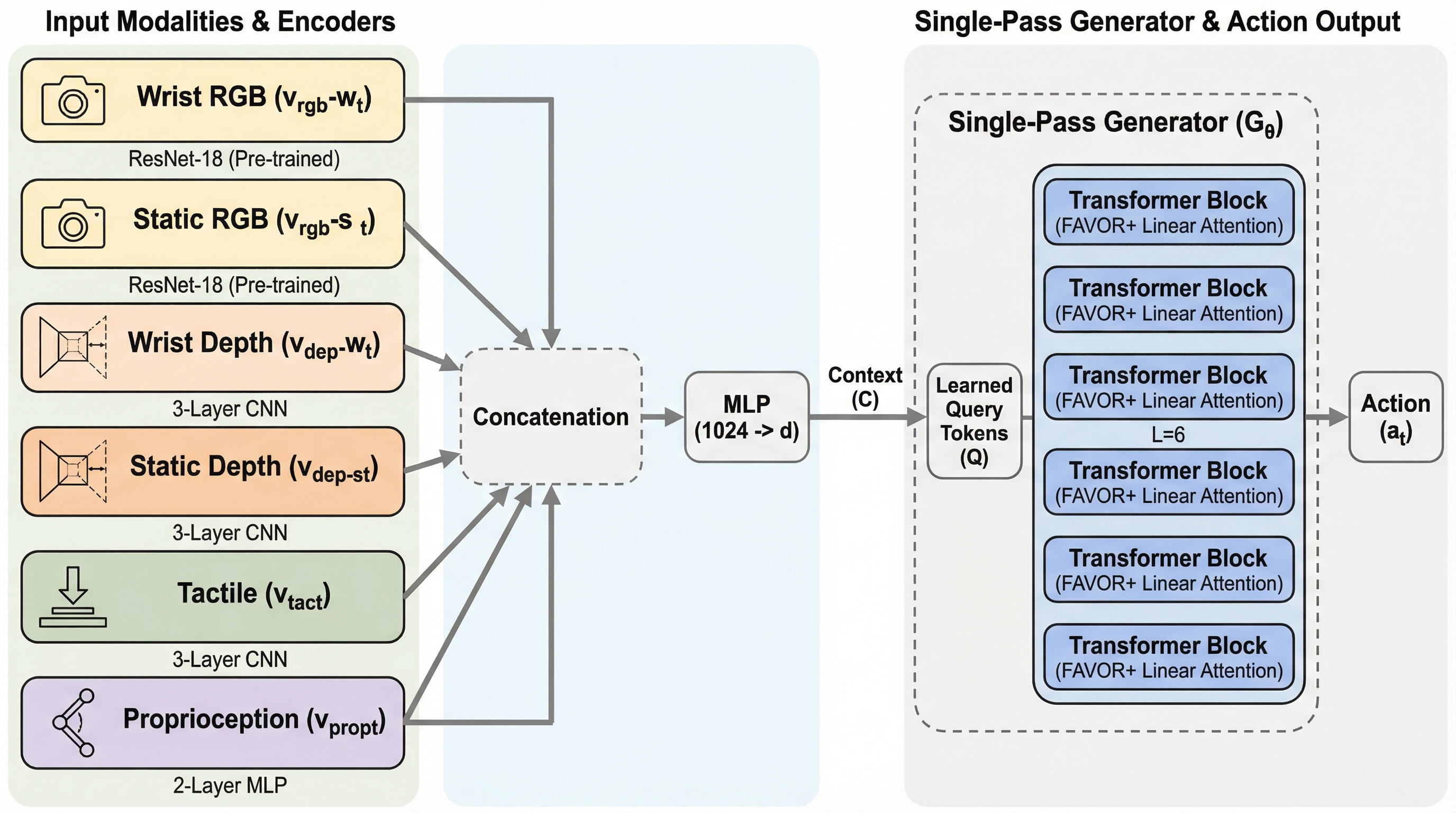
PRISMは、拡散モデルのような反復的な計算を必要とせず、単一のパスで多感覚情報を統合して複雑な動作を生成する新しい模倣学習フレームワークである。 バッチ全体での棄却サンプリング(Batch-global RS-IMLE)と線形注意機構(Performer)を組み合わせることで、リアルタイム性と多様な行動分布の表現を高い次元で両立することに成功した。 実際のロボットやシミュレーションにおいて、従来の拡散ポリシーを成功率で10〜25%上回り、動作の滑らかさを20〜50倍向上させつつ、30〜50Hzの高速な閉ループ制御を実現している。
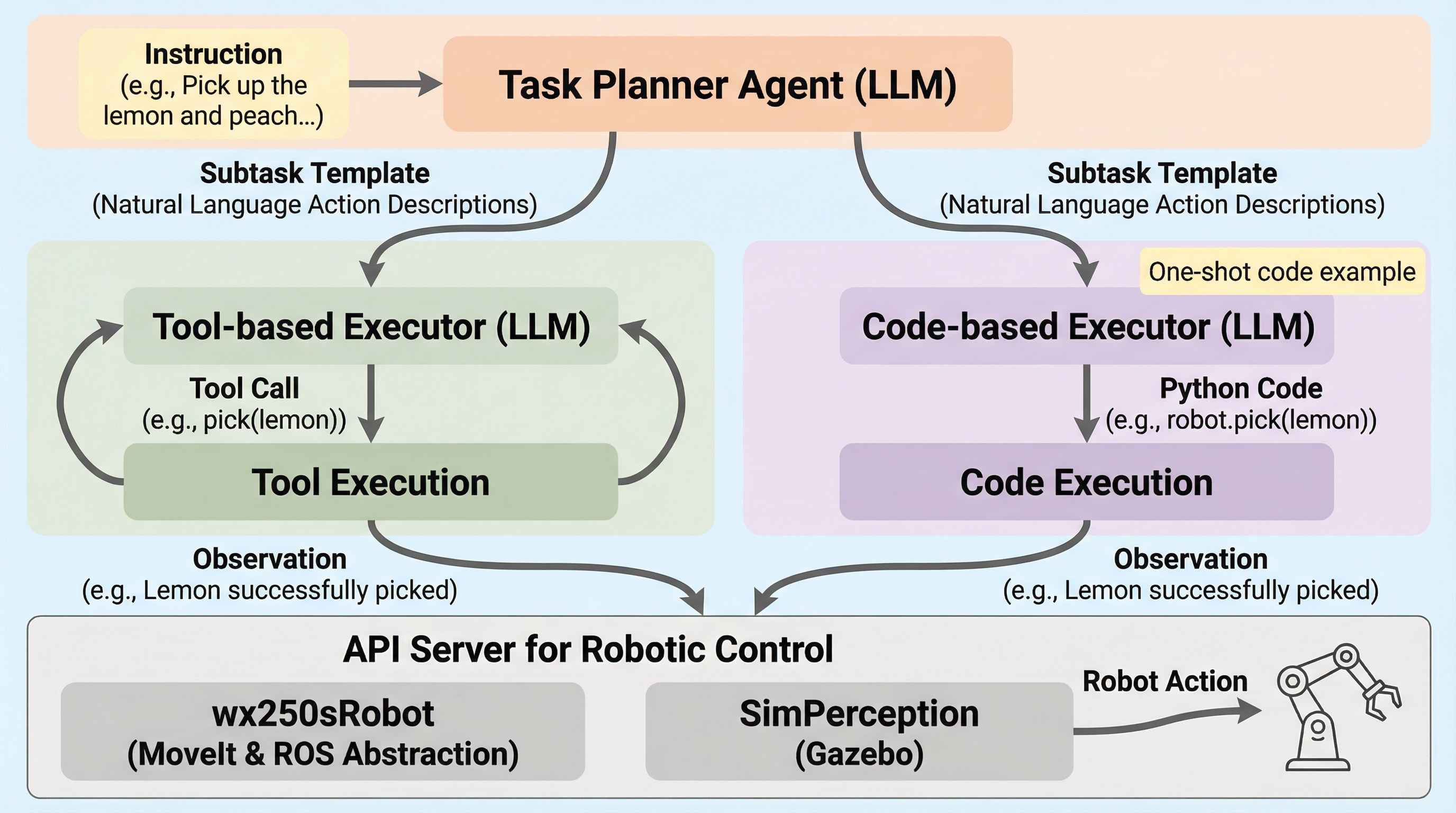
ALRMは、大規模言語モデル(LLM)をロボット操作の計画と実行に統合する新しいエージェント型フレームワークであり、ReAct形式の推論ループを用いることで、実行結果の振り返りと計画の動的な修正を可能にしました。
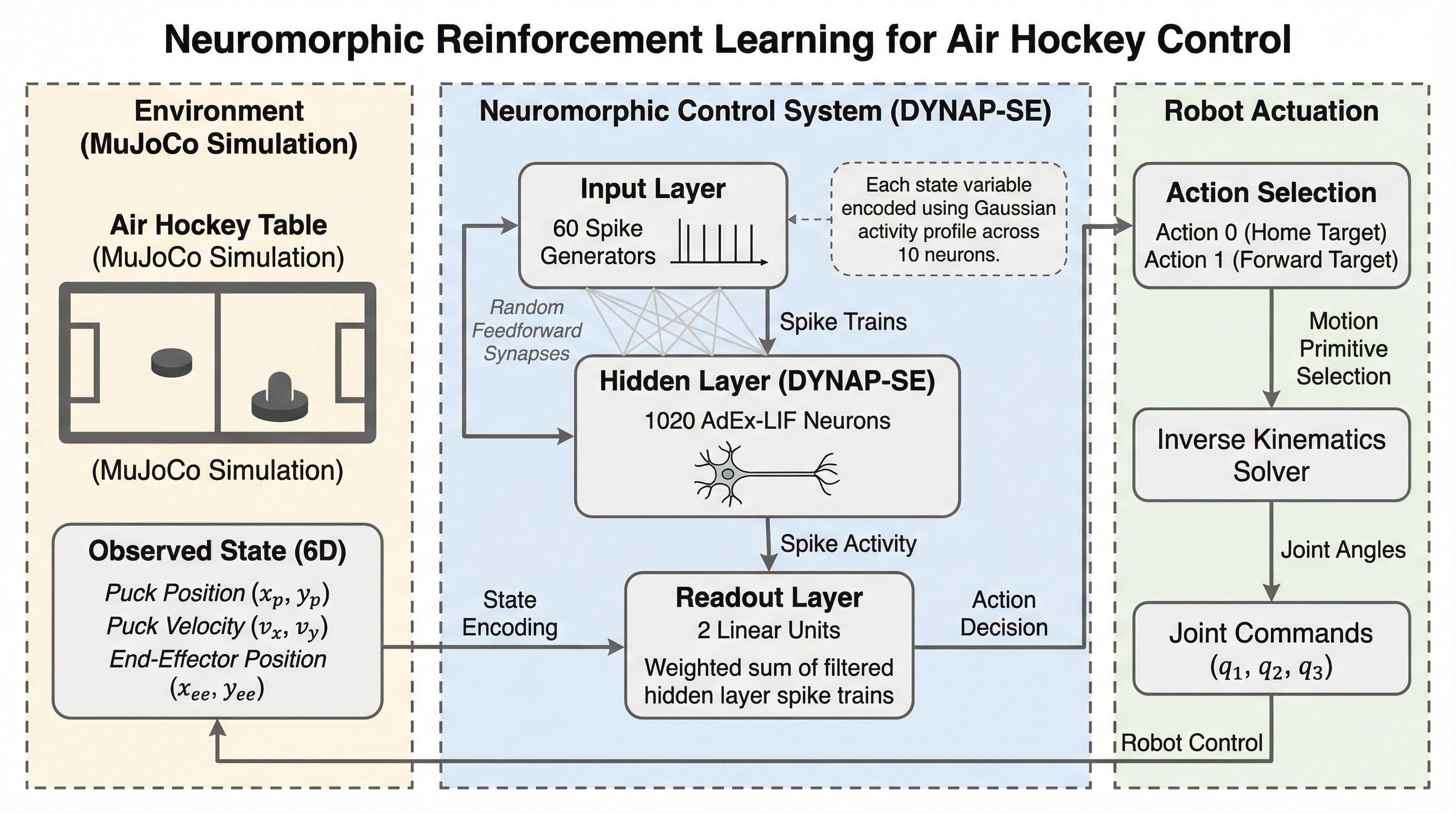
本研究は、ミリ秒単位の判断が求められる高速なエアホッケー競技において、アナログとデジタルの混合信号を扱う「DYNAP-SE」ニューロモーフィック・プロセッサを用いたスパイキングニューラルネットワーク(SNN)による制御を実現しました。
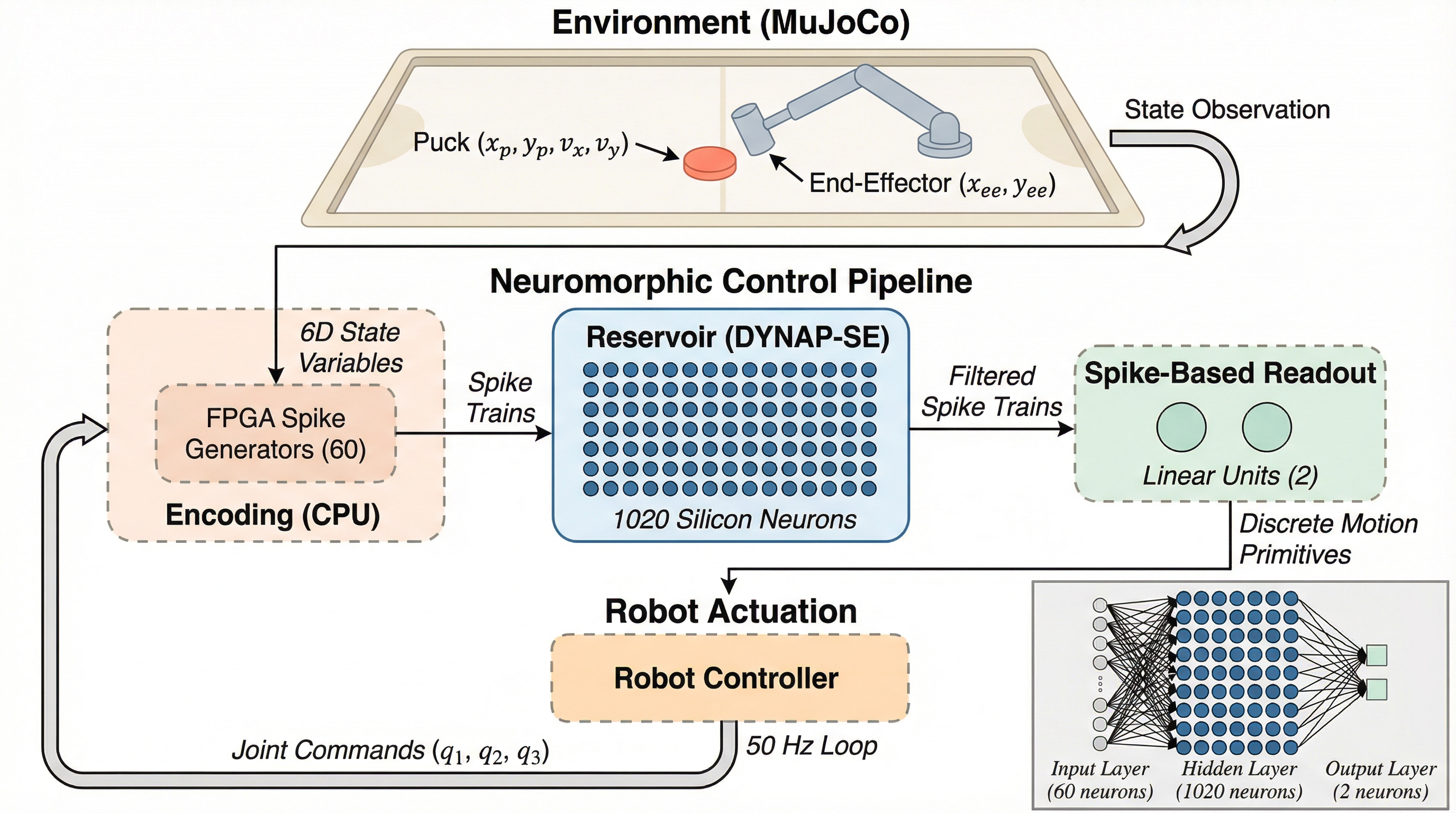
本研究は、低消費電力なアナログ・デジタル混在型ニューロモーフィック・プロセッサであるDYNAP-SEを活用し、極めて高速な意思決定が要求されるエアホッケー・ロボットの制御をスパイク強化学習によって実現した。
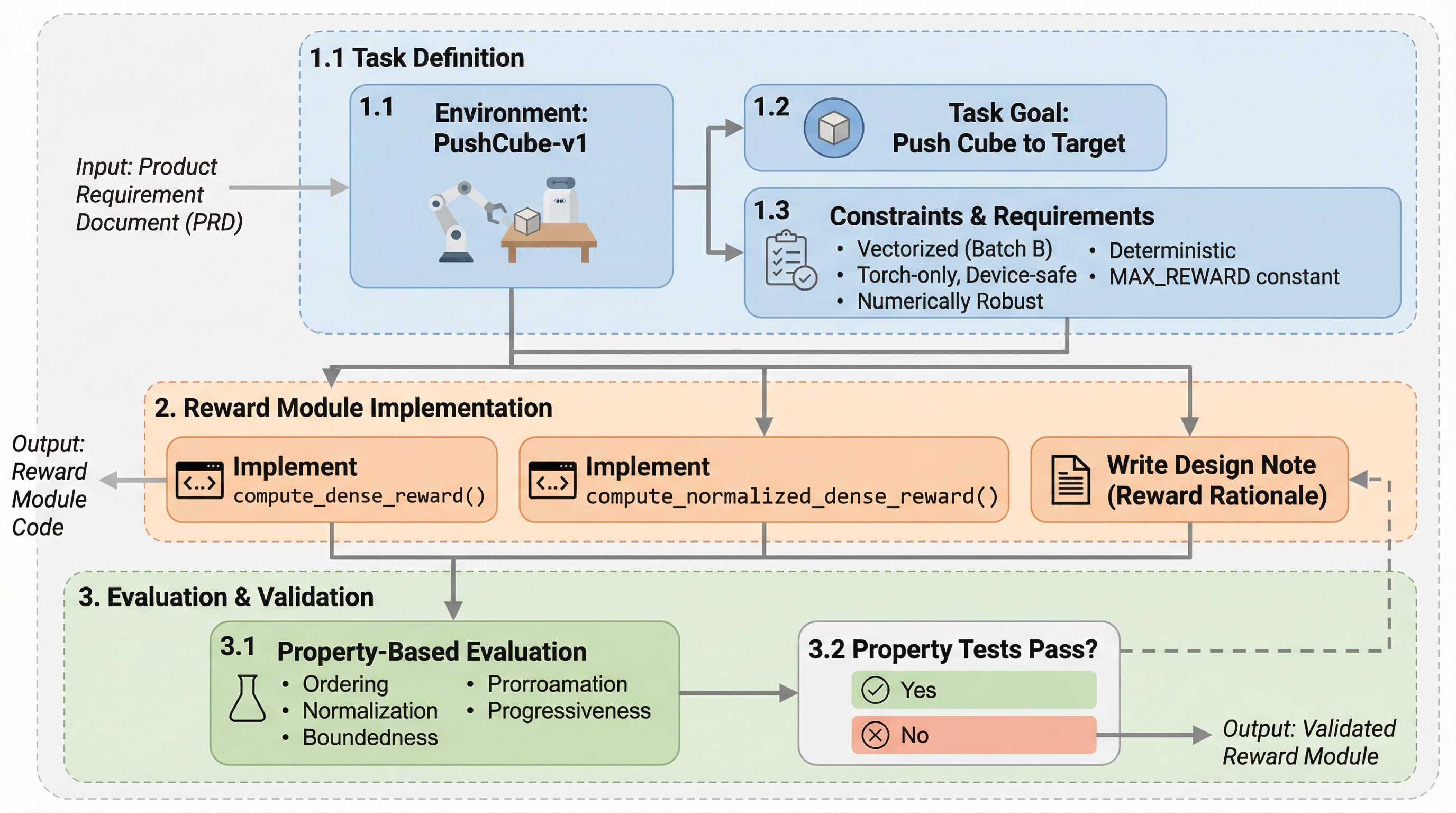
EmboCoach-Benchは、大規模言語モデル(LLM)を基盤としたエージェントが、ロボットの制御ポリシーを自律的に設計・実装・最適化する能力を評価するための、世界初のプロジェクトレベルのベンチマークである。
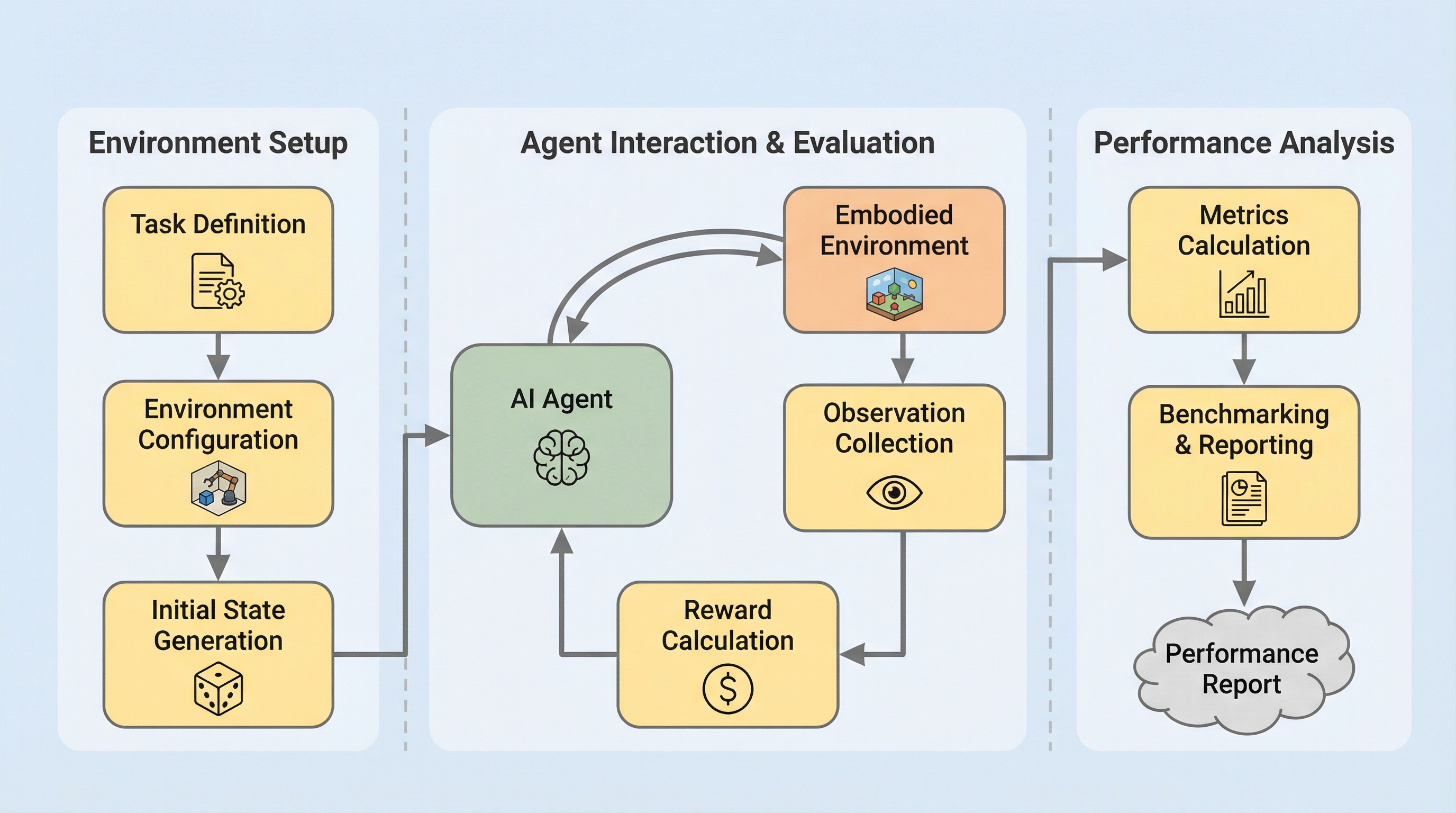
EmboCoach-Benchは、AIエージェントがロボットの制御ポリシーを自律的に設計・最適化する能力を評価するための新しいベンチマークであり、32種類の多様なタスクと4つの主要なシミュレーション基盤を用いて、エンジニアリングの全工程を網羅的に測定します。
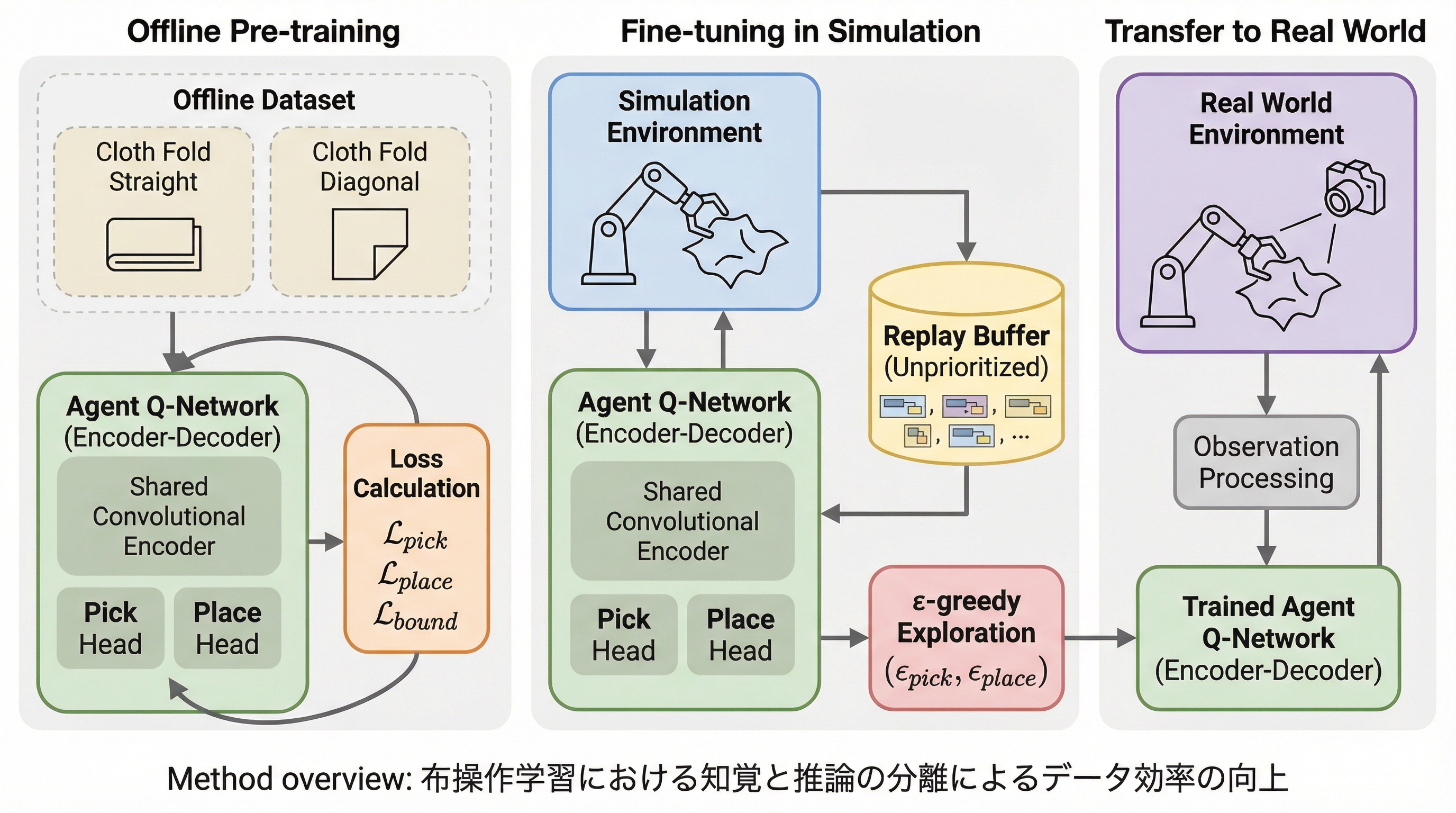
布操作という高次元で複雑な課題に対し、知覚と推論のプロセスを分離することで、学習効率とモデルの軽量化を同時に実現する新しいフレームワークを提案している。シミュレーション内の完全な状態情報を活用して「最適なエージェント」を訓練し、その知識を視覚ベースの現実世界用モデルへと「クロスモダリティ蒸留」によって転移させる手法を確立した。既存のベンチマークにおいて、従来手法よりもモデルサイズを95%削減しながら、性能を21%向上させることに成功し、大規模なデモンストレーションなしでの効率的な学習が可能であることを証明した。