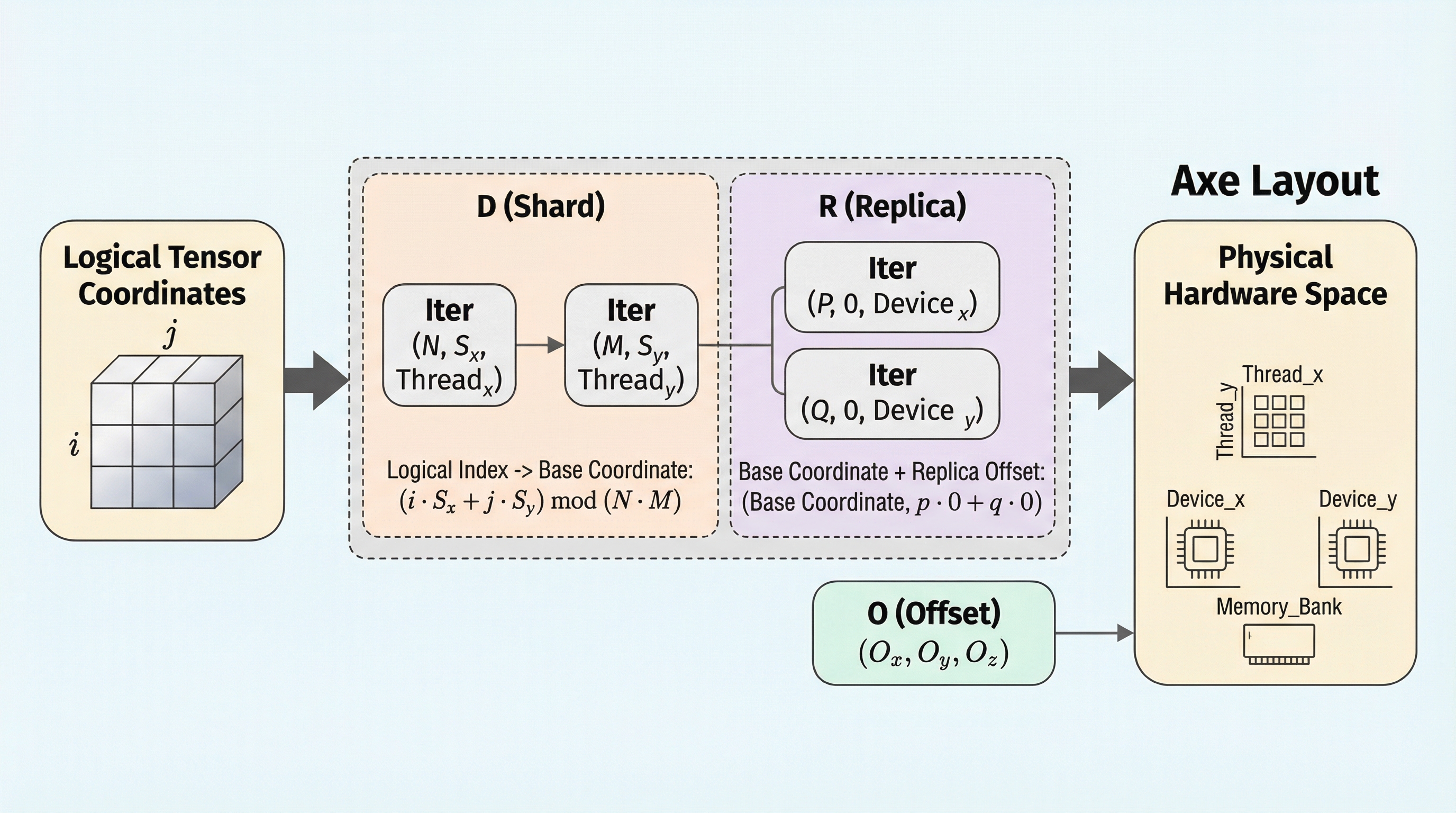
Axe:機械学習コンパイラのためのシンプルで統一されたレイアウト抽象化
現代の深層学習ワークロードのスケールアップに伴い、デバイスメッシュやメモリ階層、異種アクセラレータ間でのデータと計算の調整が不可欠となっていますが、本論文は論理的なテンソル座標を「名前付き軸」を介して多軸物理空間にマッピングする、ハードウェアを意識した抽象化「Axe Layout」を提案しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現代の深層学習ワークロードのスケールアップに伴い、デバイスメッシュやメモリ階層、異種アクセラレータ間でのデータと計算の調整が不可欠となっていますが、本論文は論理的なテンソル座標を「名前付き軸」を介して多軸物理空間にマッピングする、ハードウェアを意識した抽象化「Axe Layout」を提案しています。
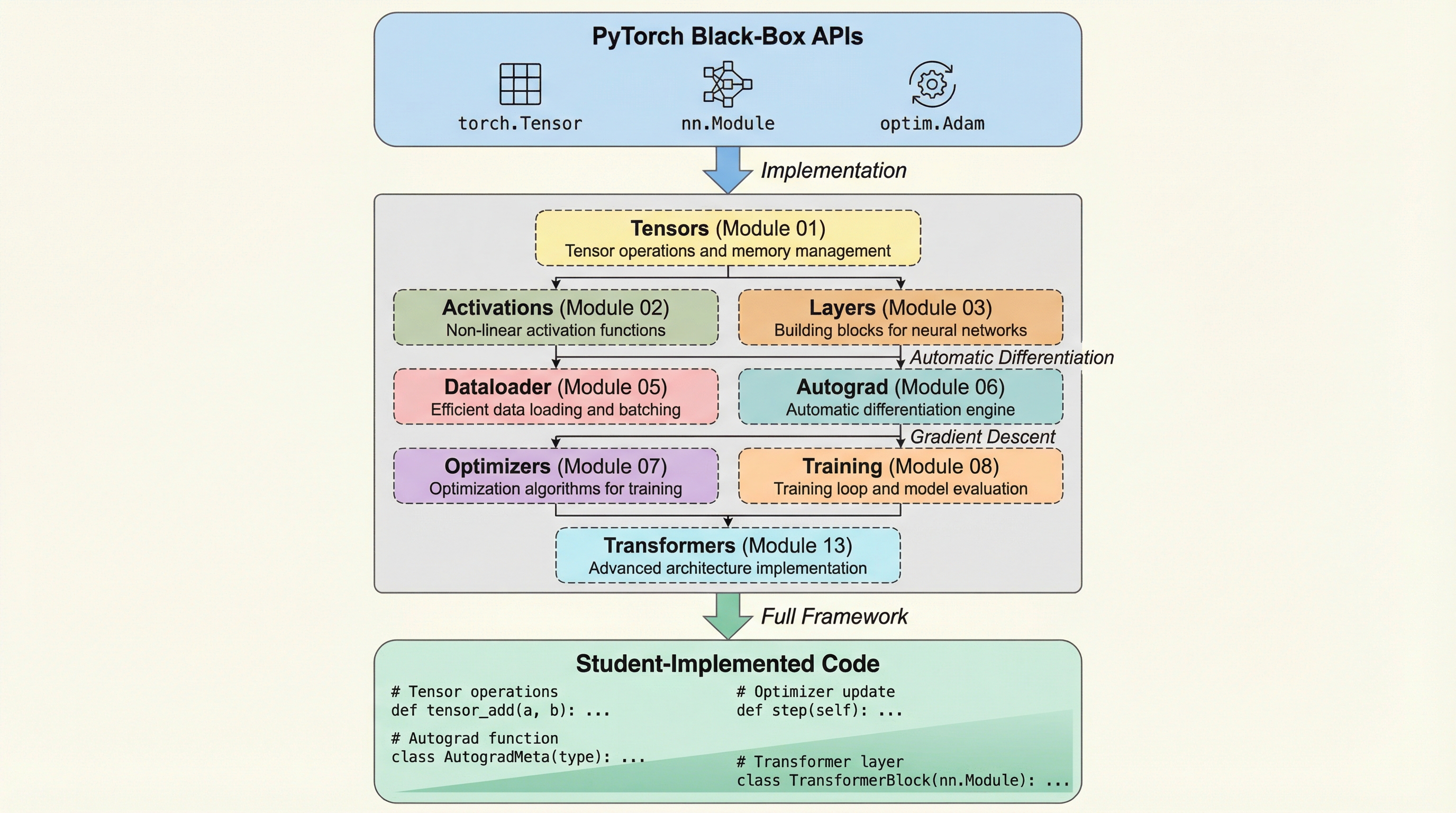
機械学習教育におけるアルゴリズム理論とシステム実行の深刻な乖離を解消するため、20のモジュールで構成される教育カリキュラム「TinyTorch」が提案されました。学生は純粋なPythonのみを用いて、テンソル演算、自動微分、オプティマイザ、トランスフォーマーといったPyTorch互換のコンポーネントをゼロから構築し、全ての操作が自作コードで完結する透明性の高いフレームワークを完成させます。この「構築による検証」アプローチにより、4GBのRAMという最小限のハードウェア環境で、メモリ効率や計算の複雑性、デプロイ時のトレードオフを深く理解する、産業界が求める機械学習システムエンジニアの育成を目指しています。
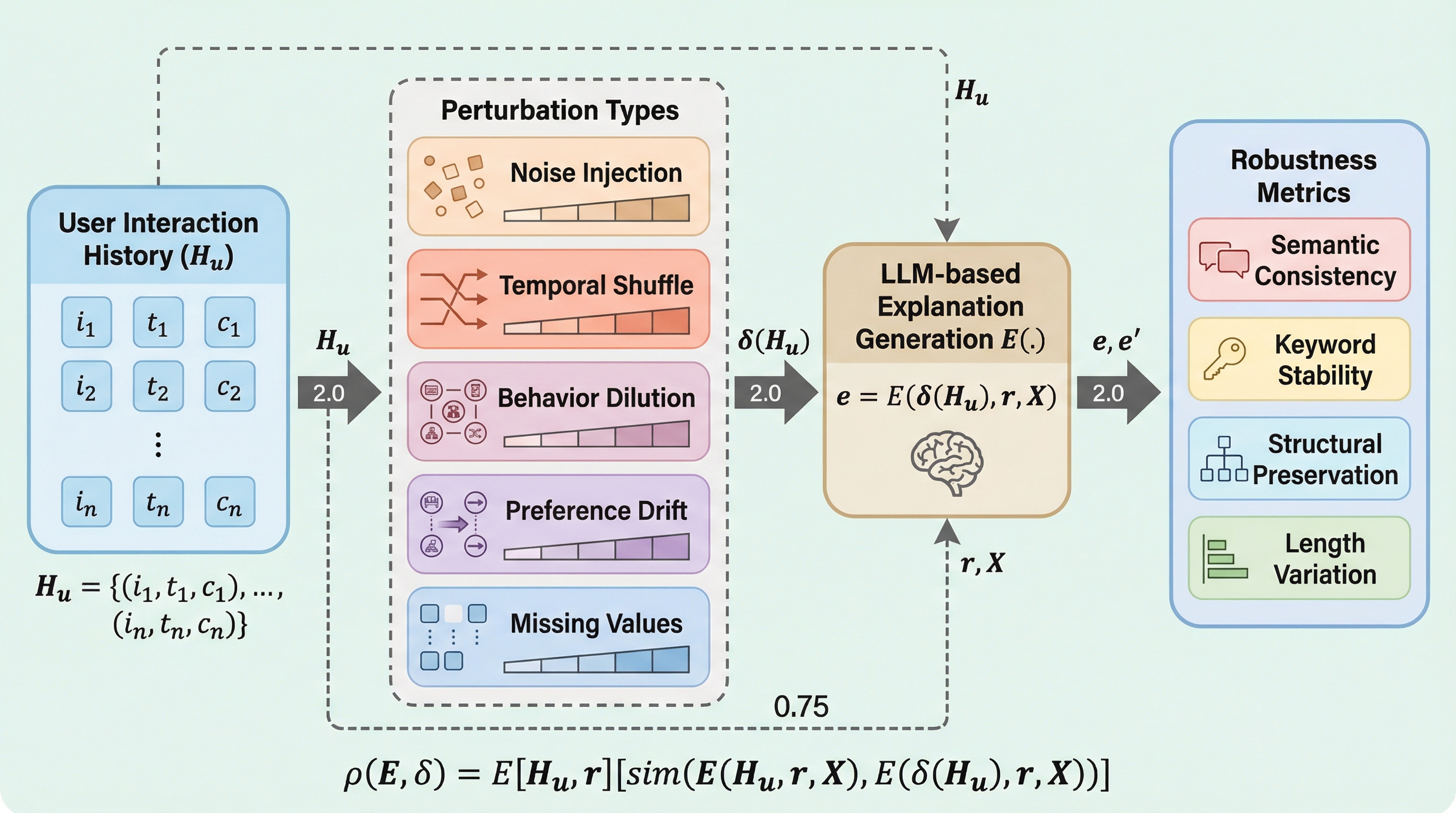
推薦システムにおいてLLMを用いた説明エージェントは、ユーザーの行動履歴から自然言語で推薦理由を生成するが、誤クリックやデータの欠落といった現実的なノイズに対する堅牢性はこれまで十分に検証されていなかった。
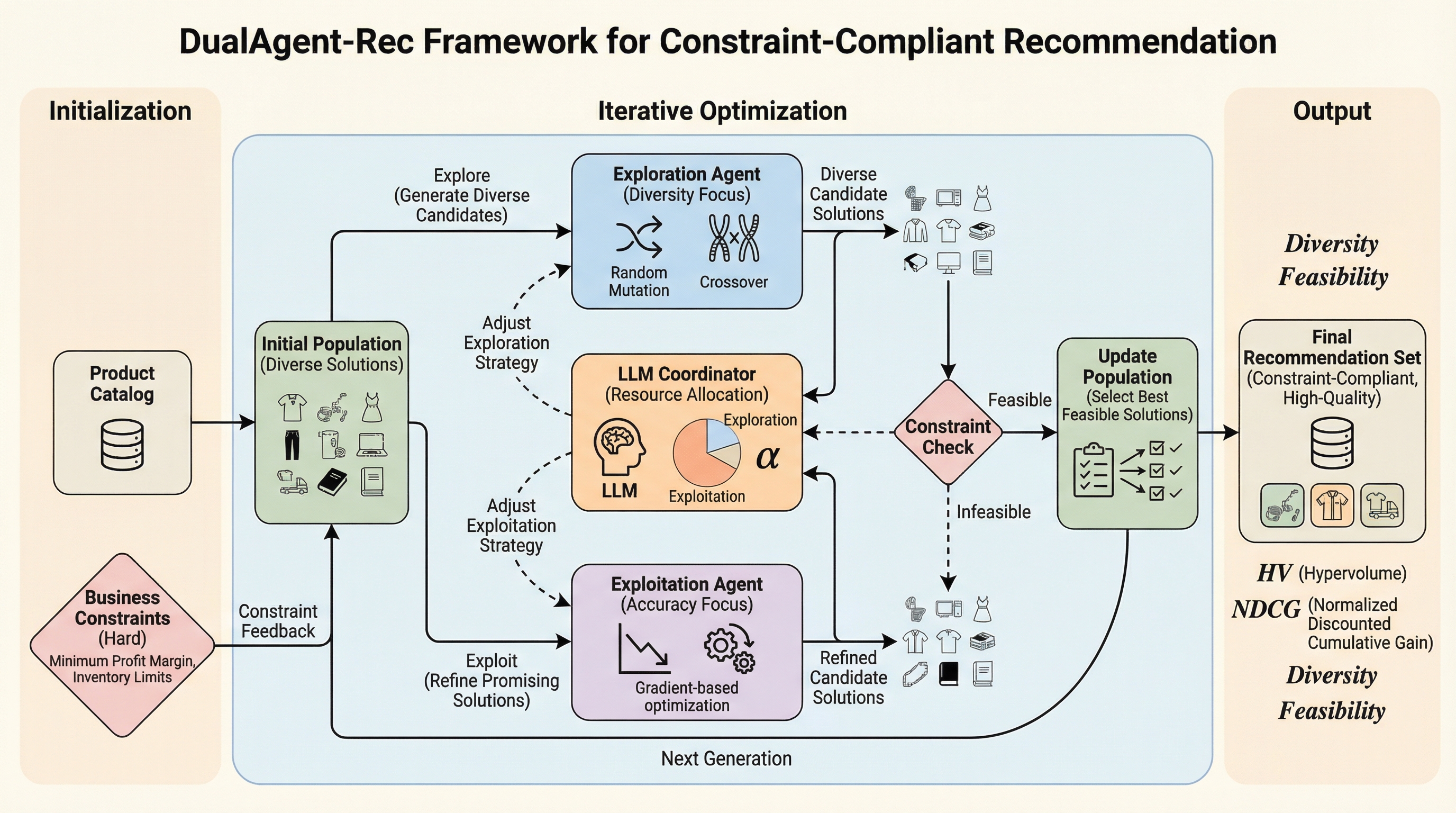
DualAgent-Recは、LLMを高度なオーケストレーターとして活用し、推薦精度と多様性の最適化、および公平性や出品者カバレッジといった厳しいビジネス制約の完全な遵守を両立させる新しいマルチエージェント・フレームワークです。
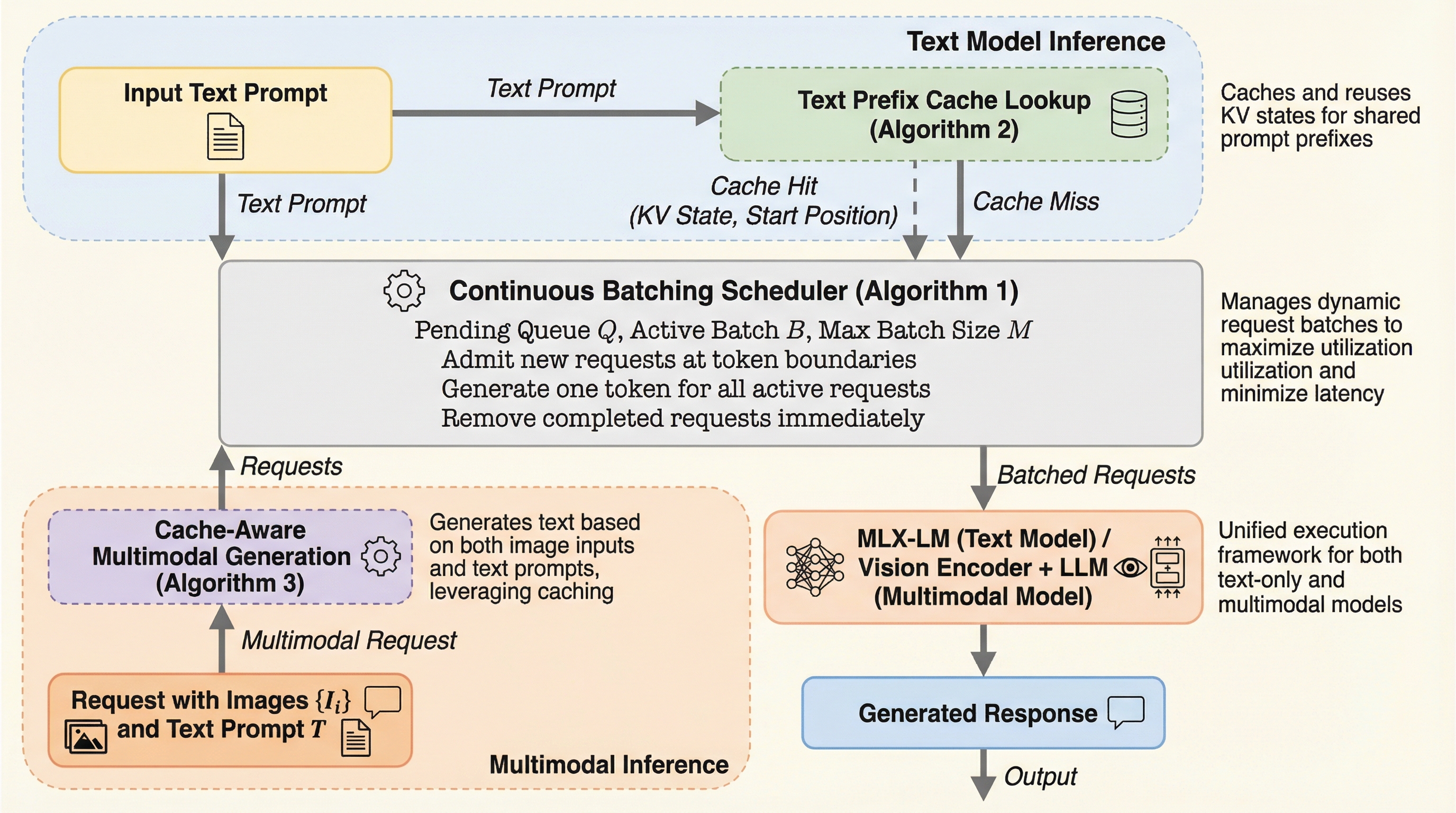
vllm-mlxは、Apple Siliconのユニファイドメモリ構造を最大限に活用するためにMLX上でネイティブに構築された、LLMおよびマルチモーダルLLM(MLLM)のための高効率な推論フレームワークである。継続的バッチ処理の導入により、従来のllama.
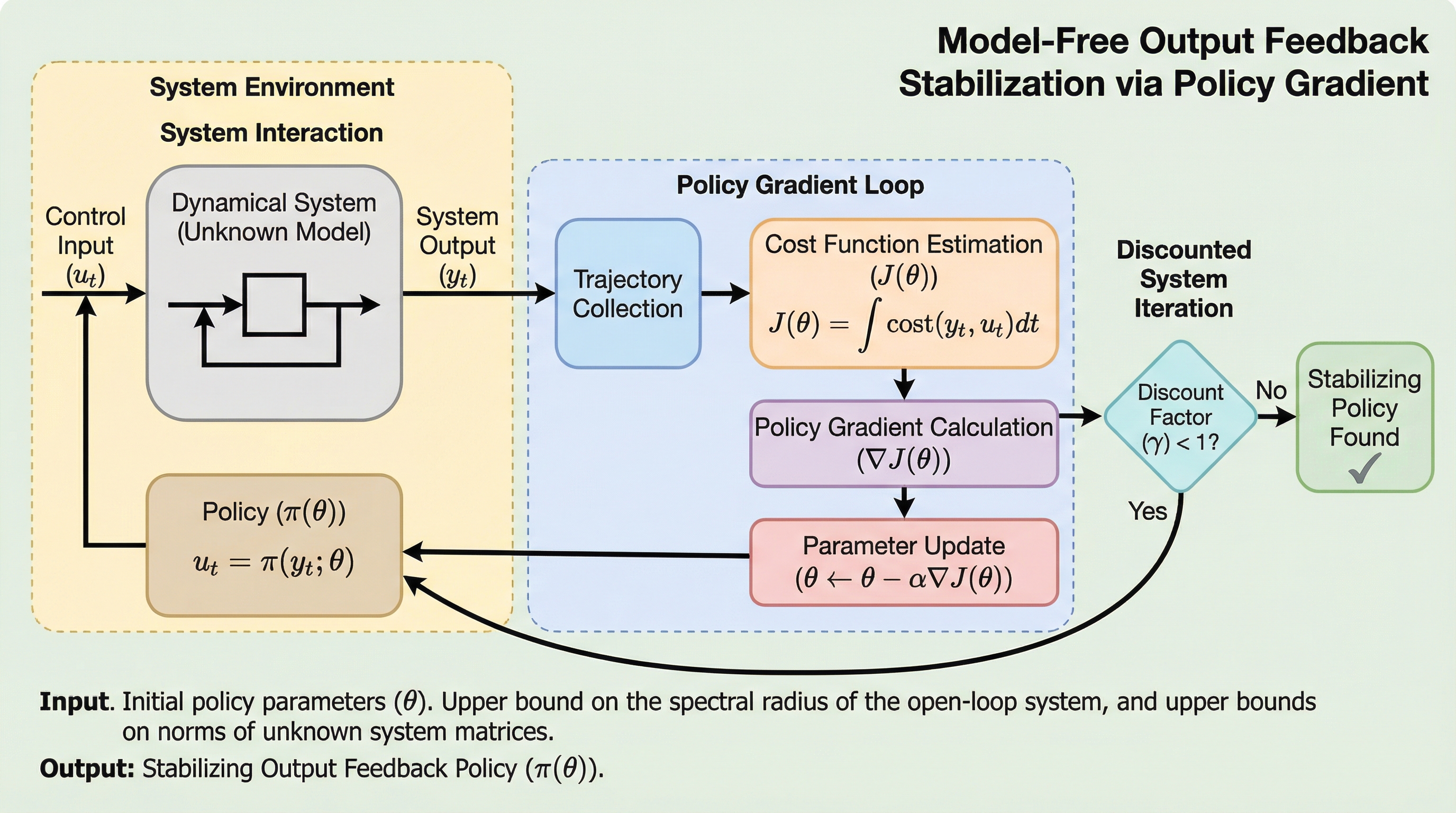
本研究は、システムモデルが未知で一部の出力しか観測できない離散時間線形システムにおいて、方策勾配法を用いてシステムを安定化させる静的出力フィードバック制御器を直接学習する新しいアルゴリズム枠組みを提案しました。
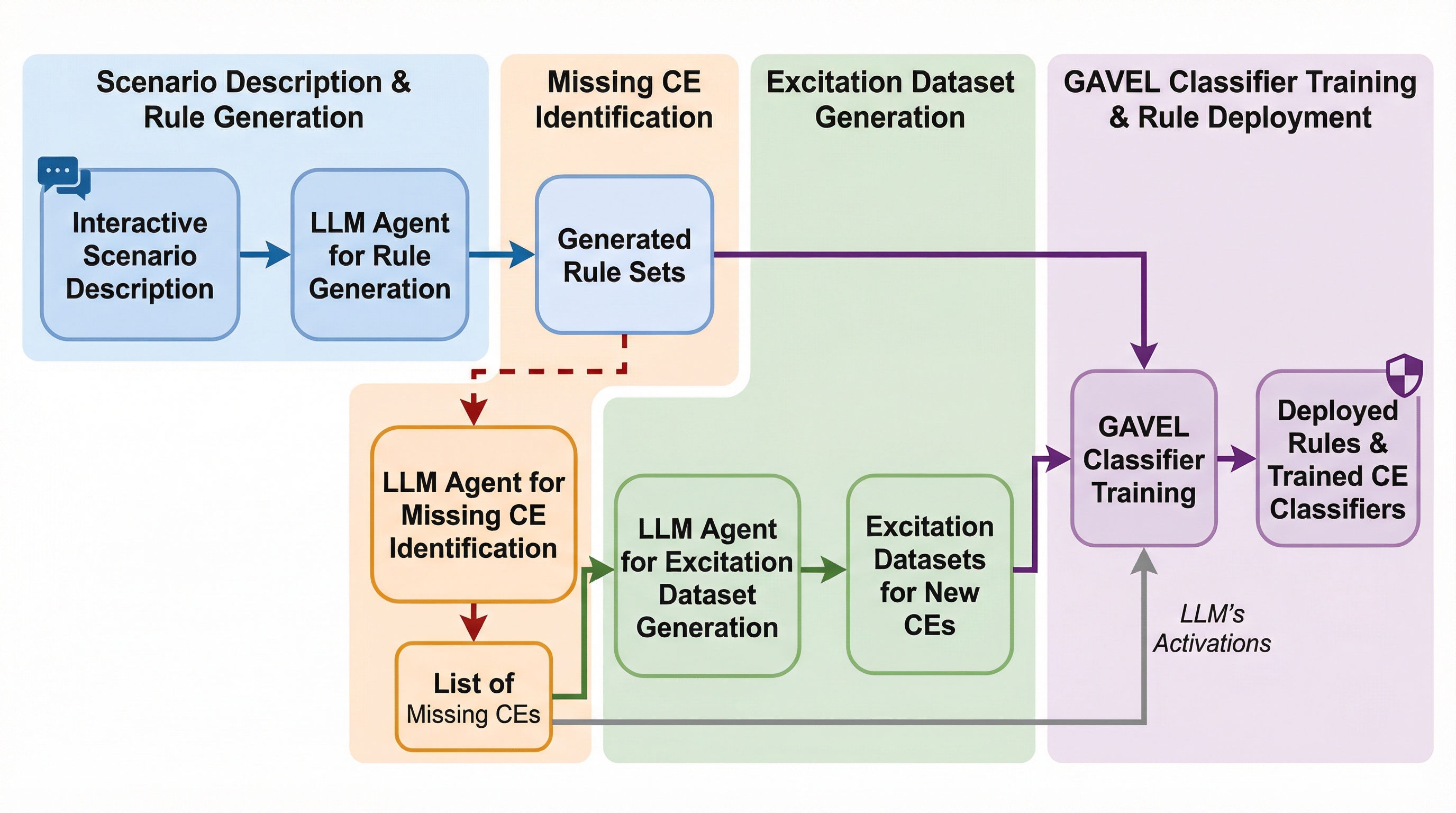
従来のLLMセーフティ技術は、表面的なテキストの監視では回避されやすく、内部のアクティベーションを利用する手法も広範なデータセットに依存するため精度や柔軟性、解釈性に課題がありました。本論文は、サイバーセキュリティのルール共有慣行に触発された「GAVEL」という新しいフレームワークを提案し、モデル内部の微細で解釈可能な要素である「認知要素(CE)」を定義して論理的なルールで監視する手法を導入しました。このアプローチにより、モデルの再学習を行うことなく、特定のドメインに合わせた高度な安全策をリアルタイムで構成・更新することが可能になり、AIガバナンスにおける透明性と監査の容易さを大幅に向上させています。
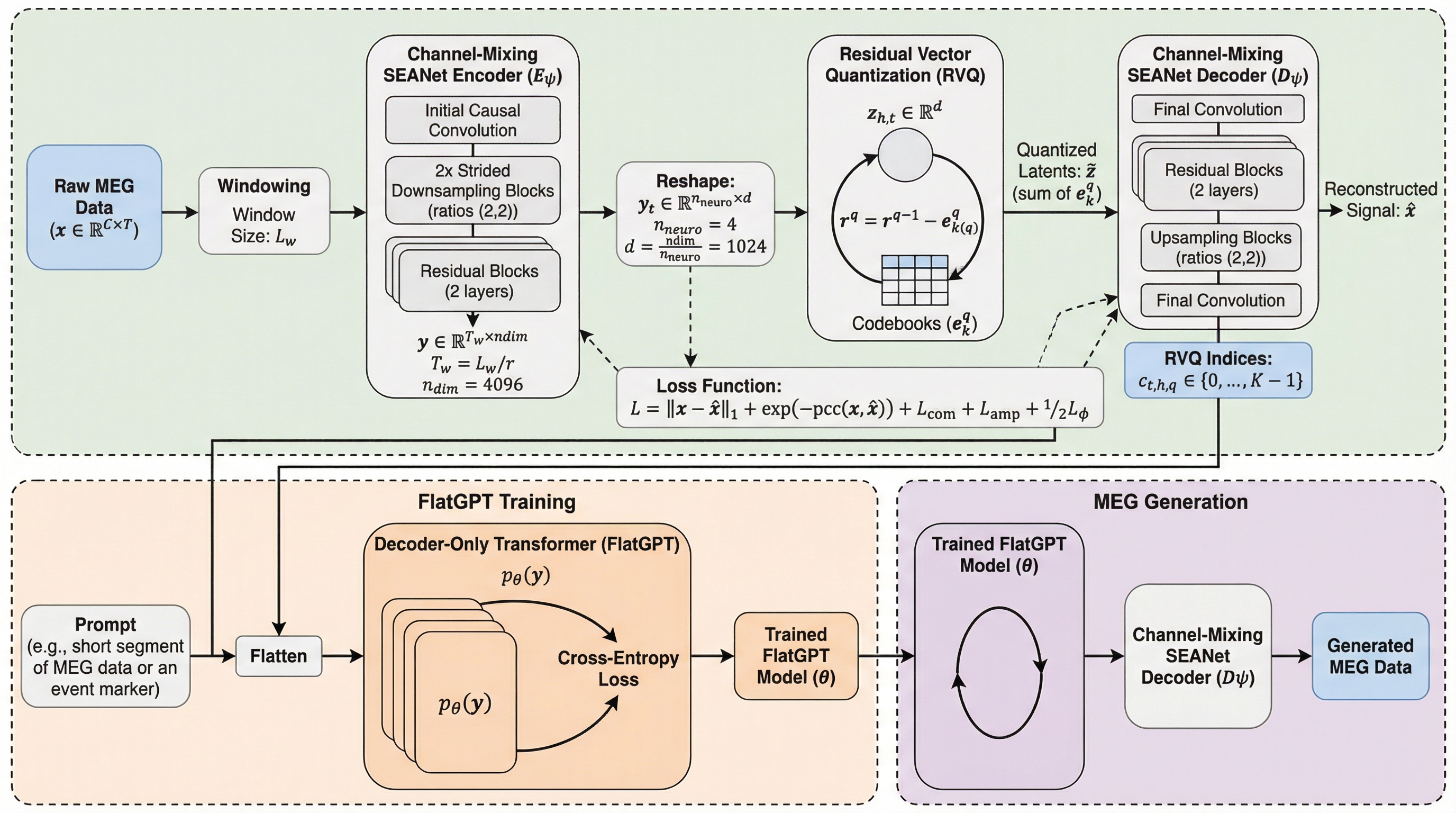
本研究では、500時間以上の大規模なMEG(磁気脳鳴図)データセットであるCamCAN、Omega、MOUSを統合し、多チャネルの脳信号を離散的なトークン列として予測する大規模自己回帰モデル「FlatGPT」を構築した。
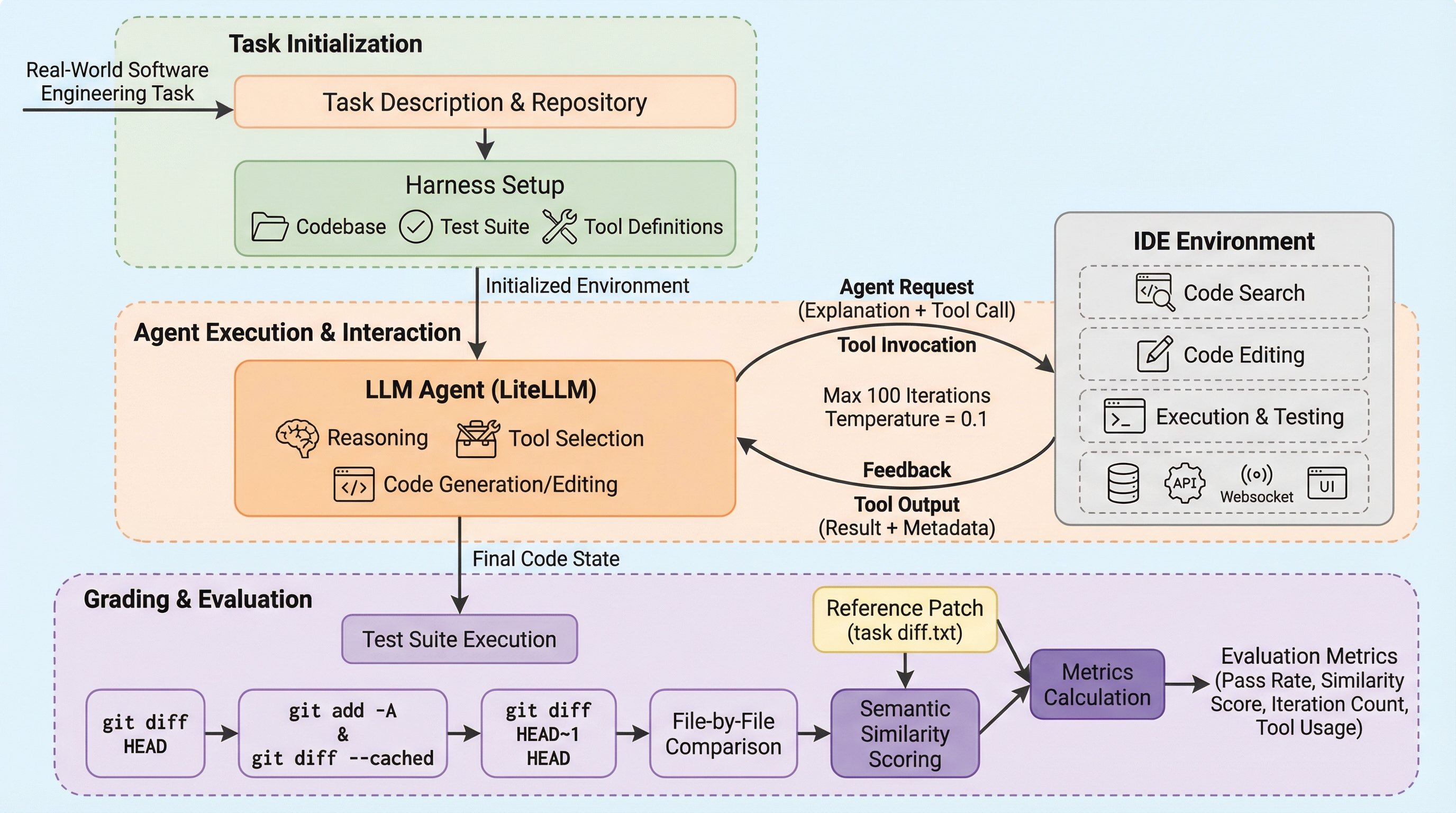
IDE-Benchは、CursorやWindsurfのようなAIネイティブIDEの動作を模した、LLMを「IDEエージェント」として評価するための新しいベンチマークフレームワークである。 学習データへの汚染を防ぐために作成された未公開の8つのリポジトリ(C/C++、Java、MERNスタック等)と80のタスクを用い、コード検索や編集、テスト実行といった17種類のツールを駆使した多段階の課題解決能力を厳密に測定する。 評価の結果、GPT 5.2が95%の成功率(pass@5)で首位となったが、多くのモデルで「アルゴリズムは正しいが形式や端的なケースで失敗する」という課題や、言語・フレームワークごとの得意不得意が顕著に現れた。
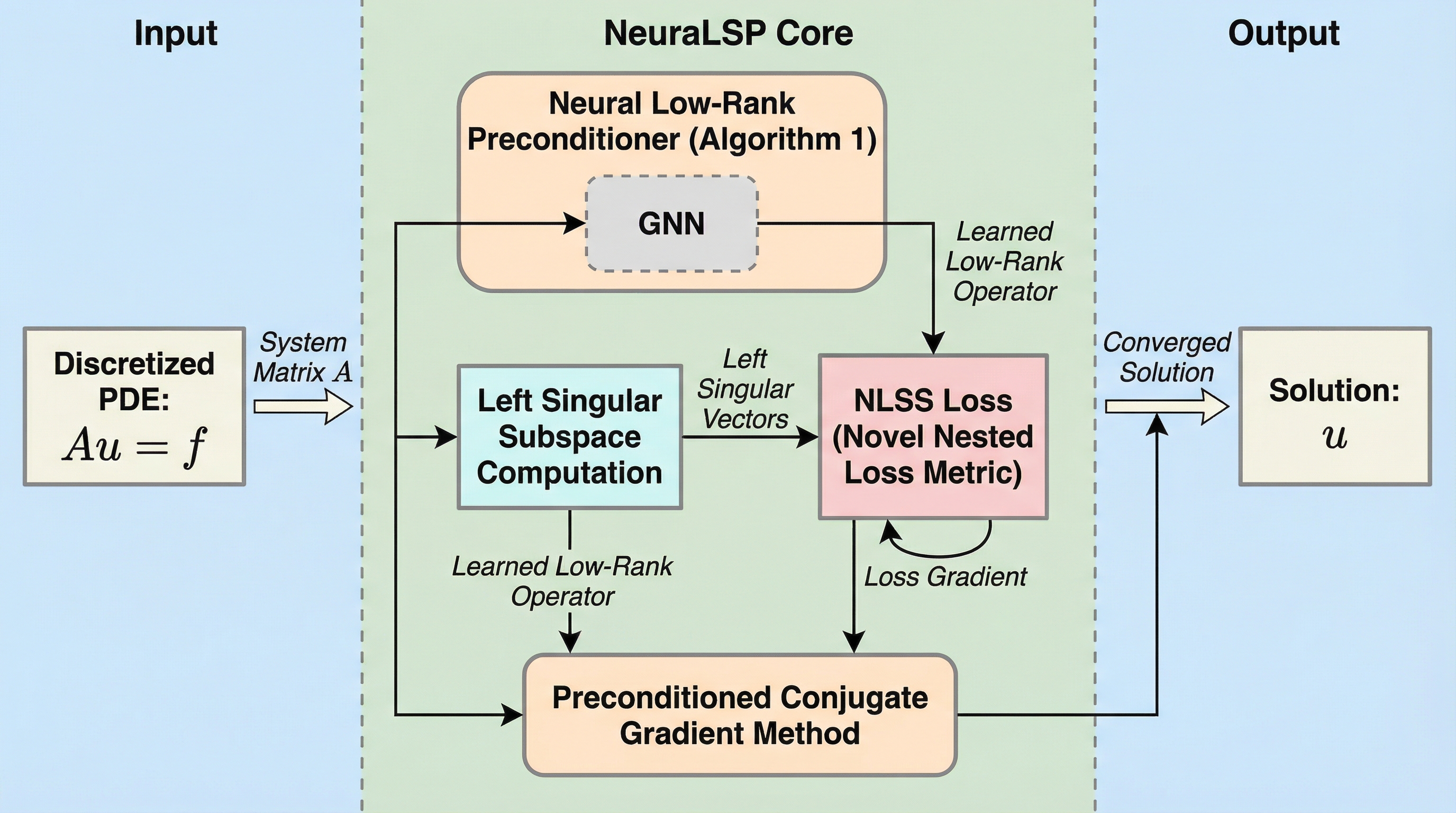
科学技術計算における偏微分方程式の数値解法を加速するため、従来の代数マルチグリッド法が抱えるランク膨張や収束率低下という課題を解決する新しいニューラルプリコンディショナ「NeuraLSP」が提案されました。