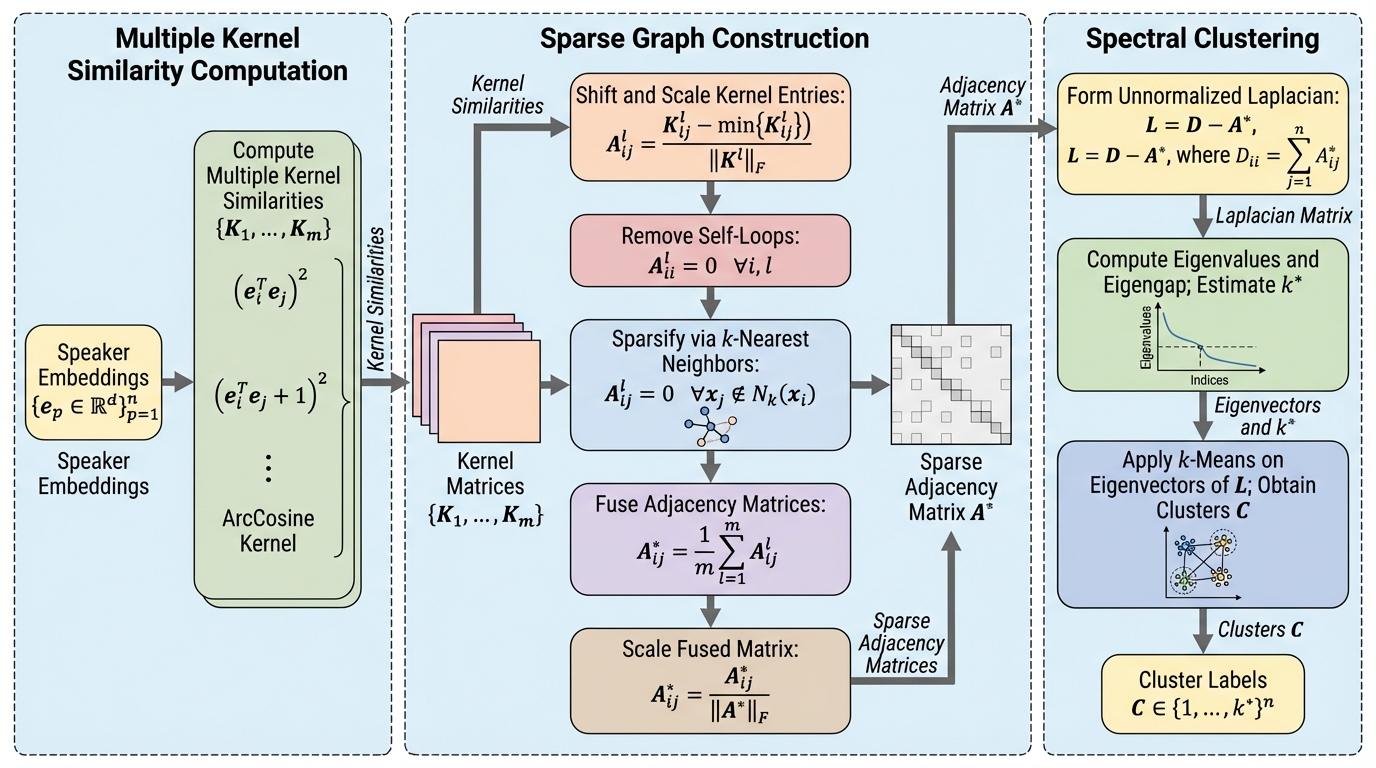
MK-SGC-SC:教師なし話者ダイアリゼーションのためのスペクトラルクラスタリングにおける複数カーネル誘導スパースグラフ構築
MK-SGC-SCは、4つの多項式カーネルと1つのアークコサインカーネルを統合し、話者埋め込み間の類似性を多角的に評価することで、事前学習や外部の教師情報を一切必要としない完全な教師なし設定において最高水準のダイアリゼーション精度を達成する手法である。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
MK-SGC-SCは、4つの多項式カーネルと1つのアークコサインカーネルを統合し、話者埋め込み間の類似性を多角的に評価することで、事前学習や外部の教師情報を一切必要としない完全な教師なし設定において最高水準のダイアリゼーション精度を達成する手法である。
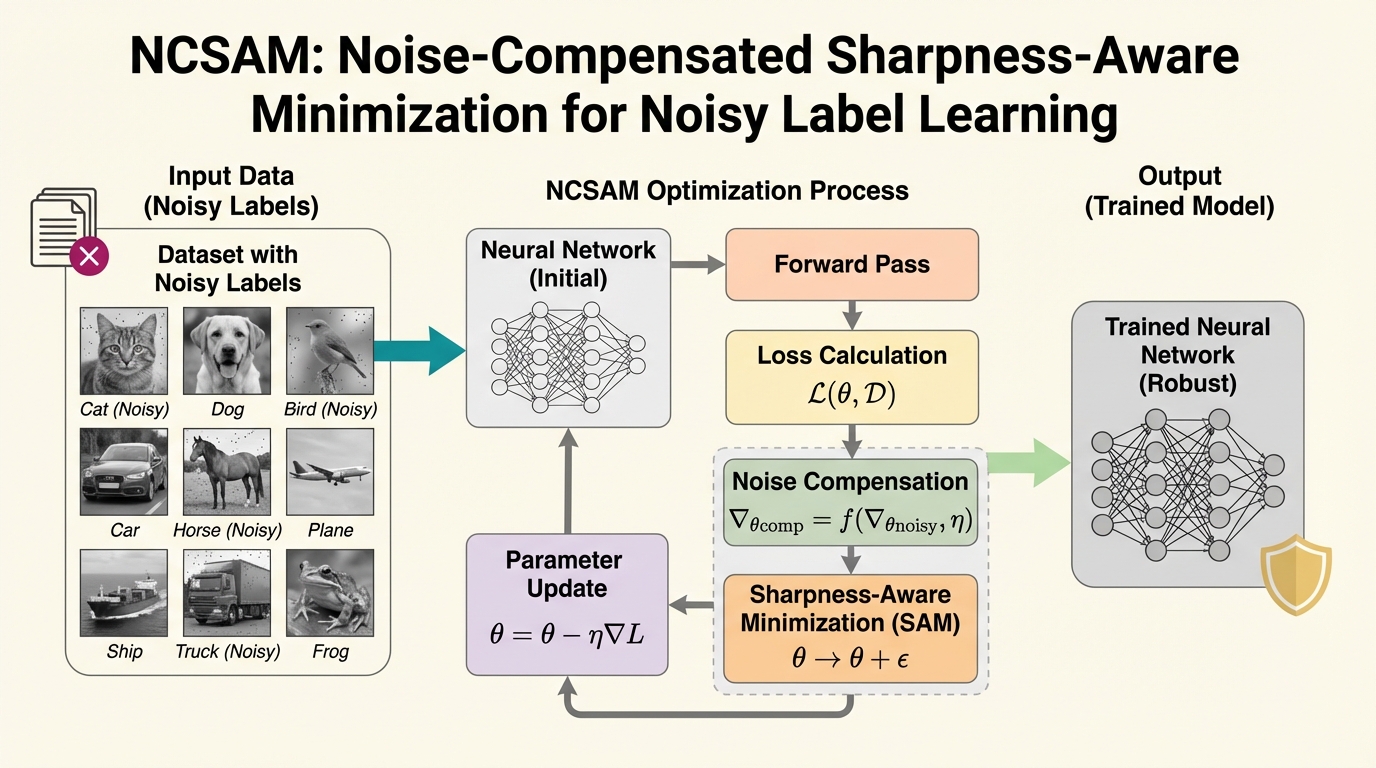
ウェブから収集されたデータ等に含まれる誤ったラベル(ノイズ)は、深層学習モデルに偏った勾配を導入し、汎化性能を著しく低下させるという深刻な課題があります。 本研究は、損失関数の平坦性とラベルノイズの関係を理論的に解析し、ノイズによる勾配の歪みが従来の平坦化手法(SAM)の摂動を狂わせることを解明した上で、その歪みを明示的に補正する新手法NCSAMを提案しました。 NCSAMは、モデルの予測自信度に基づきノイズをシミュレートしてパラメータの偏差を相殺することで、複雑なラベル修正なしに、クリーンなデータセットでの学習に近い高い堅牢性と汎化性能を達成しました。
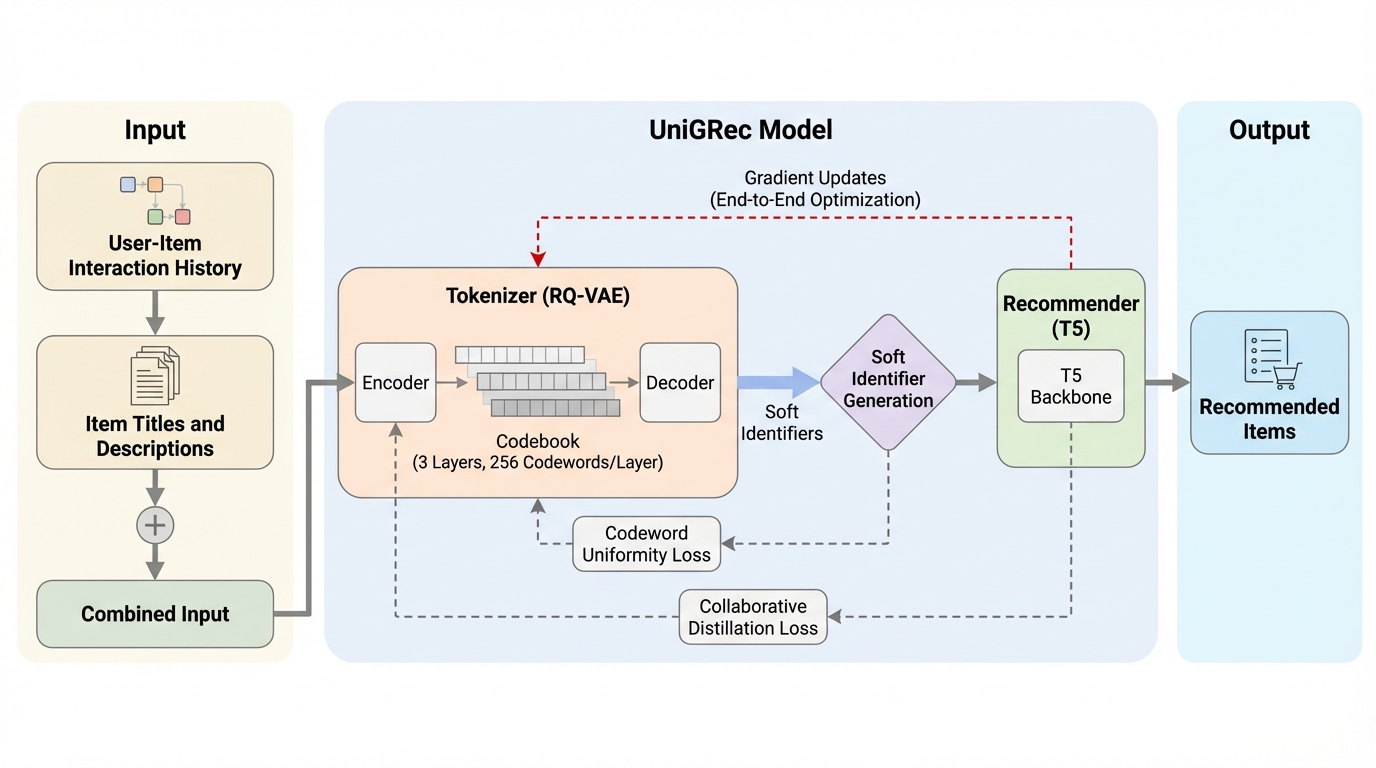
生成型推薦において、従来のトークナイザーと推薦モデルを個別に最適化する手法に対し、微分可能な「ソフト識別子」を導入することで、両者を単一の推薦目的関数でエンドツーエンドに同時最適化する新フレームワーク「UniGRec」が提案された。
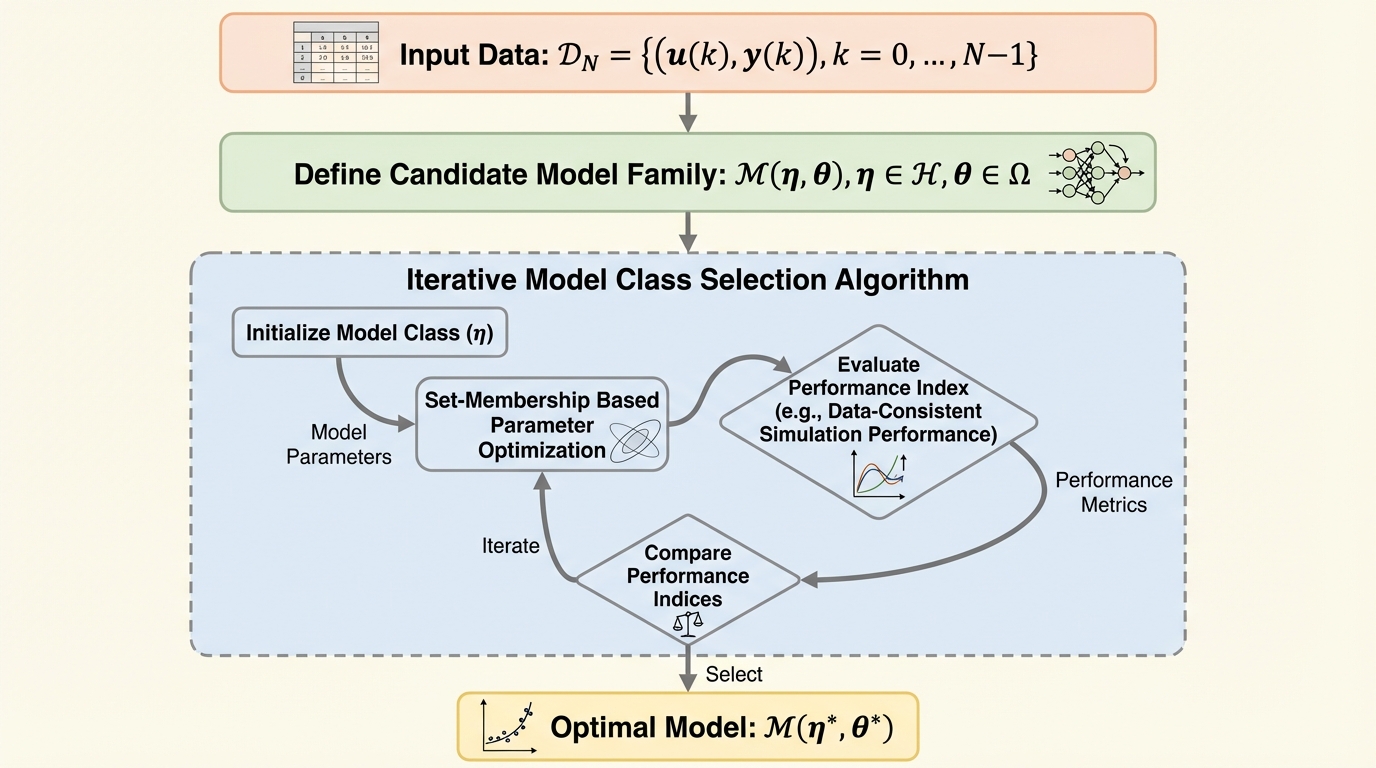
非線形動的システムの同定において、モデル構造の選択とパラメータ学習を同時に実行する、セットメンバーシップ(SM)法に基づいた新しい統合的アプローチが提案された。この手法は、特に自己回帰成分を持つニューラルモデルにおいて、データの不確実性を考慮しながら最適なモデルクラスを特定し、制御に適した簡潔なモデルを構築することを目的としている。 具体的な対象として、外生入力を伴う非線形自己回帰エコーステートネットワーク(NARXESN)を採用し、有界な測定ノイズを明示的に扱うことで、過学習を防ぎつつシステムの動的な振る舞いをロバストに捉える。これにより、従来は計算負荷が高かった自己回帰モデルの性能評価を、データ一貫性のある指標を用いて効率的に行うことが可能になった。 提案されたフレームワークは、セット距離(set-distance)という新しい性能指標とヒューリスティックな探索手順を組み合わせることで、複雑な非線形システムの同定プロセスを自動化している。結果として、計算コストを抑えながら、実世界のアプリケーションで要求される精度とモデルの簡潔さを両立させる信頼性の高い動的モデルの生成を実現している。
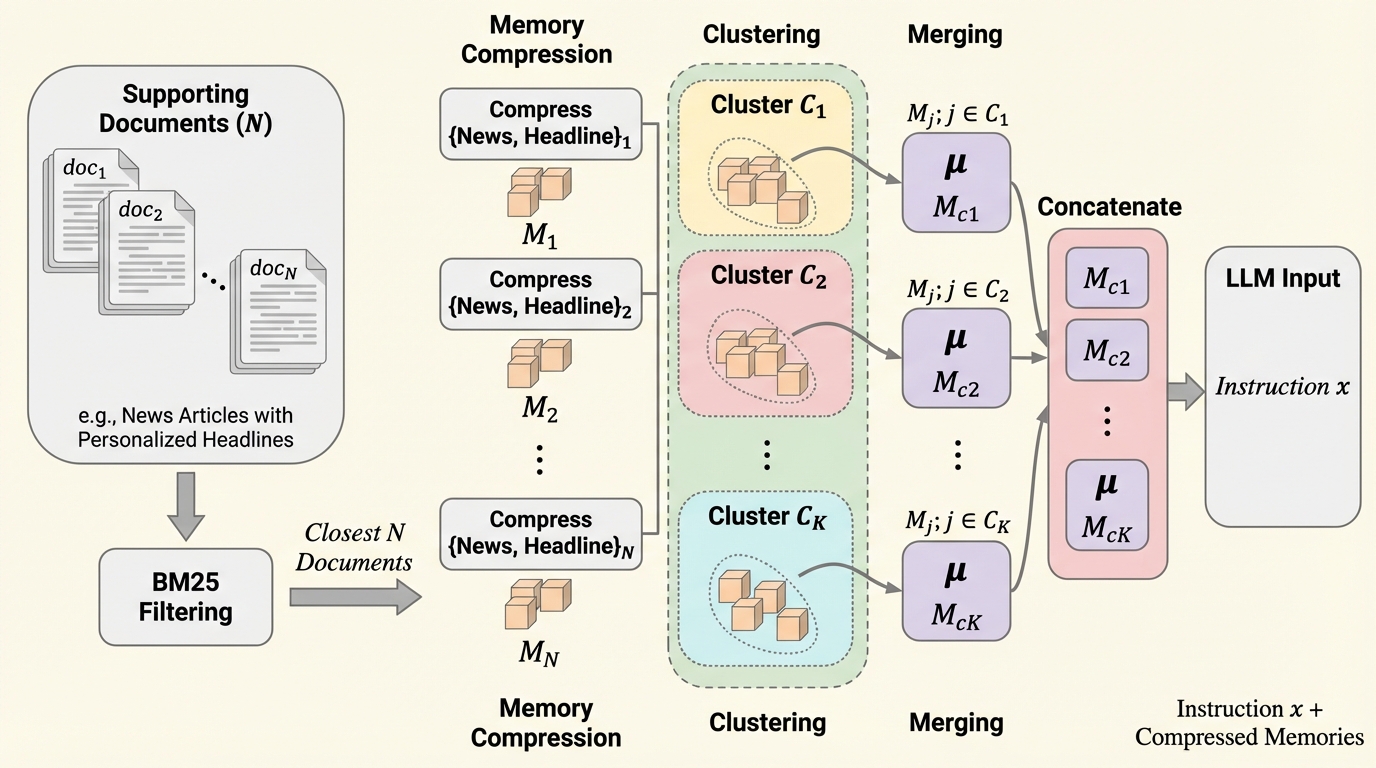
スマートフォンなどのオンデバイス環境で動作する大規模言語モデル(LLM)において、限られたコンテキスト窓を有効活用しながらユーザーの過去の対話履歴をパーソナライズに利用するための、新しいクラスタリング駆動型メモリ圧縮手法が提案されました。
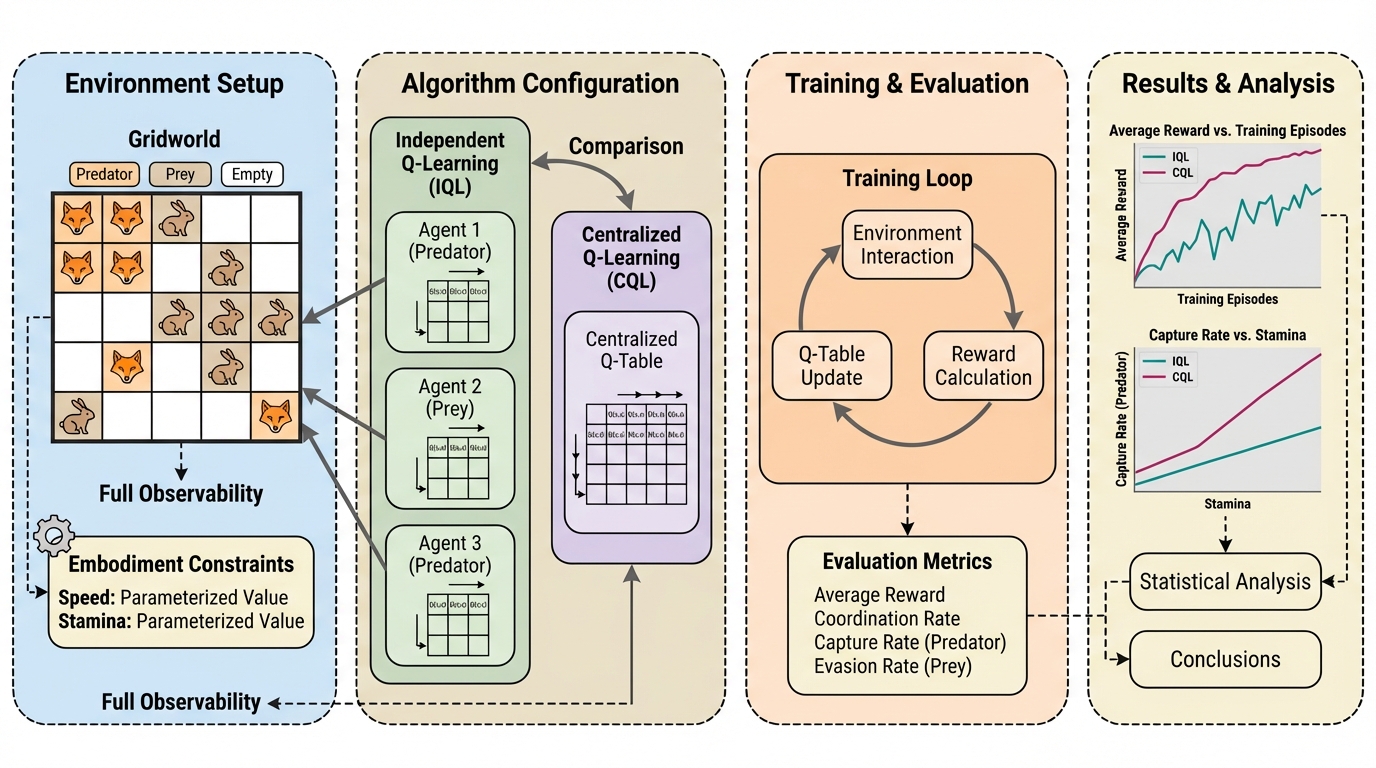
マルチエージェント強化学習において、中央集中型の学習は協調性と安定性を向上させる標準的な手法とされてきましたが、本研究は表形式の捕食者・被食者環境を用いた厳密な検証により、この定説が物理的制約下では必ずしも成立しないことを明らかにしました。
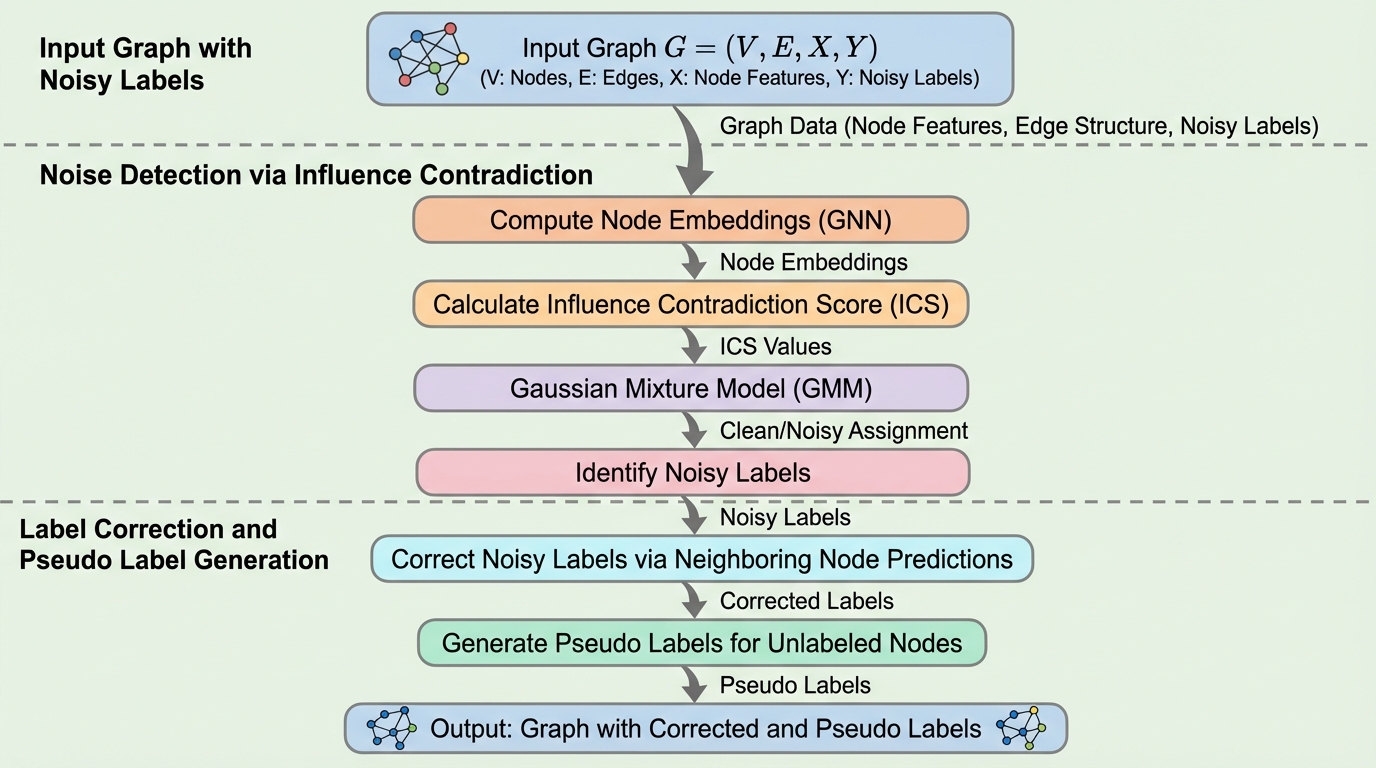
グラフニューラルネットワーク(GNN)は社会分析や生物情報学などの多様な分野で活用されているが、現実のデータには注釈ミスや不整合に起因するラベルノイズが含まれることが多く、これがモデルの堅牢性と汎用性を著しく低下させるという課題がある。
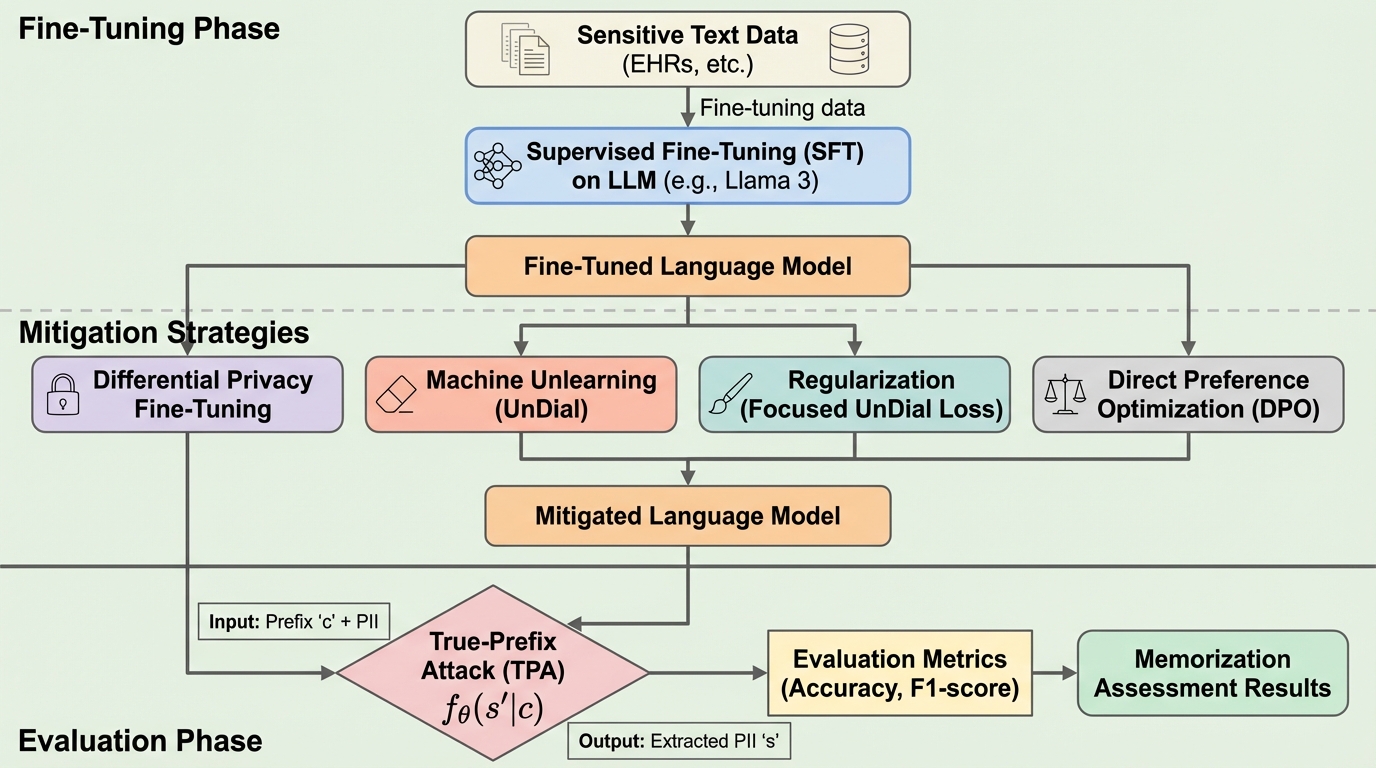
大規模言語モデル(LLM)を特定のデータセットで微調整する際、学習の目的(ターゲット)には含まれず、入力データにのみ存在する個人識別情報(PII)が意図せず記憶され、外部からの攻撃によって抽出可能になるリスクを、合成データと実世界の医療データを用いて体系的に明らかにした。
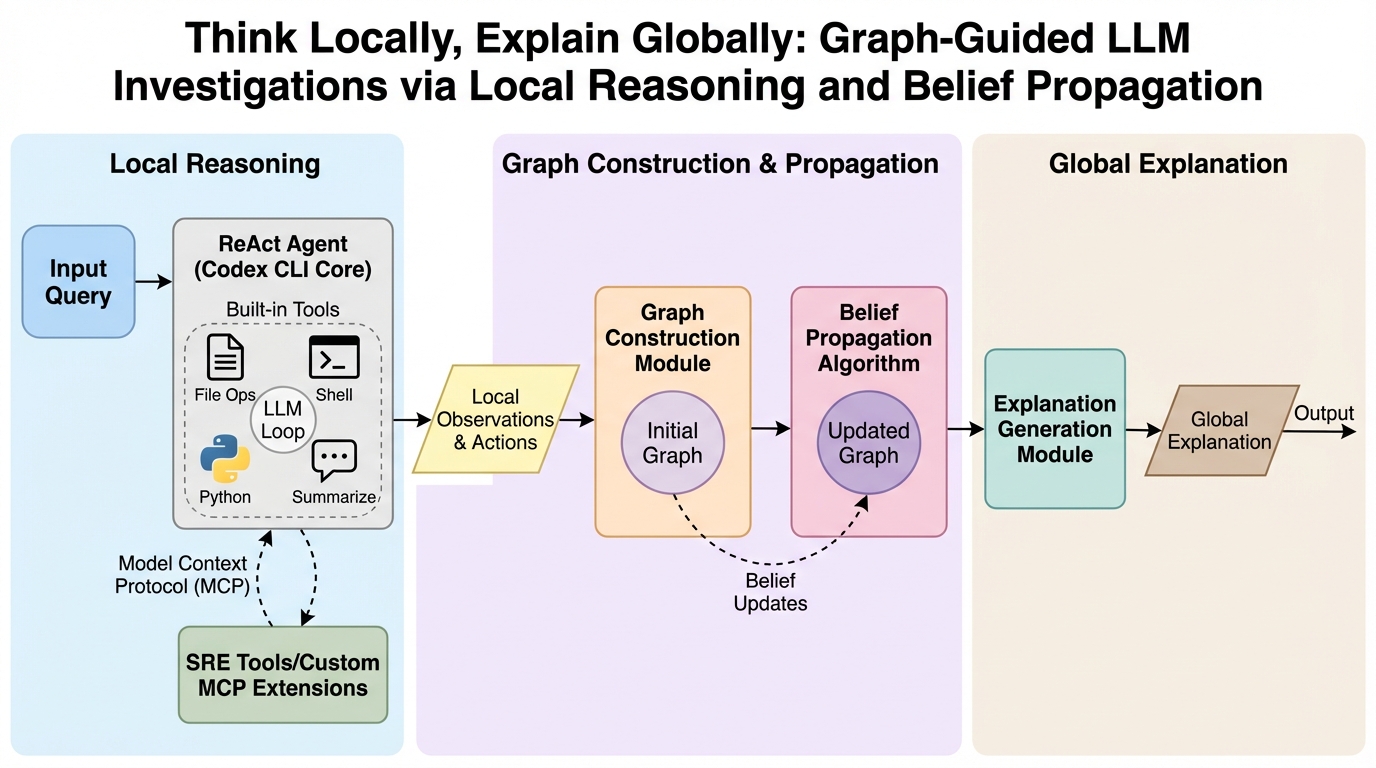
Think Locally, Explain Globally: 局所的推論と信念伝播によるグラフ誘導型LLM調査フレームワーク「EoG」の提案
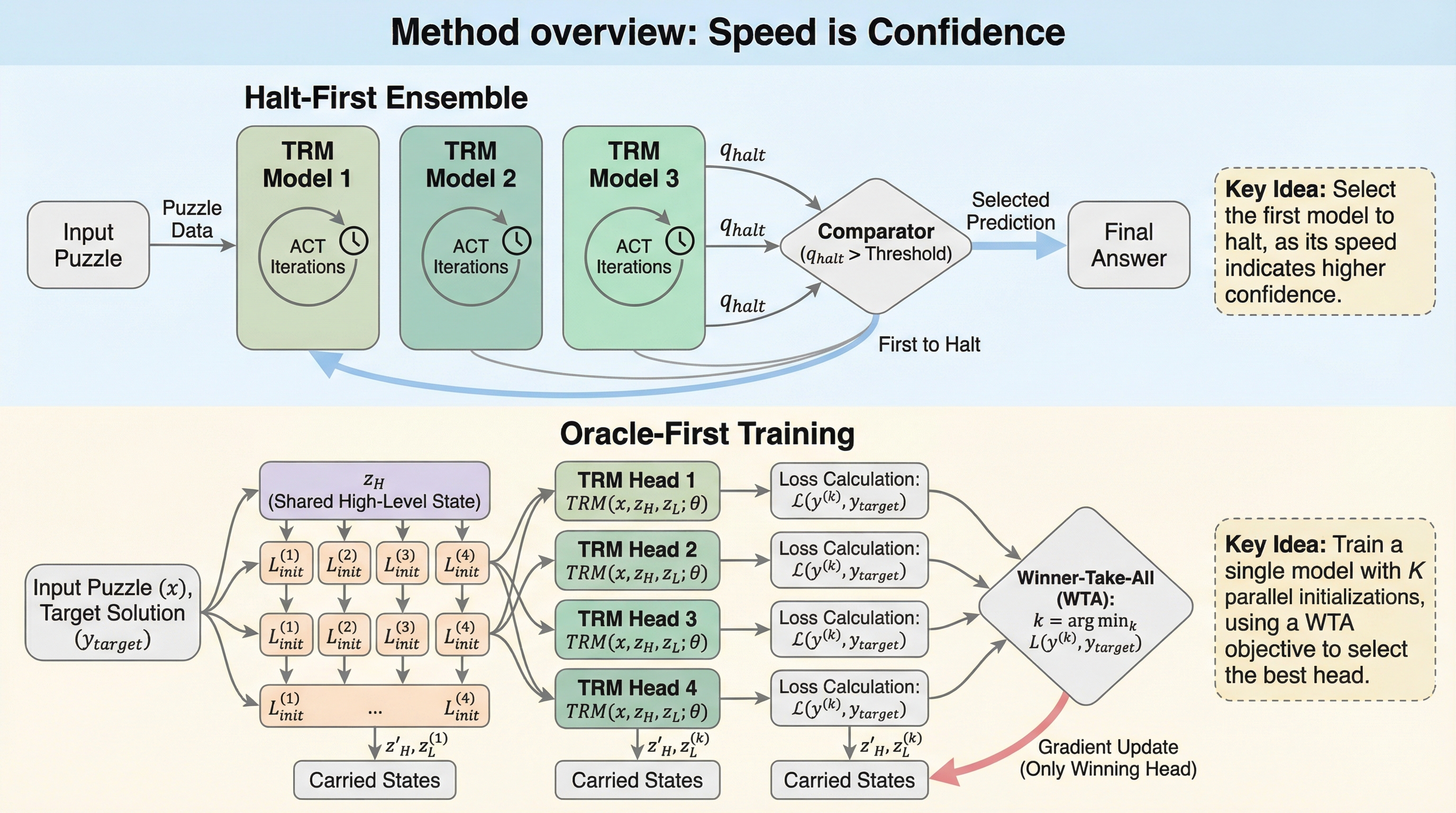
生物学的な神経系がエネルギー制約下で「最初の信号」に基づいて行動することに着想を得て、反復推論モデル(TRM)において推論速度を自信の指標として扱う手法を提案した。アンサンブル手法において、予測値を平均化するのではなく、最も早く停止信号を出したモデルの回答を採用する「halt-first」選択により、計算量を10分の1に削減しつつ、Sudoku-Extremeでの正解率を91.5%から97.2%へと大幅に向上させた。 この特性を単一モデルに内蔵するため、訓練時に4つの並列な潜在状態を維持し、最も損失が低い「勝者」のみを誤差逆伝播させる「Winner-Take-All(WTA)」学習を導入した。これにより、推論時の計算コストを増やすことなく、従来のテスト時拡張(TTA)に匹敵する96.9%の精度を達成し、ベースラインモデルの86.1%を大きく上回る結果を得た。 消費者向けハードウェアであるRTX 5090単体での実験を可能にするため、Muon最適化手法と改良型SwiGLUを組み合わせ、学習の高速化と安定化を実現した。推論速度が平衡状態の条件の良さを反映するという理論的解釈を示し、反復型モデルにおける「速さは自信である」という直感を数学的に裏付けた。